为什么SFT后LLM模型的性能变得更好了?
大模型开发/技术交流
- SFT
- LLM
2023.10.017802看过
有监督微调(Supervised Fine Tuning,SFT)是一种常见的方法,用于改进预训练模型的性能。
这种方法的基本思想是利用标注的数据来调整模型的参数,使其更好地适应特定的任务。
SFT能提升性能吗?
根据一篇题为"Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity"的研究,有监督微调(Supervised Fine Tuning,SFT)可以显著提高模型的性能。这篇研究主要关注了大型预训练语言模型(如GPT-3)在少量训练样本(Few-Shot)下的性能。
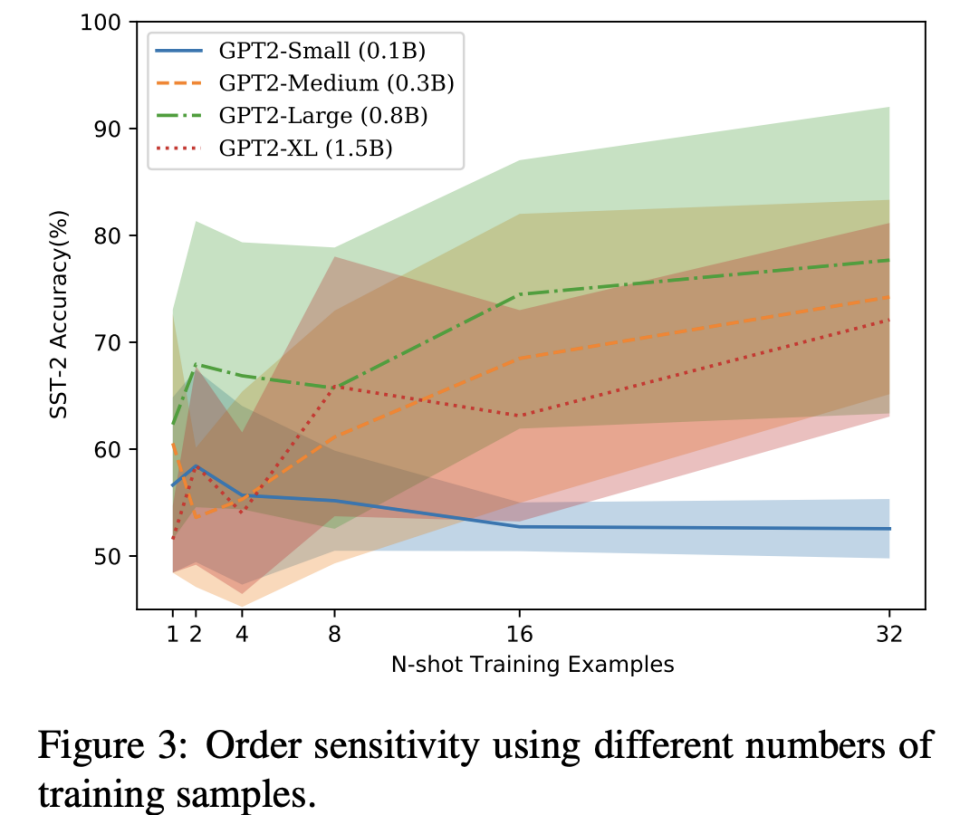
SFT为什么能提升性能?
SFT之所以能提升性能我觉得可以从迁移学习、数据分布、模型参数以及对齐的角度去分析。
-
任务特定的学习(迁移学习):通过SFT,模型从通用模型转为了特定任务相关的模式和规则。
实际上10B模型可以看作Pretrain模型(通用任务模型),而我们需要做扩写、续写和润色模型(专用任务模型)。
通过对这些特定任务的训练,模型可以更好地理解如何进行这些任务,从而提高其性能。
-
数据适应性(数据分布):SFT使模型能够适应新的、特定的数据。
我认为,10B模型数据的特征分布和我们并不一致。
10B模型用的数据分布和我们自己标注的200条数据分布是不一样的。通过在这200条数据上进行训练,模型可以更好地理解和处理我们这些数据,从而提高其在这些数据上的性能。
-
模型参数的微调(模型参数):通过SFT,模型的参数可以根据新的数据进行微调。这意味着模型可以根据新的数据调整其内部的权重和偏置,从而更好地适应这些数据。 这里是国哥已经提到的。
-
对齐问题(LLM模型与人类对齐):对齐问题主要涉及到如何将模型的输出与人类的期望和意图进行对齐。
-
通过SFT,我们可以在特定的数据上进行训练,从而使模型更好地对齐我们想让它续写、扩写、润色的意图。
-
预训练的语言模型(例如GPT-3)通常在大量的文本数据上进行训练,这些数据可能包含各种各样的主题和风格。然而,对于特定的任务(例如续写或润色),我们可能希望模型能够更好地对齐(或适应)特定的主题或风格。
-
-
对齐税:通过SFT,我们可以更好地调整过拟合和欠拟合的平衡,从而提高模型的性能。
-
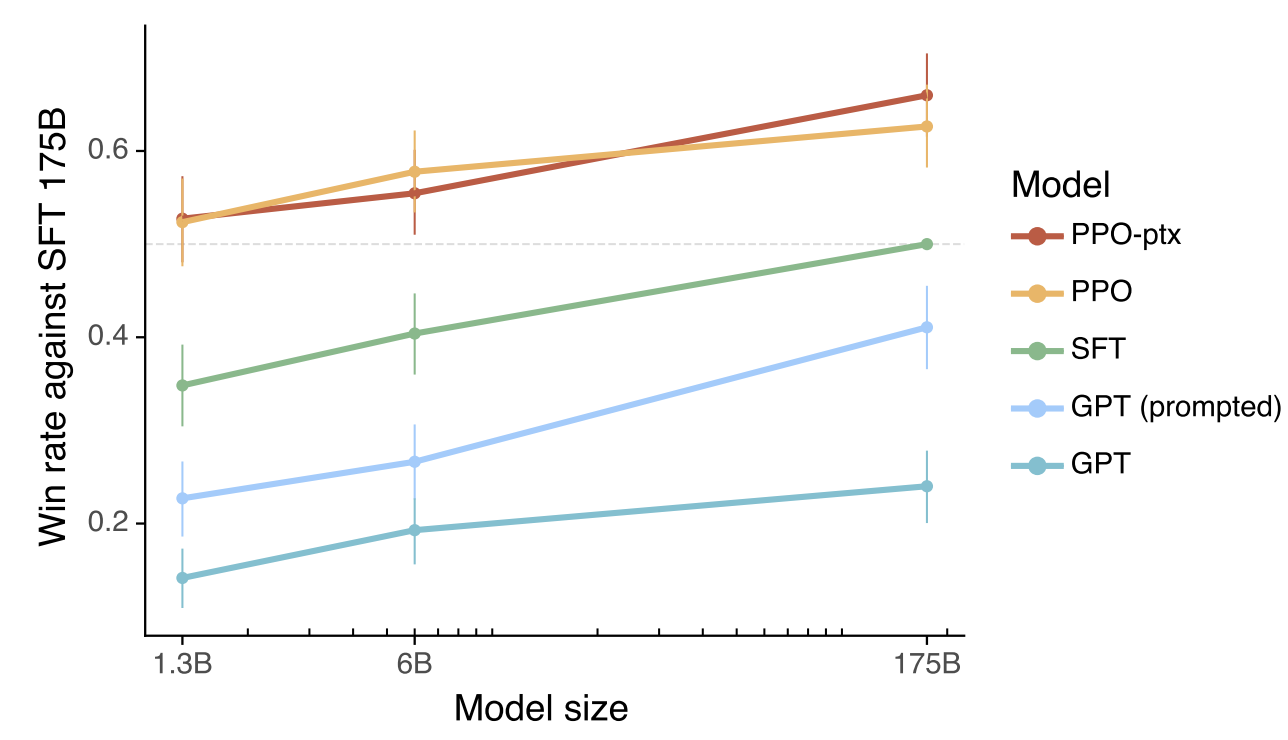
(据我回忆,ChatGPT训练的GPT3.5虽然人类反响很不错,但是在很多数据集上性能是变差了的。)
在训练模型时,我们通常需要平衡两种类型的错误:欠拟合(模型在训练数据上的性能不佳)和过拟合(模型在训练数据上的性能很好,但在未见过的数据上的性能不佳)。这种平衡被称为“对齐税”。
其他文献:
实际上,对齐问题一直是个LLM的大问题,ChatGPT主要也就是想解决这个问题。
此外,这两天也看到很多论文在分析如何使用SFT,能更好的使模型对齐人类。
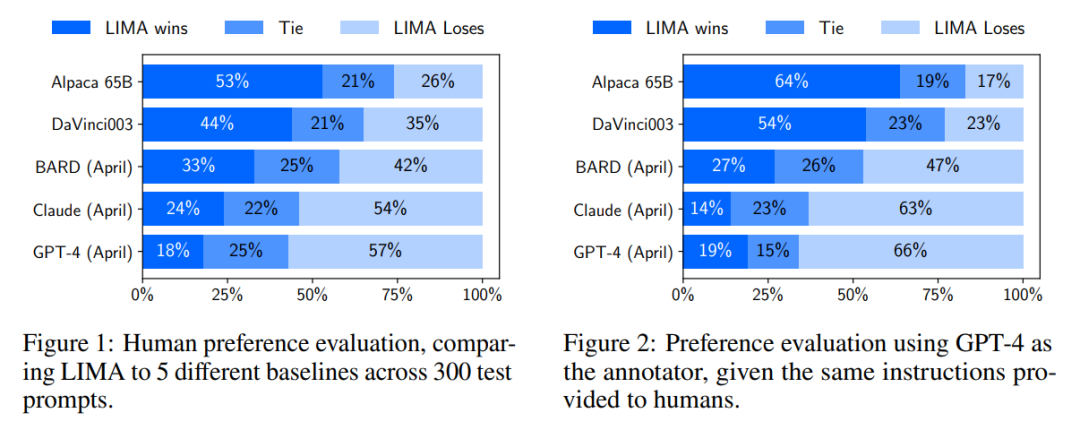
LIMA: Less Is More for Alignment,Meta提出:表面对齐假说(Superficial Alignment Hypothesis),将对齐视为一个简单的过程:学习与用户交互的样式或格式,来展示预训练期间就已经获得的知识和能力!
本文作者刘轶,已获作者授权发布,如需转载请联系
评论
