SFT调优之旅(一)
大模型开发/技术交流
- 社区上线
- 开箱评测
- SFT
2023.09.155348看过
SFT调优之旅先从代码生成任务开始,使用了开源的leetcode数据集,听说代码任务有助于大模型能力的涌现~
目录
-
SFT概述
-
数据集的构建
-
开启SFT~
SFT概述
大模型SFT微调是一种针对预训练模型进行微调优化的方法,旨在提高模型在特定任务上的性能。期间会伴有模型泛化能力的提高,可以更好的处理之前没有见过的数据。
当然这些都是建立在微调时给定的数据集是准确,充足的情况,因此当你发现微调过后,模型似乎变蠢了,可能就有微调数据集的一些原因。
数据集的构建
-
千帆支持的数据集类型有三种:
-
-
文本对话:一问一答的形式
-
泛文本标注:用于
Post-training(后训练),这个与finetune不同,它是在预训练模型的基础上再进行预训练 -
query问题集:提问的语料,用于后续RLHF训练的输入
-
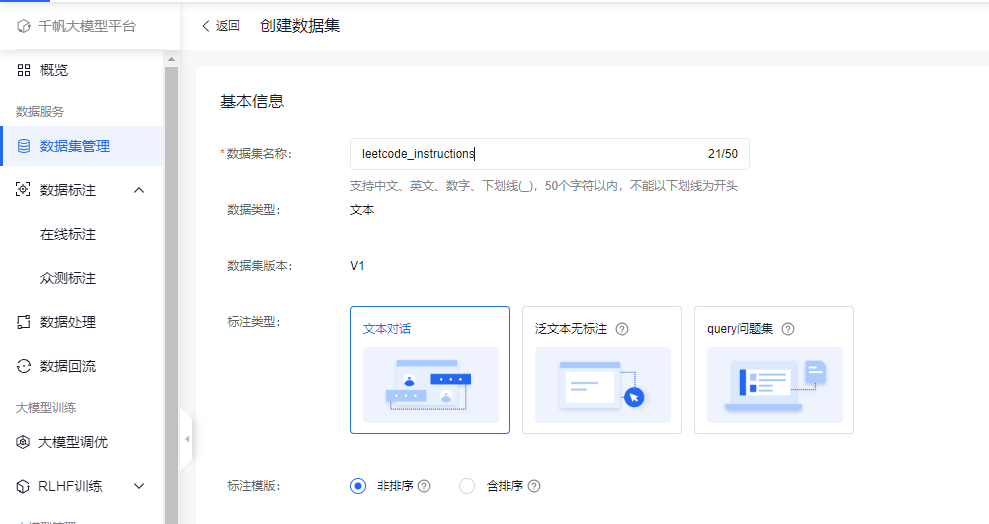
这里我们选择文本对话,SFT本来就是有监督的学习,当然要给出标签啦~~~我们的目的是想给出要解决的代码问题,让大模型生成代码,这也非常符合这种形式~
因此后面的展示都是在选定了文本对话的基础上
-
选定了数据集的格式,我们就创建并导入数据喽✔️
-
-
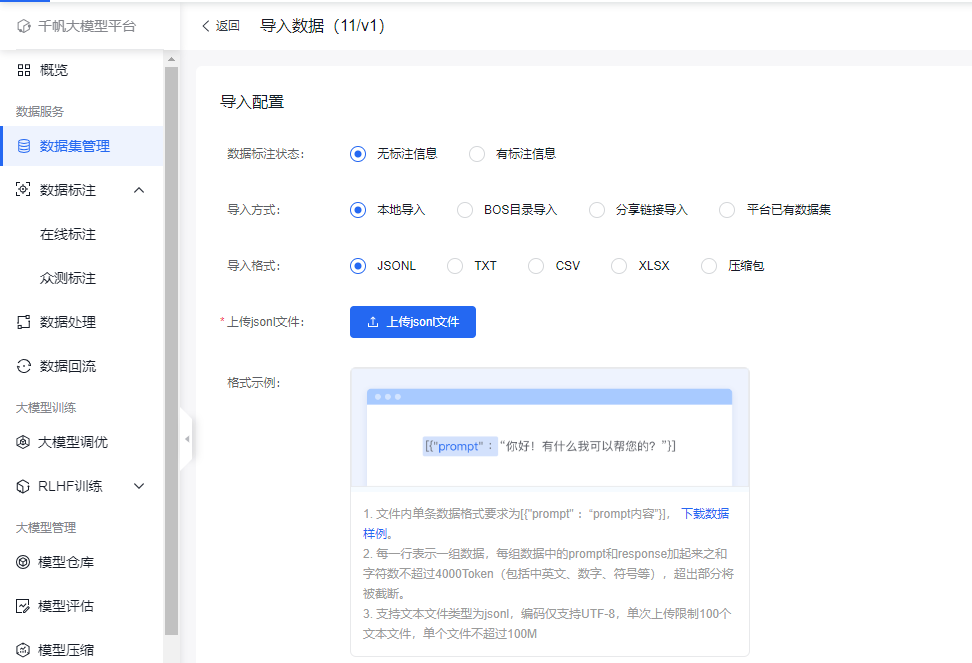
数据标注状态:是因为千帆平台支持在线标注呢~,我们可以先导入prompt,再在平台上标注。因为我使用了开源数据集,所以选择有标注信息的选项
-
导入方式,我选择了本地导入,当然这里也有其他方便的形式
-
导入格式,我选择了
jsonl格式,因为那个开源数据集就是这个文件格式🤣。虽然文件格式这样,但是我们需要遵守单条数据格式的要求,能否导入成功,就看它啦~ -
单条数据格式的要求:
-
[{"prompt":<prompt>,"response":[[<response>]]}]
-
-
查看
COIG中的单个数据格式,发现是{"instruction":<instruction>,"input":<input>,"output":output,'task_type'<task_type>,'program_lang':<program_lang>}
-

b. 使用代码转换成千帆平台支持的格式

c. 代码展示:
import jsonxyz = []with open('leetcode_instructions.jsonl','r',encoding='utf-8') as jfp:for line in jfp:data = json.loads(line.strip(" \n"))prompt = data["instruction"]+data["input"]responce = data["output"]result = [{"prompt":prompt,"response":[[responce]]}]xyz.append(result)with open('sft.jsonl','w',encoding='utf-8') as file:for item in xyz:json.dump(item,file,ensure_ascii=False)file.write('\n')
到此我们就构建和导入完成了我们进行SFT的数据集~
哈哈哈,那么我们就要进行SFT训练了吗???当然不是~,其实我们还需要进行许多数据后处理和检验等工作,偷懒的我,看到了一万多条数据,暂时也就没有进行那可能至关重要的工作
开始SFT~
运行 sft 任务,需要先进行创建一个调优任务,再新建运行
-
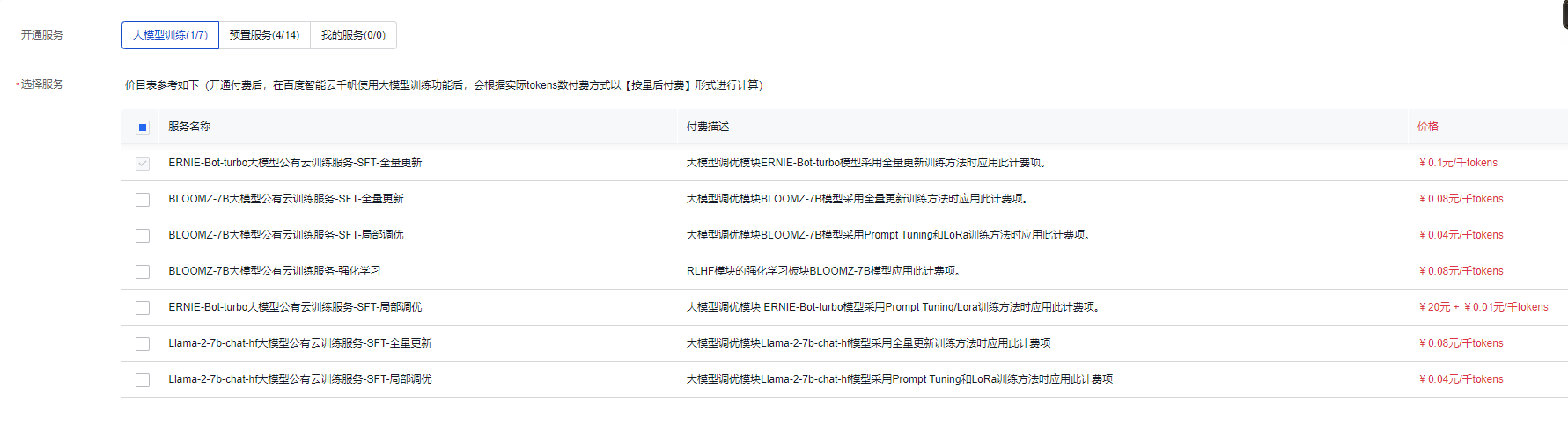
开通相应的训练服务,当然可以开通所有服务,因为是以按量后付费的形式,不使用相应的服务,是不需要付费的
-
其次我们需要选用自己的数据集(必须将数据集发布出来)
-
选择模型和服务,就开始训练了。
这么大的数据量进行SFT,需要的费用还是挺多的,因此这里没有进行真实的微调。也说明了对于个体开发者来说,优化prompt和使用工具链的方式,是比较推荐的。
评论
