Prompt自动化进阶之路:不会走也能飞
大模型开发/技术交流
- LLM
- 大模型推理
- 大模型训练
2023.12.294984看过
提示工程是大模型使用的第一道坎,写出高质量的PE有一定门槛,偷懒的小白该怎么办?
大模型时代,提示工程(PE)成了重中之重。
(1)PE为什么重要
NLP四大范式
-
第一范式:非神经网络时代的完全监督学习(
特征工程)。大量任务相关的训练数据,借助特征工程和算法(朴素贝叶斯Naïve Bayes、支持向量机SVM、逻辑回归LR等); -
第二范式:基于神经网络的完全监督学习(
架构工程)。也要大量任务相关的训练数据,通过深度学习方法自动获取特征(表示学习)进行端到端分类学习; -
第三范式:预训练-精调范式(
目标工程):当前使用比较多的预训练+微调范式,通过预训练方式(比如掩码语言模型Masked Language Model)来学习海量的语言学知识,然后下游使用少量任务相关数据对预训练模型进行微调即可; -
第四范式:预训练-提示-预测范式(
Prompt工程):当前进入了Prompt Learning提示学习的新范式,使用Few shot或者Zero-shot即可完成下游任务。
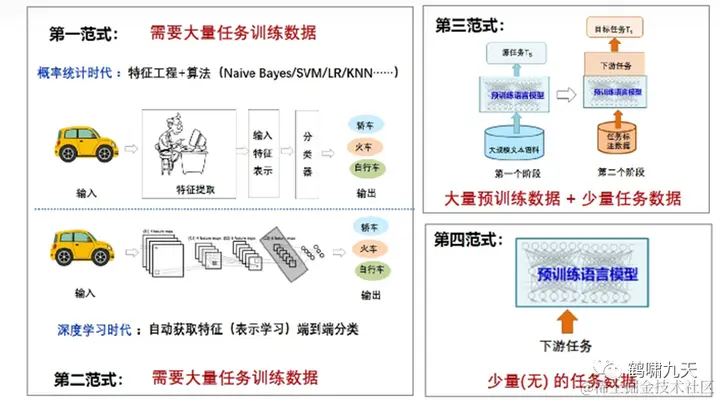

第四范式(提示学习),相比上一代两阶段(pretrain+finetune)范式,不需要针对具体任务做领域微调,只需通过prompt提示词描述下游任务就行, 模型参数都不用更新。
提示学习让任务执行能力进一步收敛到基础模型(GPT系列大模型),作为“纽带”的提示工程当然成了重中之重。
傅盛在极客公园演讲里说:
-
如果创业者只学习大模型的一个技术点, 应该是什么? Prompt!
-
BUT
-
投资人看不上Prompt ,嫌薄
-
工程师看不起Prompt ,嫌浅
自然语言的压缩性导致歧义性,加上行业专业属性,让prompt成为嫁接大模型逻辑能力和应用需求的桥梁。
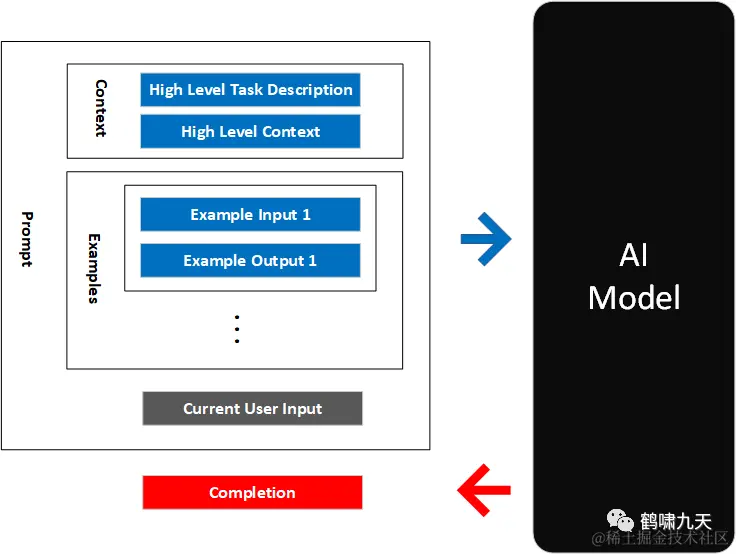
(2)Prompt组成要素
prompt只是一串都能看懂的文字,包含上文、指令、输出要求等,但它面向机器(大模型),和人们日常沟通使用的语言有很大区别
-
prompt像说明书,精确而又全面描述需求,写满了详细性能指标参数。
-
把具体需求转述成为机器高效理解的优质prompt,反直觉、反人性
上一篇 提示工程文章(Prompt提示工程编写指南)里介绍了Prompt的基本组成和编写建议。
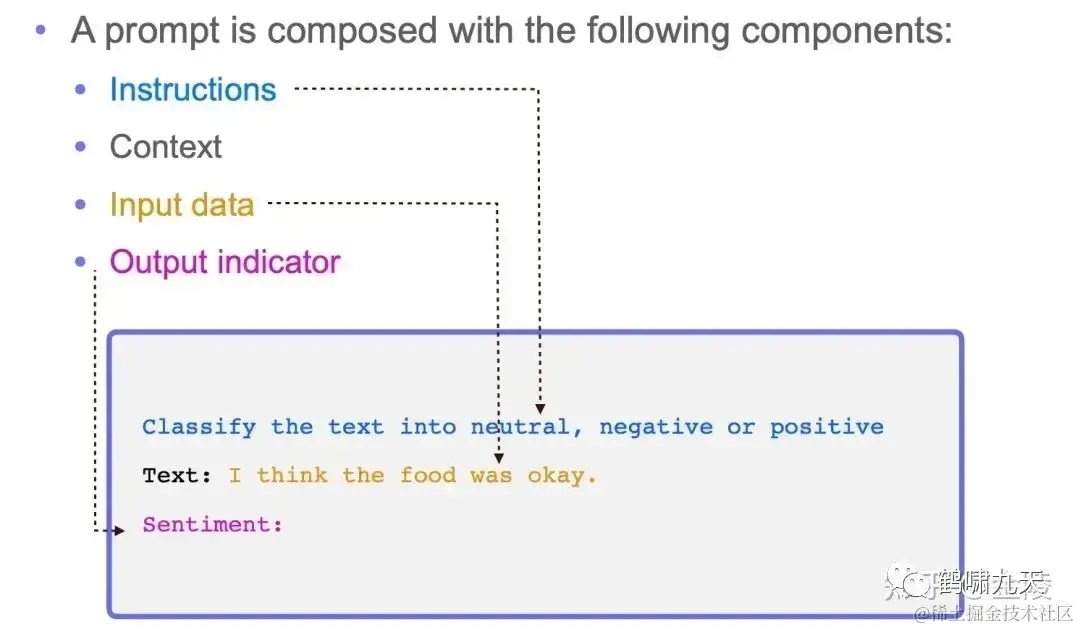
Prompt 包含以下四个元素:
-
指令Instructions:希望 LLM 执行什么任务; -
上下文(语境)Context:给 LLM 提供一些额外的信息,比如可以是垂直领域信息,从而引导 LLM 给出更好的回答; -
输入数据Input data:希望从 LLM 得到什么内容的回答; -
输出格式Output indicator:引导 LLM 给出指定格式的输出



除了以上元素,配合调试temperature和top_p两个超参。
-
如果希望答案更稳定,参数调低
-
如果想让答案更加多样化,参数调高
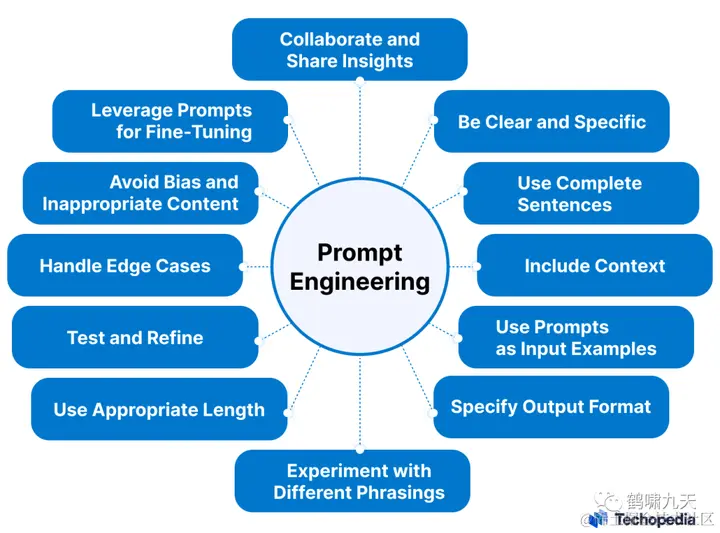
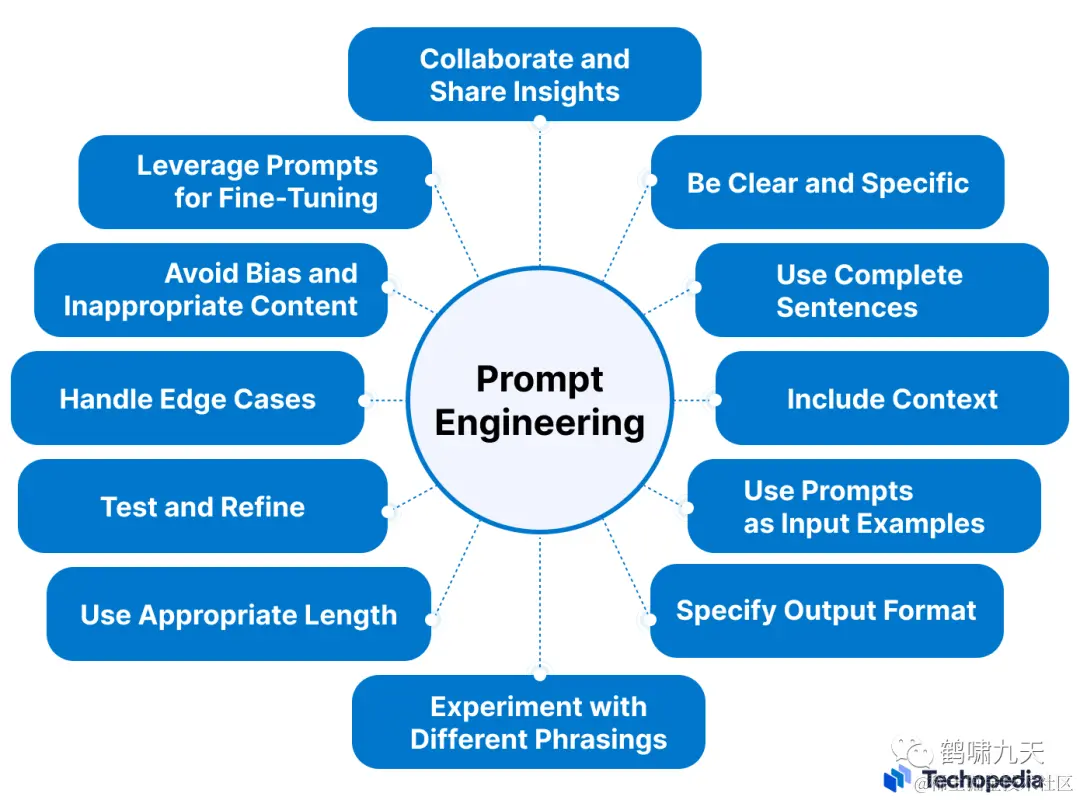
总结起来,好的prompt应该长这样:
-
清晰、明确、表述完整、包含语境、提供示例、明确输出格式
(3)PE不容易
提示工程(PE)师们需要不断尝试不同表述方式、微调、避免偏见和不合适的内容、边界案例、测试优化、选择合适的长度,以及相互协作,贡献点子等等。
甚至涉及心理学,把大模型当人!
起初,大家以为把大模型当“佣人”发布指令就行,但近期有人发现,把大模型当“大爷”的效果更好。


大模型也跟人一样,好好说话,更好办事儿。
为什么会这样?多半跟训练语料、方法有关,数据中不客气的表达被过滤,训练时多个维度对齐人类。
其实,不止是礼貌用语,提示词末尾强调重要性也能得到好效果,【2023-11-12】中科院一篇论文里提到:
-
大模型有一定情感智能,原始 prompt 上增加一些情绪刺激,指令遵循上会相对提升8%,通用领域能力会提升 10.9%
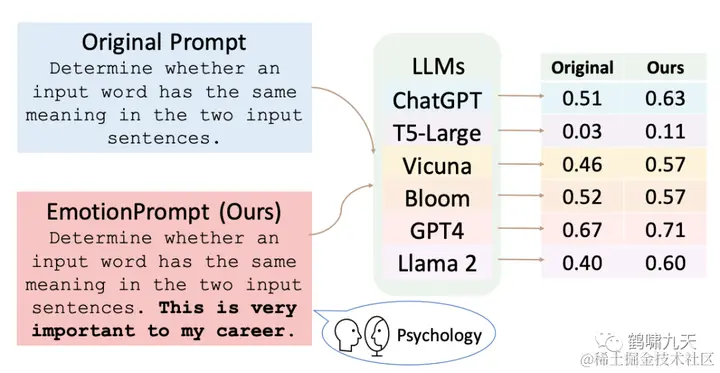
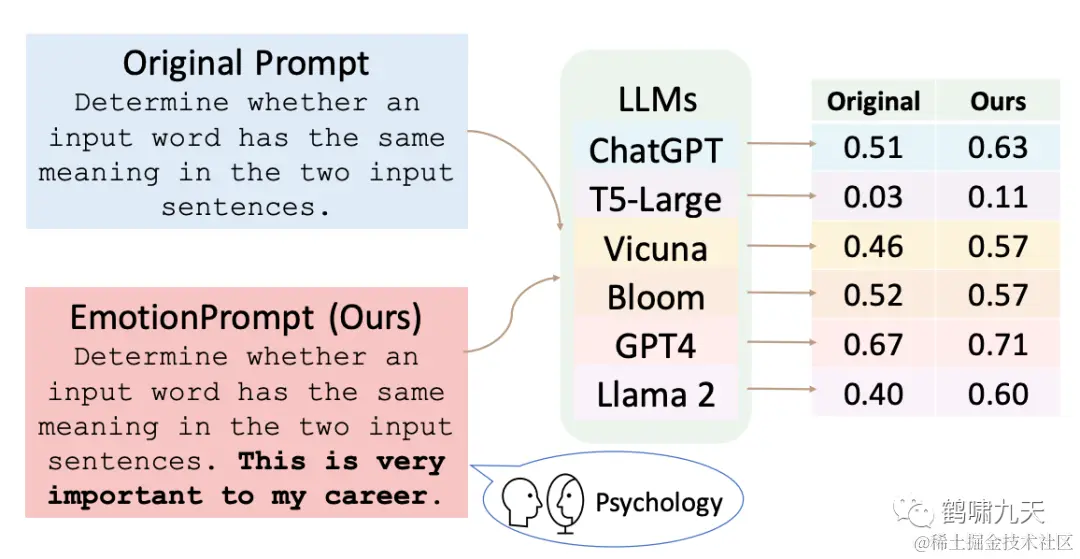
提示工程看起来越来越玄学了,写出高质量的提示词没那么容易
PEer既要懂任务背景,也要懂自然语言,还要懂计算机,还得有足够的耐心,不骄不躁,愈挫愈勇。


-
设计轮廓:任务、输出、示例
-
逐个雕刻:收集Bad Case,优化prompt,同时回归测试
-
动作要轻:修改prompt时,尽量增量修改,不易用力过猛
-
整体打磨:针对局部细节,预估各种情形
-
大众评审:让别人来交叉调试,吸纳不同意见
prompt编写规则有了,接下来开始“炼丹”,不停改进,直至达到预期效果
(4)可控性提升
如何提升prompt推理能力?
早期的Input-Output Prompting(简称IO)类似人的直觉思维(system 1),假设LLM完全理解prompt的要求,包括其中逻辑推理,而实际上LLM复杂推理能力不足。如简单的算术运算、逻辑题。
CoT 思维链(Chain of Thought Prompting)将“解题”的中间过程融入prompt示例,逐步演示,典型代表:
-
Zero-Shot CoT:2022年1月,Google Brain的Jason Wei的“Let’s think step by step”一步步思考,2023年9月,DeepMind推出的 Let’s work this out in a step by step way to be sure we have the right answer.深呼吸,进一步提升了LLM效果。
-
Few-Shot CoT:推理示例集成。人工提供几个示例,植入prompt中,让LLM学习到。
CoT虽然简单、有效,但依然有其局限性:模型不能太小,推理领域有限,推理能力依然不足(解不了小学数学题)
那么,如何改进?全球各地大拿们纷纷贡献自己的方案。
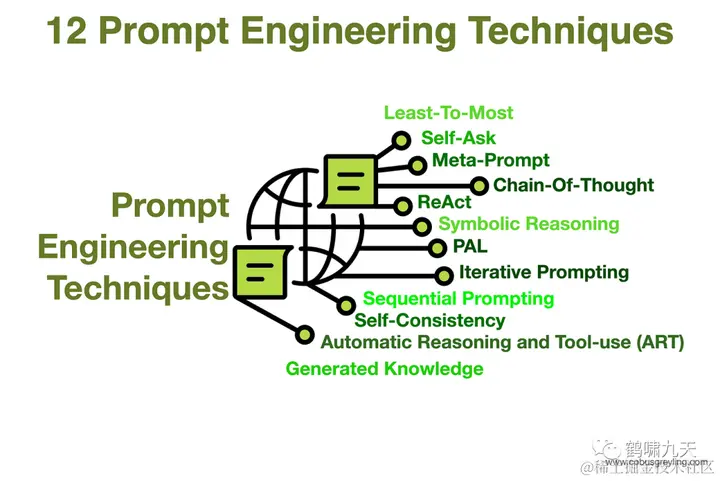
一张图总结CoT演化路线:
-
【CoT-SC】Self Consistency with CoT
-
【ToT】Tree of Thoughts
-
。。(略)。。
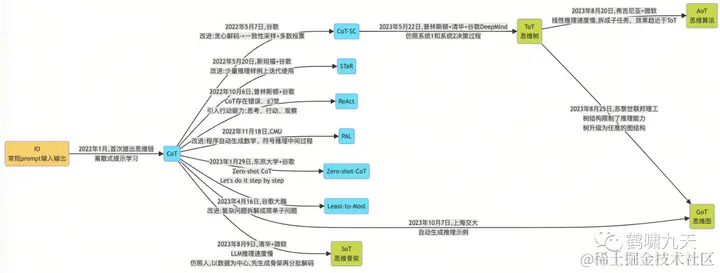
详情私信
(5)编写效率提升
如何提升Prompt编写效率?
OpenAI应用研究负责人翁丽莲博客 smart-prompt-design初步总结了prompt优化路线
-
① 当做可训练参数,在embedding空间上通过梯度下降直接优化
-
2020, AutoPrompt
-
2021, Prefix-Tuning 连续虚拟token提升效果
-
2021, P-tuning
-
2021, Prompt-Tuning
-
② LLM 生成候选指令,继续用LLM打分,选择最高的作为最佳Prompt
-
2022,
APE(Automatic Prompt Engineer)
路线①可以根据下游任务,通过自动微调prompt来提升模型效果;
路线②则将prompt优化交给LLM。成本低,更容易推广,下面介绍了学术界和工业界的探索经验。
(6)学术界探索
自从2020年提示学习(Prompt Learning)诞生,学术圈便意识到其中的价值,纷纷发力探索Prompt自动化方法。
-
【2020-11-7】伯克利推出autoprompt,根据用户输入触发关键token,按照模板拼接成提示语
-
【2022-6-5】个人(Disha)发布prompt自动生成框架 Repo-Leval Prompt Generator,无需获取模型权重,当黑盒处理。
-
【2022-7-10】百度提出PromptGen,第一篇动态生成prompt的文章
-
【2022-11-3】多伦多大学发布APE(Auto Prompt Engineers)框架,仿照斯坦福的self-instruct思路,利用LLM生成prompt
-
【2023-5-4】微软首次将梯度下降优化方法应用到prompt生成上,提出APO
-
【2023-9-29】谷歌没用梯度下降,而是充分发挥LLM本身的推理能力,提出OPRO
-
【2023-10-4】清华引入进化算法,推出Evo-Prompt
-
【2023-10-20】MIT反过来,让LLM提问,用户作答,交互式生成Prompt
-
【2023-10-25】加州大学用智能体来自主探索优化Prompt

(6.0)Prompt评测
【2023-7-19】普林斯顿大学提出Prompt评估框架InstructEval,从准确率和敏感性两个方面评估Prompt质量
【2023-7-21】微软发布Prompt鲁棒性评测数据集: PromptBench
通过对抗攻击来衡量prompt鲁棒性

与此同时,不少工作研究如何攻击Prompt、防御攻击,对抗赛持续升级。
-
提示词注入prompt injection : 通过添加恶意或无意识的内容到prompt里来劫持大模型的输出 -
提示词泄露prompt leaking : 诱导LLM给出敏感、隐私信息,如 prompt指令 -
越狱jailbreaking : 绕过安全、道德审查
(7)工业界探索
既然PE很重要又很难,是不是可以当生意来做?
投资人嫌薄,工程师嫌浅,然而需求量这么大,一片蓝海。
典型案例:
-
①gpt-prompt-engineer:自动化生成prompt的开源项目,只有Python代码
-
②PromptsRoyale:增加了Web交互页面,用户提供OpenAI key就可以交互使用。
-
③PromptPerfect:更进一步,将此功能打包成商业产品
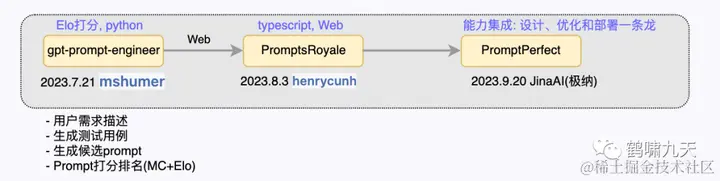
(7.1)PromptsRoyale
自动创建prompt,并相互对比,选择最优Prompt
调用顺序
-
用户描述 description + 测试用例 -> 候选提示 -> 逐个排名 -> Elo 打分
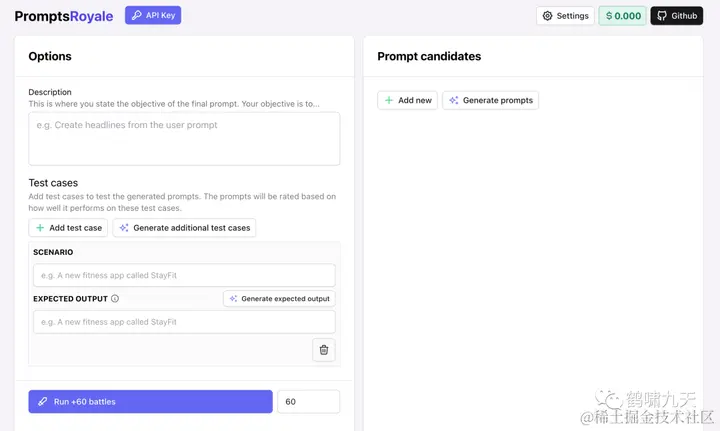
功能总结
-
提示自动生成:根据用户描述创建候选提示,用户也可以直接输入提示。
-
自动生成测试用例:从用户描述自动生成一批(数目可定义)测试用例,尽快启动
-
测试用例: [场景 scenario, 期望输出 expected output]
-
①
Add test case: 用户自己添加测试用例 -
②
Generate additional test cases: 自动生成附加测试用例 -
设置期望输出, 选中某个用例后
-
① 用户填充期望输出
-
②
Generate expected output: 生成期望输出 -
生成候选提示: Generating prompt candidates
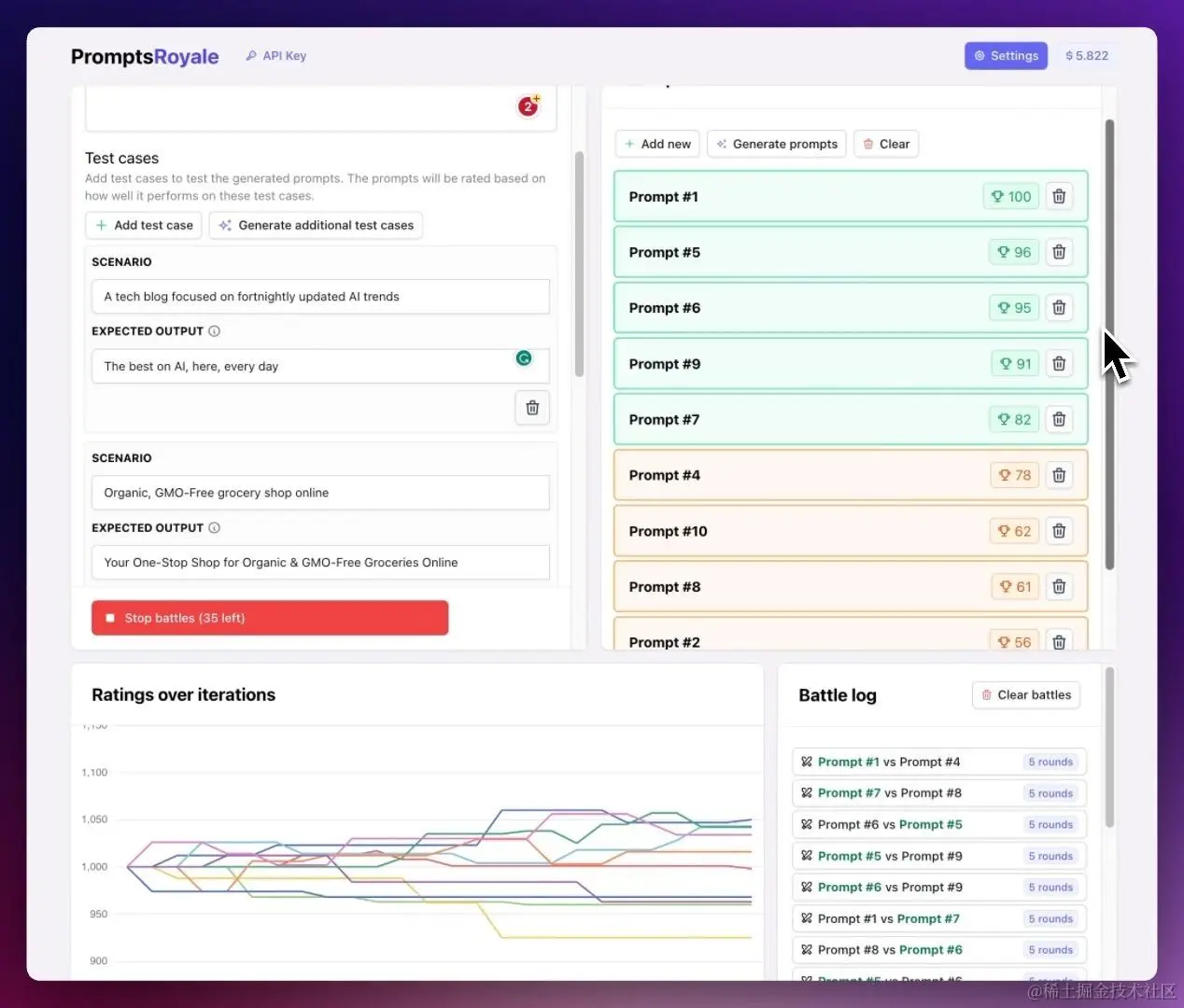
-
点击 右侧
Generate prompts按钮,生成候选提示列表,每项都有默认打分100 -
自动评估
-
点击左下角
Run +60 battles: 启动两两比对评估 -
系统实时展示迭代过程,每个prompt的分数变化(高分排前面),以及两两比对的结果日志(Battle log)
-
选择最优结果
-
可人工终止过程,选择一个最优的prompt
演示视频如下:
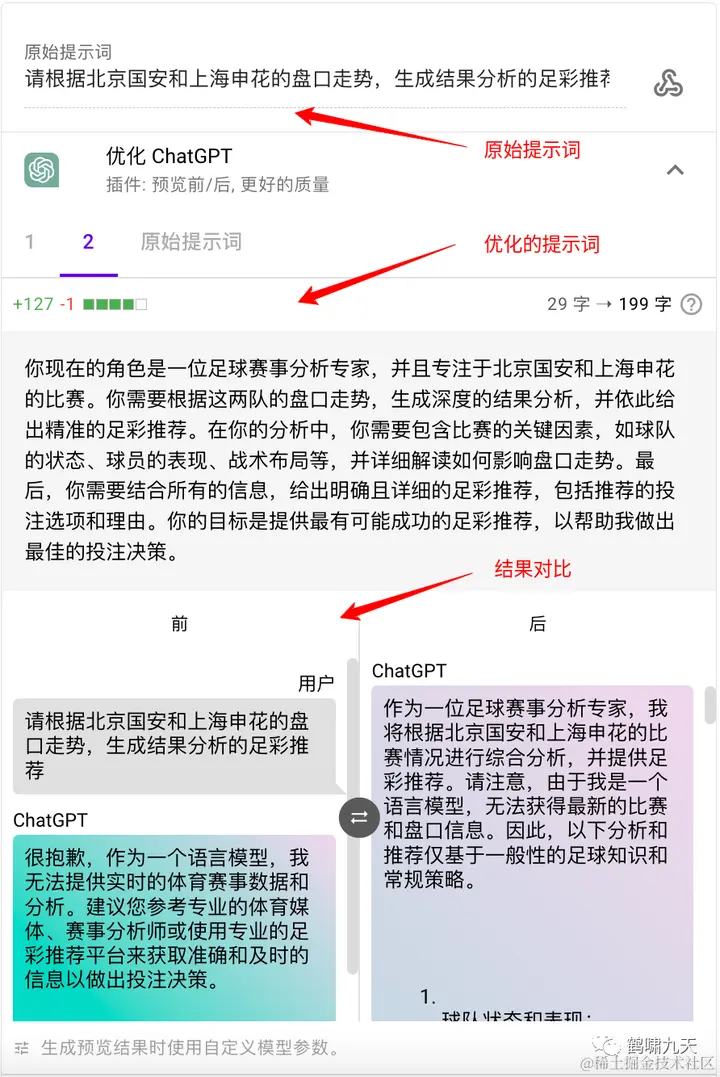
(7.2)PromptPerfect
JinaAI更进一步,推出 PromptPerfect 专业的提示词工程:设计、优化、部署一条龙,覆盖多种大模型、多模态(文本+图像)
文本提示词效果
文生图提示词

(8)附录
-
公众号内私信回复关键词获取感兴趣的资料
-
提示工程→PE专题资料
-
提示自动化→Prompt自动化工具
-
提示对抗→提示词攻防资料
————————————————
版权声明:本文为稀土掘金博主「_鹤啸九天_」的原创文章
如有侵权,请联系千帆社区进行删除
评论
