使用langchain和文心API打造知识库问答-01文本向量化
大模型开发/技术交流
- LLM
- 社区上线
- 开箱评测
2023.09.132584看过
1、前言
我们先来看一下打造一个知识库问答应用的整体技术原理图:
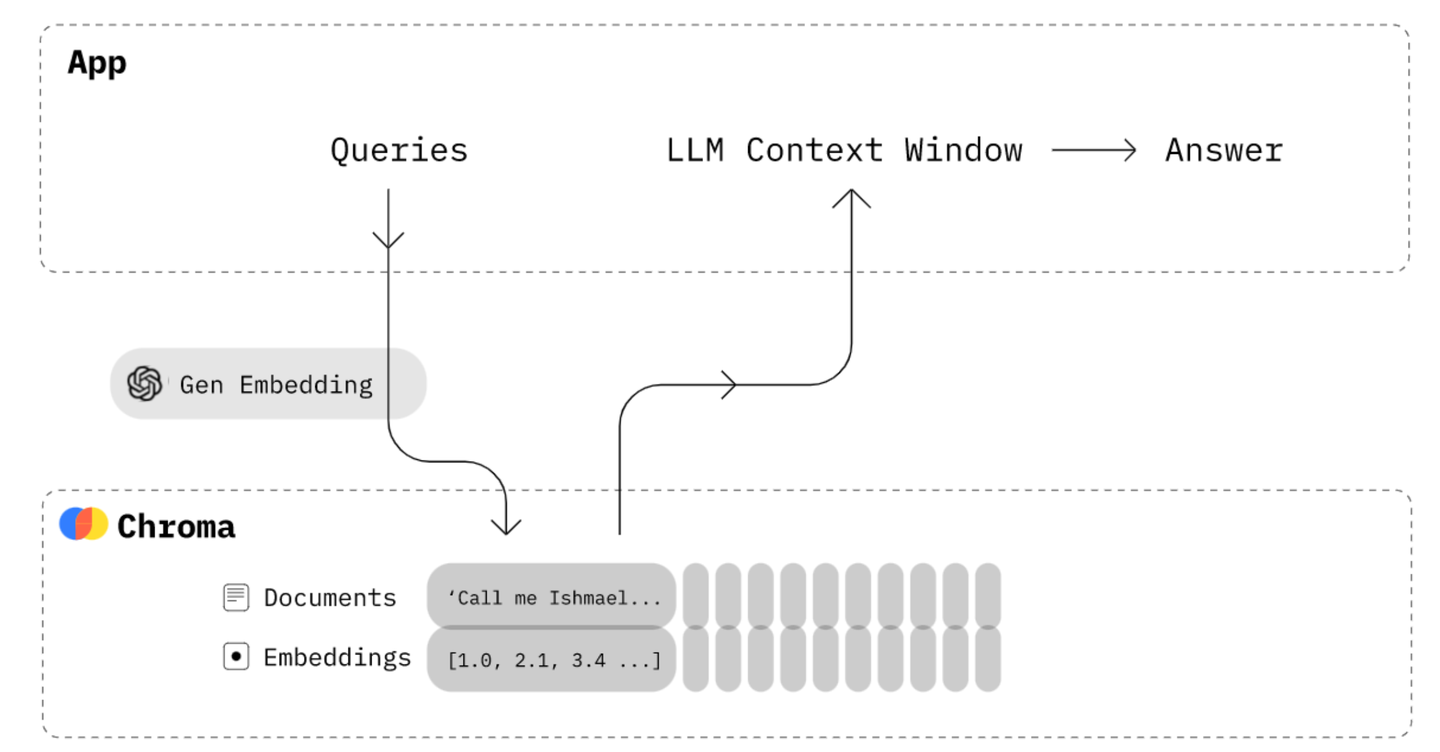
通过上图我们可以知道,打造一个知识库问答应用,主要有两部分(虚线框中的):知识库的问答和文本的向量化;我们今天先介绍文本的向量化。
2、什么是文本向量化
那么什么文本的向量化?或者说为什么要文本向量化?
简单点说就是计算机是不认识人类语言的,但是计算机认识数字,文本的向量化就是将文本进行数字化表示,这里数字一般指的是浮点数(float)。
例子:我们把“我喜欢小狗”这句话进行向量化,得到的就是类似[0.123, 0.231, 0.321……]这样一个浮点数的数组。
这里我们问一下文心一言这个问题,看她是怎么回答的。
3、准备工作
3.1、申请key和secret
首先到百度千帆平台<https://cloud.baidu.com/>申请API Key 和 Secret Key。
3.2、安装第三方python库
pip install langchain
注:langchain中大语言模型现在已经集成了文心一言的API
4、向量化测试
我们直接上代码:
from langchain.embeddings.ernie import ErnieEmbeddingsWENXIN_APP_Key = "APP KEY"WENXIN_APP_SECRET = "APP SECRET"# 实例化文心的ErnieEmbeddingsembedding = ErnieEmbeddings(ernie_client_id = WENXIN_APP_Key,ernie_client_secret = WENXIN_APP_SECRET)# 需要向量化的文本texts = ['我喜欢小狗','我喜欢小动物','我今天心情很糟糕']
进行向量化:
embedding0 = embedding.embed_query(texts[0])print(embedding0)
会打印出一个长度是384的float64的数组,说明详见<https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu>
[0.14588040113449097, -0.005717064719647169, -0.009185394272208214,……]
embedding1 = embedding.embed_query(texts[1])print(embedding1)embedding2 = embedding.embed_query(texts[2])print(embedding2)# 打印内容此处跟上面类似,此处省略
5、小结
通过上面简单介绍和代码,我们知道了什么是文本向量化,同时使用文心一言的向量化API,对文本进行了向量化。那么向量化后的浮点数组怎么来使用呢?简单来说就是计算两个文本的相似度转化为计算两个文本的向量(vector)的距离(distance),得到距离值越小,则两个文本越相似;反之距离值越大,则两个文本的越不相似,这就是我们要打造知识库问答的原理。
延伸:既然文本能够向量化,那是不是图片,音频,视频等,也可以向量化?答案是肯定的。这也就是说通过对图片向量化,搜索跟这个图片相似的其他图片。喜欢的小伙伴记得点赞!
评论
