Prompt Tuning训练过程
大模型开发/技术交流
- Prompt
- P-tuning
2023.10.241774看过
前言
Pretrain + Fine-tuning(Model Tuning):
对于不同的任务,都重新 fine-tune 一个新的模型,且不能共用。但是对于一个预训练的大语言模型来说,这就仿佛好像是对于每个任务都进行了定制化,十分不高效。
Prompt Tuning:
对于不同的任务,仅需要插入不同的prompt 参数,每个任务都单独训练Prompt 参数,不训练预训练语言模型,这样子可以大大 缩短训练时间,也极大的提升了模型的使用率。
入门
NLP发展的四个阶段:
|
1st阶段 feature engineering
|
需要相关研究人员或者专业人士利用自己扎实的领域知识从原始数据中定义并提取有用的特征供模型学习。依赖于大量的人工
|
|
2nd阶段architecture engineering
|
如何设计一个合理的网络结果去学习有用的特征,从而减少对人工构建特征的依赖。
|
|
3rd阶段objective engineering
|
Pre-train, Fine-tune,更注重于目标的设计,合理设计预训练跟微调阶段的目标函数,对最终的效果影响深远。前面两个阶段都依赖于有监督学习,但是这个阶段里的预训练可以不需要有监督的数据,极大的降低了对监督语料的依赖。
|
|
4th阶段prompt engineering
|
在特定下游任务下可以通过引入合适的模版(prompt)去重构下游任务,管控模型的行为,实现zero shot或者few shot。一个合适的模版甚至可以让模型摆脱对下游特定任务数据的要求,所以如何构建一个合理有效的prompt成为了重中之重。
|
什么是Prompt
Prompt就是提示词的意思,一种为了更好的使用预训练语言模型的知识,采用在输入段添加额外的文本的技术。
-
目的:更好挖掘预训练语言模型的能力
-
手段:在输入端添加文本,即重新定义任务(task reformulation)
在NLP中Prompt代表是什么呢?
-
prompt 就是给 预训练语言模型 的一个线索/提示,帮助它可以更好的理解 人类的问题。
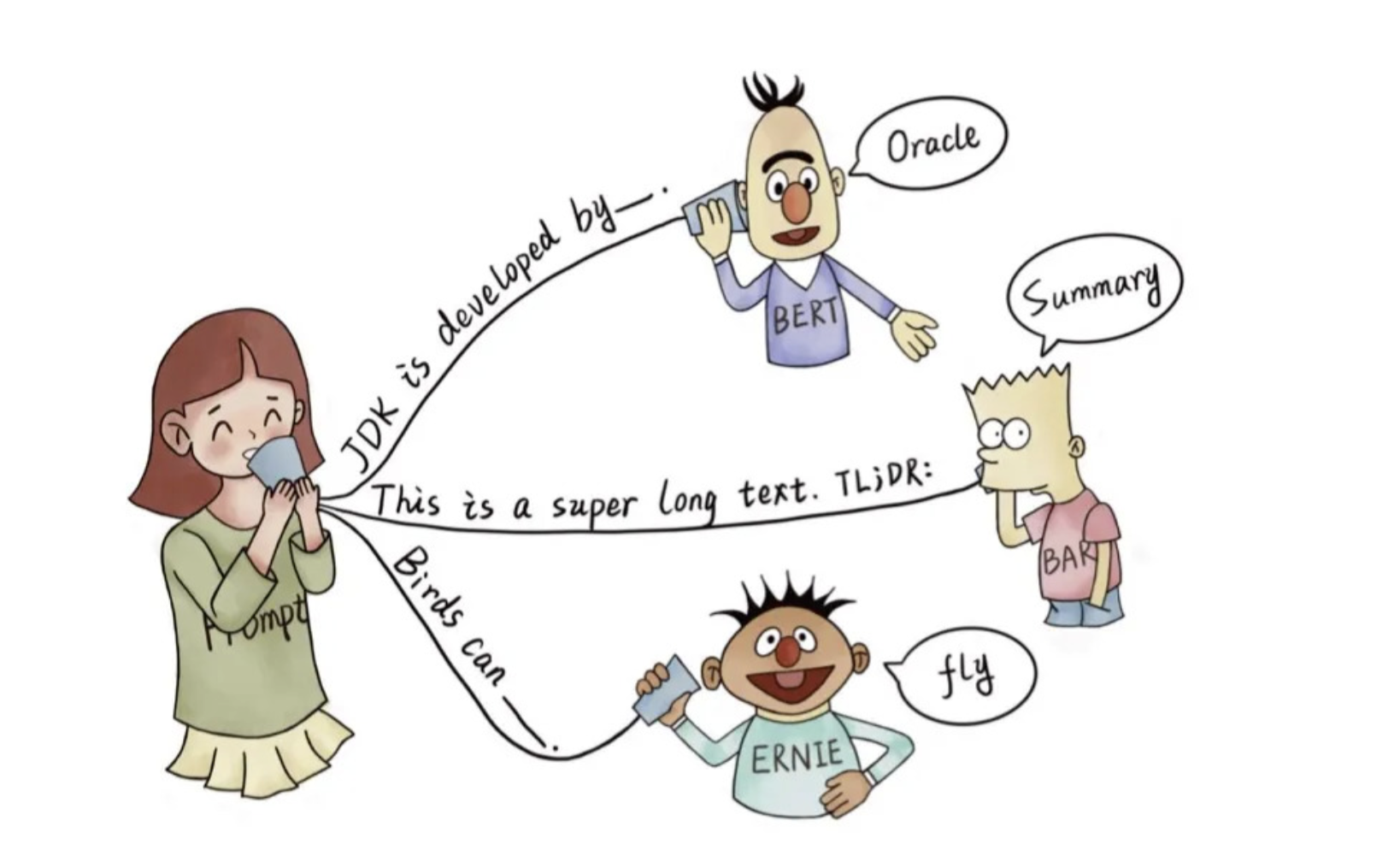
例如,下图的BERT/BART/ERNIE 均为预训练语言模型,对于人类提出的问题,以及线索,预训练语言模型可以给出正确的答案。
-
根据提示,BERT能回答,JDK 是 Oracle 研发的
-
根据 TL;DR: 的提示,BART知道人类想要问的是文章的摘要
-
根据提示,ERNIE 知道人类想要问鸟类的能力–飞行
Prompt工作流
Prompt工作流包含一下4部分:
-
Prompt模版 (Template)的构造
-
Prompt答案空间映射(Verbalizer)的构造
-
文本代入 Template,并且使用晕训练语言模型进行训练
-
将预测结果映射回label
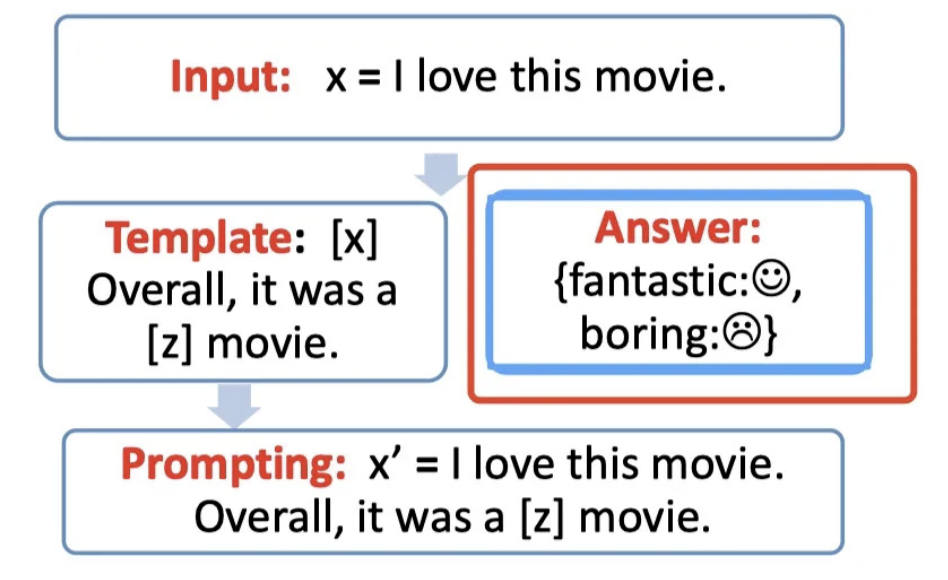
step1:prompt construction【Template】
首先,我们构造一个模版,模版的作用是将输入和输出进行重新构造,变成一个新的带有mask slots的文本,
-
定义一个模版,包含2出带填入的slots:【x】和【z】
将【x】用输入文本代入
例如:
例如:
|
输入:x = 我喜欢这个电影。
模版:【x】总而言之,它是一个【z】电影
代入(prompting):我喜欢这个电影。总而言之,它是一个【z】电影
|

|
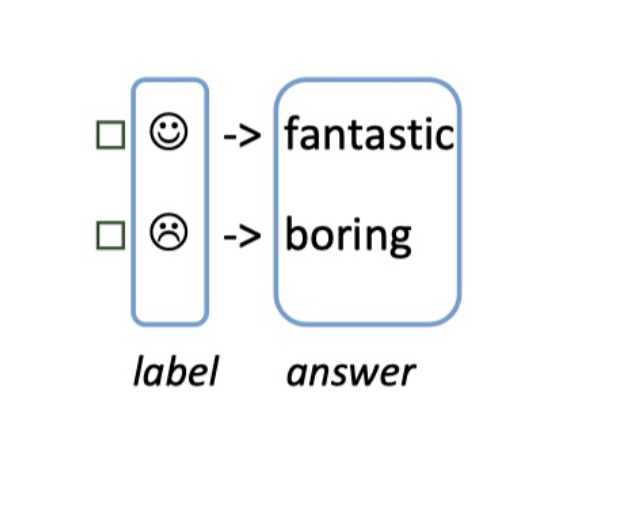
step2:answer construction【verbalizer】
对于构造的prompt,需要知道预测词和label之间的关系,并且z不是任意词,需要一个mapping function将输出词与label进行映射。
例如:
|
|
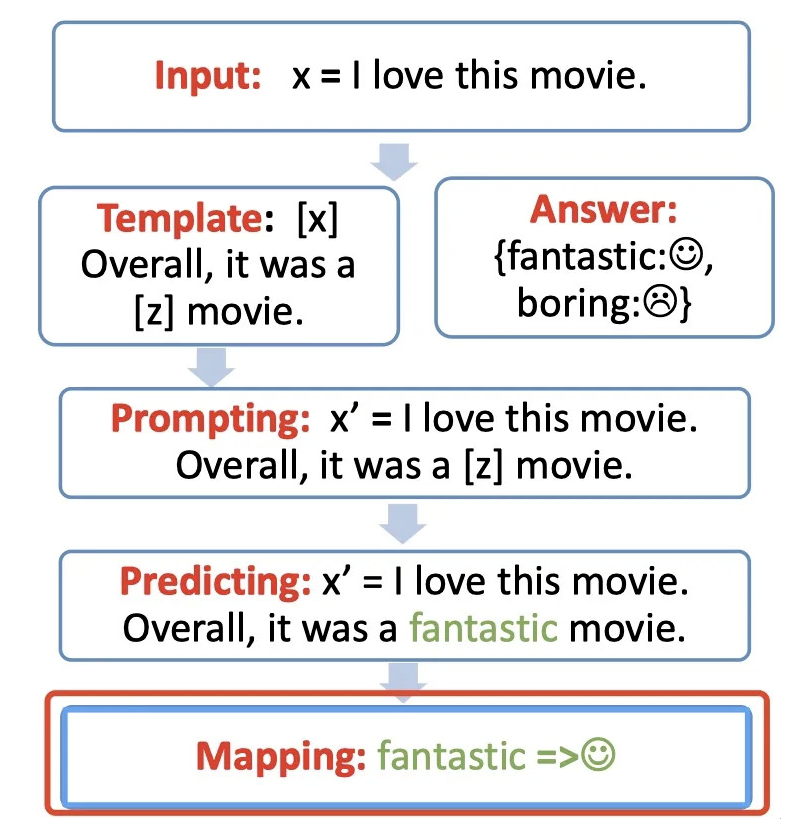
step3:answer prediction【Prediction】
选择合适的预训练模型,进行mask slots 【z】的预测。
例如:

step4:answer-label mapping【mapping】
得到的answer,需要使用verbalizer将其映射回原本的label
例如:fantastic 映射回label
总结:
|
Terminology
|
Notion
|
Example
|
|
Input
|
x
|
I love this movie
|
|
Output(label)
|
y
|
|
|
Template
|
-
|
【x】overall,it was a 【z】movie
|
|
Prompt
|
x'
|
I love this movie. overall,it was a 【z】movie
|
|
Answer
|
z
|
fantastic, boring
|
Prompt-based Training Strategies (训练策略选择)
Prompt-based模型子啊训练中,有多重训练策略,可以选择那些模型部分训练,哪些不训练。
根据训练数据的多少分为:
|
Zero-shot
|
对于下游任务,没有任何训练数据
|
|
Few-shot
|
对于下游任务,只有很少的训练数据,例如:100条
|
|
Full-shot
|
有很多训练数据,例如1W多条数据
|
Prompt Mining
人工构建Prompt的方式有两个弊端,人工构建Prompt和测试Prompt效果耗费时间跟精力,另一方面专业人士也不一定能通过人工的方式构建最优的prompt。为了解决这个问题,自然而然就衍生自动构建prompt的方式,自动构建prompt分为离散型的prompt(prompt可以用具体的字符表示)和 连续型的prompt(prompt由向量替代)
————————————————
版权声明:本文为CSDN博主「tiki_taka_」的原创文章如有侵权,请联系千帆社区进行删除
评论
