基于Langchain和数据湖分析的检索增强生成的样板间实现
大模型开发/技术交流
- LLM
- 文心大模型
- 插件应用
2023.11.151856看过
概述
大数据和AI的关系
在大模型的时代背景下,大数据与 AI 无疑是两个最重要的技术生态,尽管如此,大数据和 AI 的技术生态却在许多方面表现出明显的割裂感。这种割裂在存储、格式、流程、框架、平台等方面尤为突出,这使得开发者在实现端到端的数据处理和 AI 工作流程时,常常面临着重重挑战。但是,大数据和大模型之间又是相辅相成的关系。
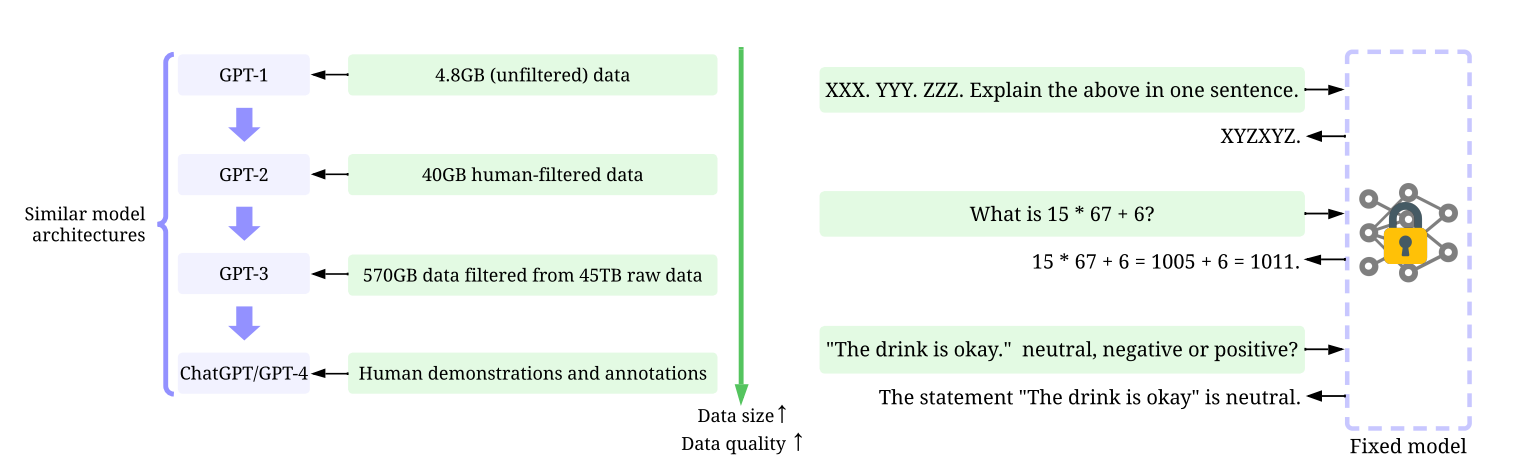
如上图可以看到,大体量和高质量的数据极大的驱动了 GPT 模型的领先,但是其模型架构中仍然存在一些类似模型参数权重的模型调优的问题。当模型足够稳定强大后,使用者只需要需要提示词工程技能,就可以完成很多功能,达到使用目的。
检索增强生成
Meta AI 的研究人员引入了一种叫做 检索增强生成(Retrieval Augmented Generation,RAG)的方法来完成一些知识密集型任务,其本质是基于语言模型构建一个系统,访问外部知识源来做到。这样的实现与事实更加统一,生成的答案更可靠,还有助于缓解“幻觉”问题。RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
一个完整 RAG 管道如下:
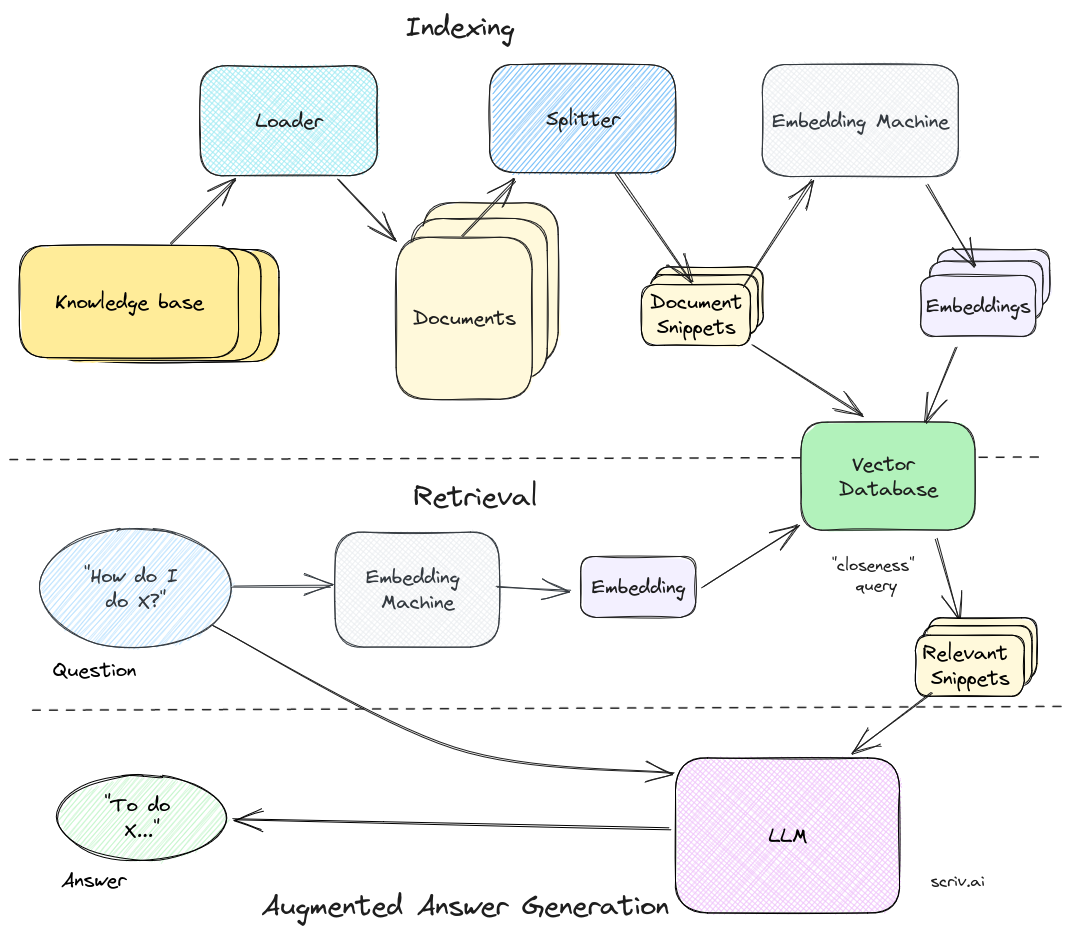
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科、本地文档等)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。
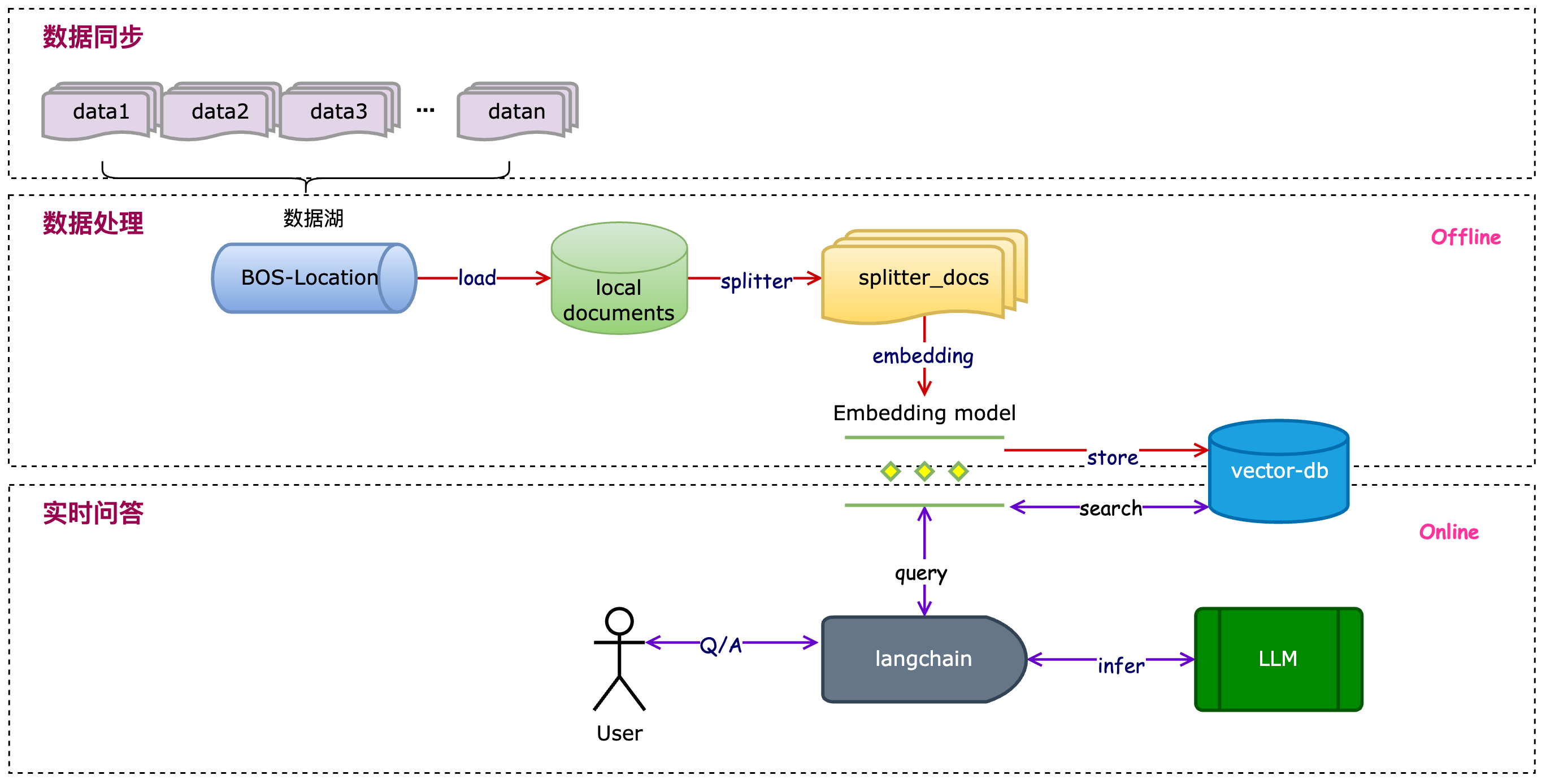
本文通过百度智能云数据湖分析平台 EDAP,将搭建一个基于数据湖中的非结构化数据作为文档来源,从而进行大模型推理的检索增强生成(RAG)过程,其中EDAP为整个过程提供了数据湖存储、数据同步和数据处理的能力。
整体思路
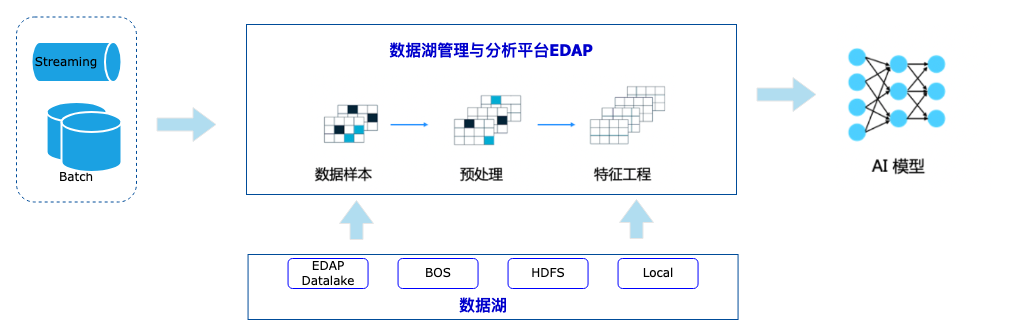
EDAP 具备同时处理流数据和批数据,并支持在数据湖上进行分析的能力,整体思路如下图。
-
EDAP 通过批处理或者流处理的计算,将数据湖的数据(结构化、半结构化和非结构化)的数据进行处理。
-
数据处理大致包括 数据样本准备(loader)、数据预处理(splitter)和特征工程(embedding)等,最后将数据处理结果作为大模型的输入。
-
接着再通过实时问答的形式,能够基于大模型做一些问答、汇总等能力的展现。
在实现层面,基于langchain的集成框架,结合EDAP与BOS打通的数据湖存储和 BES 天然的向量存储能力,完成整个数据处理(数据加载、模型访问和召回、向量检索)过程。
具体方案
全量知识数据接入
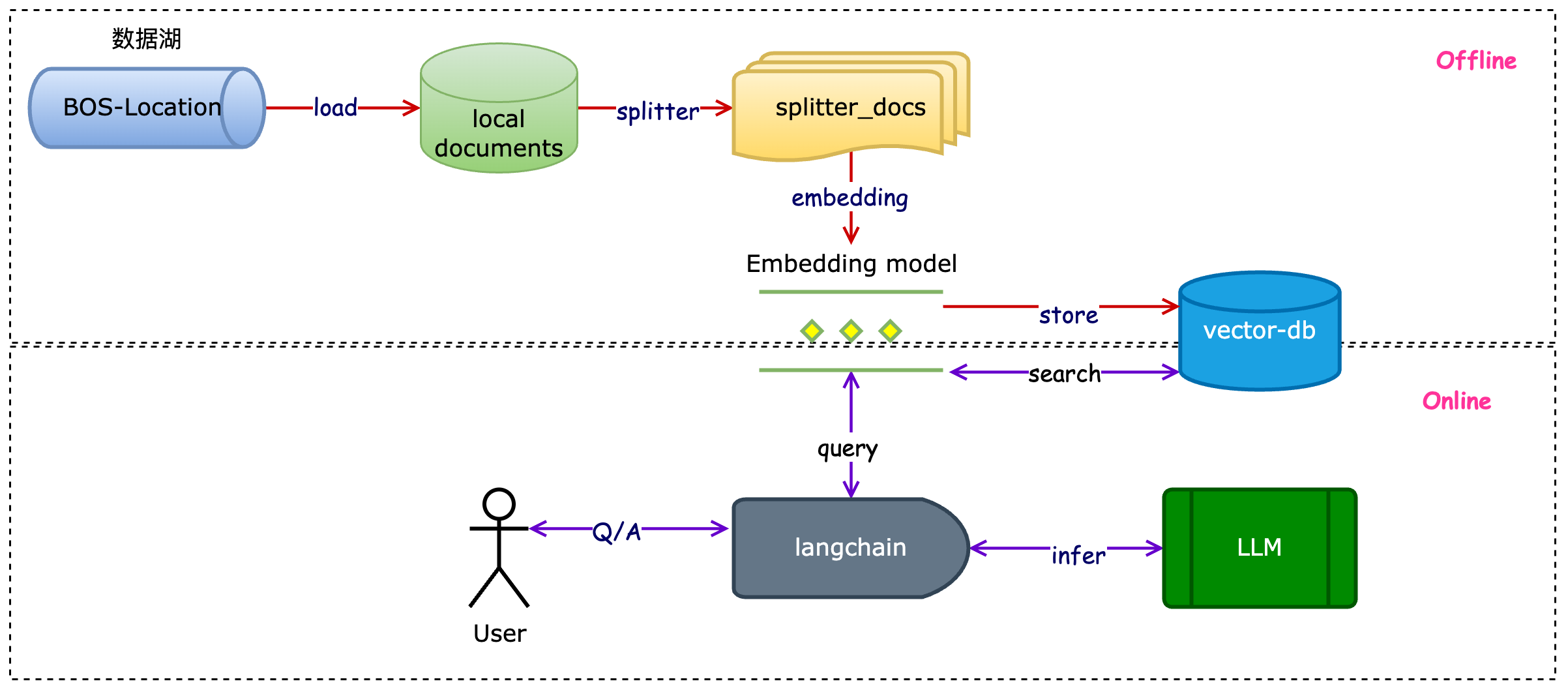
-
引入资源:在 EDAP 平台上引入单机资源,在单机资源上,预装了 langchain、elasticesearch及其相关依赖。
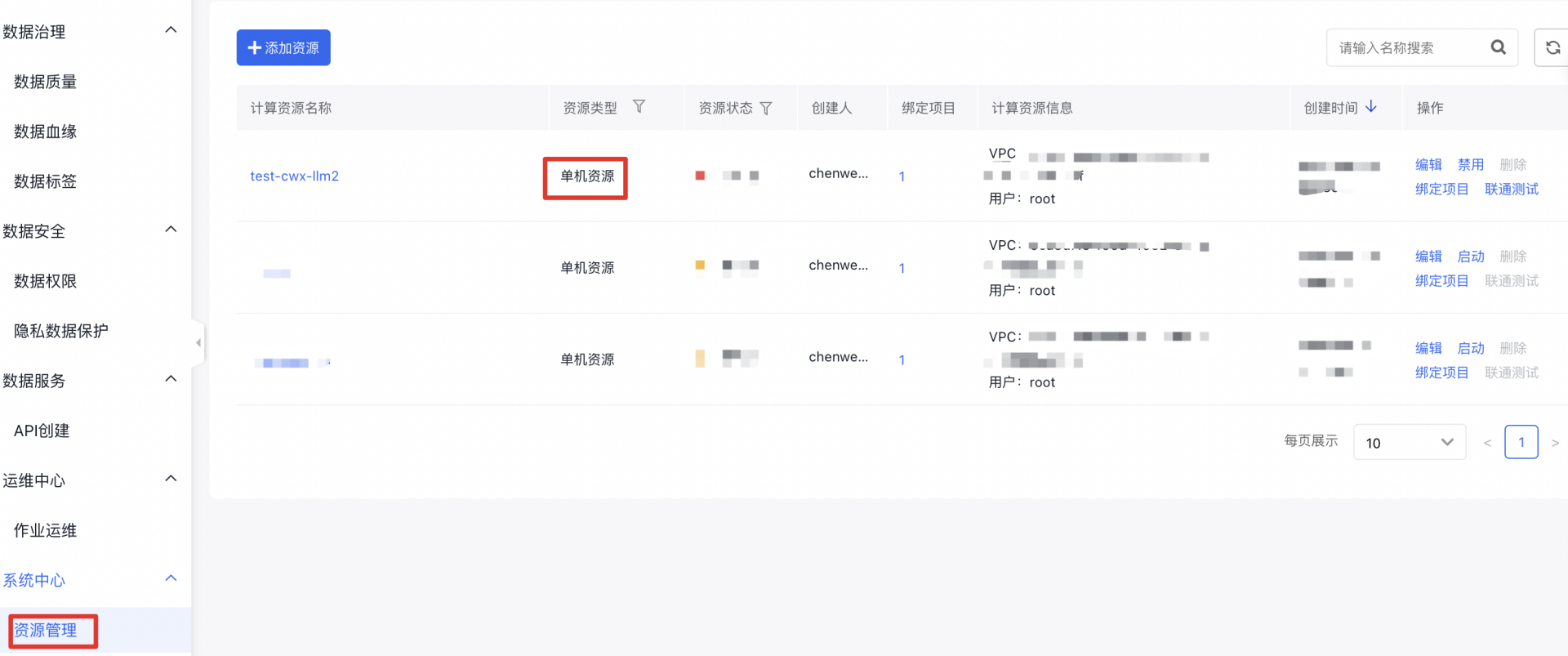
pip install |grep lagchainlangchain 0.0.332langchain-experimental 0.0.8
-
数据准备:将PDF文档等一系列非结构化放在了 BOS 中。
-
数据读取:通过 BOS DocumentLoader 将数据load 下来,通过splitter、embedding 过程,将其存放在 BES中。
from baidubce.bce_client_configuration import BceClientConfigurationfrom baidubce.auth.bce_credentials import BceCredentialsbos_host = "your bos eddpoint"access_key_id = "your bos access ak"secret_access_key = "your bos access sk"#创建BceClientConfigurationconfig = BceClientConfiguration(credentials=BceCredentials(access_key_id, secret_access_key), endpoint = bos_host)from langchain.document_loaders.baiducloud_bos_directory import BaiduBOSDirectoryLoaderloader = BaiduBOSDirectoryLoader(conf=config, bucket="llm-test", prefix="llm/")documents = loader.load()from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=0)split_docs = text_splitter.split_documents(documents)
# 文本向量化from langchain.embeddings.huggingface import HuggingFaceEmbeddingsimport sentence_transformersembeddings = HuggingFaceEmbeddings(model_name="shibing624/text2vec-base-chinese")embeddings.client = sentence_transformers.SentenceTransformer(embeddings.model_name)from langchain.vectorstores import BESVectorStoredb = BESVectorStore.from_documents(documents=split_docs, embedding=embeddings, bes_url="your bes url", index_name='test-index', vector_query_field='vector')db.client.indices.refresh(index='test-index')retriever = db.as_retriever()
from langchain.llms.baidu_qianfan_endpoint import QianfanLLMEndpointllm = QianfanLLMEndpoint(model="ERNIE-Bot", qianfan_ak='your qianfan ak', qianfan_sk='your qianfan sk')qa = RetrievalQA.from_chain_type(llm=llm, chain_type="refine", retriever=retriever, return_source_documents=True)
-
在线问答:基于 BES 的向量数据库建立召回器,注入到LLM Chain 中,生成问答。
query = "脚本开发的流程是什么"print(qa.run(query))

以上是对全量的非结构化数据进行加载、切分、向量化、召回的体系搭建。
增量私域知识数据处理
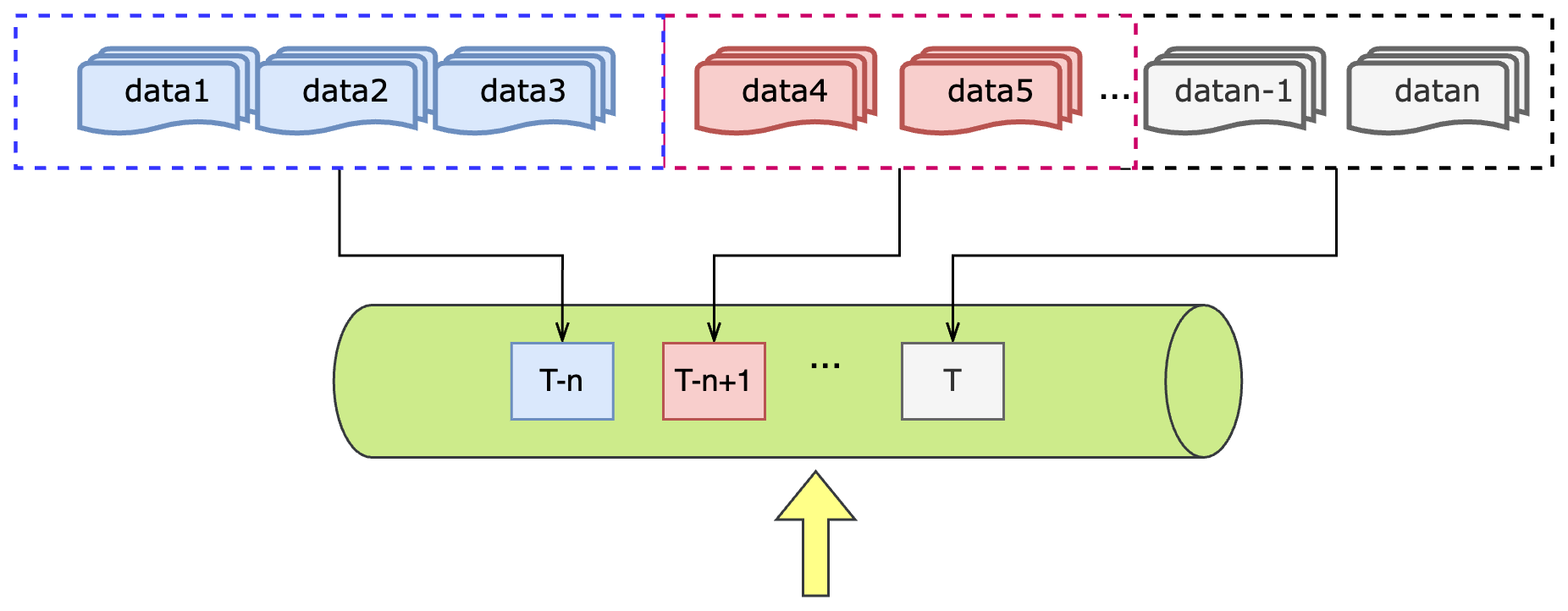
但是在很多实际的场景中,通常第一次用户接入的时候是全量数据,但是后续会以离线调度落入特定分区或者是实时计算生成增量数据的形式存储在文件系统(HDFS、BOS 等) 中,因此,在全量数据接入的基础上,还需要考虑增量数据的预处理过程,整体思路如下:
-
数据湖中的数据按照增量同步的方式例行化生成在固定分区中。
-
例行化(周期性)的数据处理任务进行数据预处理(包含loader、splitter、embedding 和 vector-store)的过程
-
用户可实时进行知识问答,知识库的私域知识也是例行化更新的,因此可以实现完成的 RAG 过程。
增量数据发现
在增量数据的处理过程中,其实如何及时有效的发现增量数据是很重要的,在这里提供两种思路:
-
通过定时的全扫location,并且和内存中的已处理location数据做比较,找到不同处,即为增量数据,这种方式非常简便,但是也存在如下问题:
-
-
随着数据量的增大,全扫方式必定会带来一定的性能问题。
-
当系统出现故障时,内存中已处理的location数据信息需要及时备份,否则会出现系统恢复后的全量数据的接入。
-
-
上下游之间加入消息中间件,通过一定的事件通知机制,当上游处理完数据后,发送通知消息,下游定时消费通知消息,处理增量数据。这种方式将上下游进行解耦,能够通过流式的方式处理增量数据。
总结
随着大模型的发展,大模型对于大数据的架构提出了更高的要求,也带来了机遇和挑战。本文以基于大模型的RAG 过程为抓手,对大数据在大模型推理过程中辅助数据同步、存储和处理做了一定的阐述,总结如下:
-
对于大数据架构来说,可以通过大模型的框架可以实现对于半结构化和非结构化的数据处理。
-
对于大模型来说,存储侧不再是依赖本地存储,也可以依赖分布式文件系统、对象存储等典型的大数据存储介质。
-
对于知识密集型的应用场景来说,可以通过大数据的离线调度数据处理,结合实时数据同步,实现知识的增量更新,提升检索增强能力。
评论
