如何准备用于微调的数据集?
大模型开发/技术交流
- LLM
2023.10.243816看过
微调是指在有标注的数据上进行有监督的学习,目的是让模型适应特定的任务和场景,如文本分类、文本生成、文本摘要等。在微调的过程中,首先需要面对的就是数据集的准备和处理,通常需要一组由单个输入提示和关联的所需输出(完整结果)构成的训练示例(至少提供几十到几百个)。以下是数据集处理的通用步骤,希望对大家有帮助。
Step 0 数据获取工具列举
Web爬虫工具
PyAutoGui
Save to Notion插件
Step 1 数据处理,创建数据集
❗️需要爬虫工具和批量处理数据格式的工具
-
Prompt tuning- 需要设计Prompt模板,将少量数据代入模板;开源预训练模型一般会给出数据实例,仿照示例数据构建数据集,涵盖标签数据准备、Verbalizer准备、prompt模板设定。
❗️Prompt-tuning,关键是如何自动化生成提示模板。构建合适的模板既需要垂类领域专业知识,又需要对语言模型内部的运作方式有充分理解。
❗️将Prompt示例以上下文的形式添加到每个输入中,关键是如何对示例进行采样。
Step 2 上传训练数据
以千帆大模型平台为例,上传训练数据支持:本地导入、BOS目录导入、分享链接导入等方式。
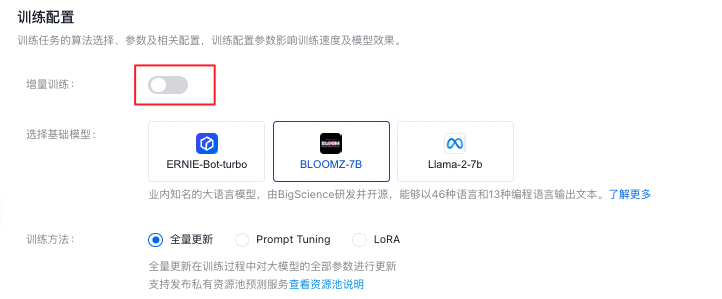
Step 3 选择基础模型并进行微调模型
选择适合的基础模型,并配置大模型参数,调整好基本配置。
Step 4 测试模型
得到SFT模型后,可以观察以下数据:
(1)Training loss和Perplexity的收敛曲线,成功的训练一般有明显的收敛过程,收敛出现在训练过程的后半部分都是合理的。
a)如果没有明显收敛,说明训练不充分,可以增加训练epoch重训,或者进行增量训练。
b)如果收敛出现在训练过程的前半部分,而后部分的loss平稳无变化,说明可能有过拟合,可以结合评估结果选择是否减少epoch重训
c)如果有收敛趋势,但没有趋于平稳,可以在权衡通用能力和专业能力的前提下考虑是否增加epoch和数据以提升专业能力,但会有通用能力衰减的风险。
附录:微调工具推荐
-
OpenPrompt:大模型提示学习利器。提供统一接口的提示学习模板语言(定义清晰的数据加载和处理,模板,映射器,PromptModel等模块), 它的组合性和模块化可以让你轻松部署提示学习方法以驱动大模型。OpenPrompt is a library built upon PyTorch,supports loading PLMs directly from huggingface transformers。
-
-
Haystack:帮助开发人员的 NLP 应用程序快速构建语义搜索、问答、摘要和文档排序等服务。
评论
