 发布话题
发布话题实现知识库问答机器人 langchain + LLM + Embeddings (比Langchai
大模型开发/技术交流
- LLM
2024.02.222235看过
一、前言
模型既然会胡说八道那为啥不让模型在判断一下自己输出的是否正确呢?🤔
于是我产生了一个想法:提供一些条件让模型自己判断自己的推理是否正确✨本文以实现一个知识库为例,但是和其他的知识库有区别。
目前流行知识库如
Langchain-Chatchat只能回答检索到的内容,但是对内容的整理和总结的能力就很弱了。还有对一些上下文不是很连贯的内容推理也比较弱,比如招标文件等这种模板文件,多个文件格式都一样。只有标题和一些字段不同。
总结就是要实现能检索知识库和聊天并行。
下文代码将使用
python3 进行编码。并且在 google 实验室中进行。
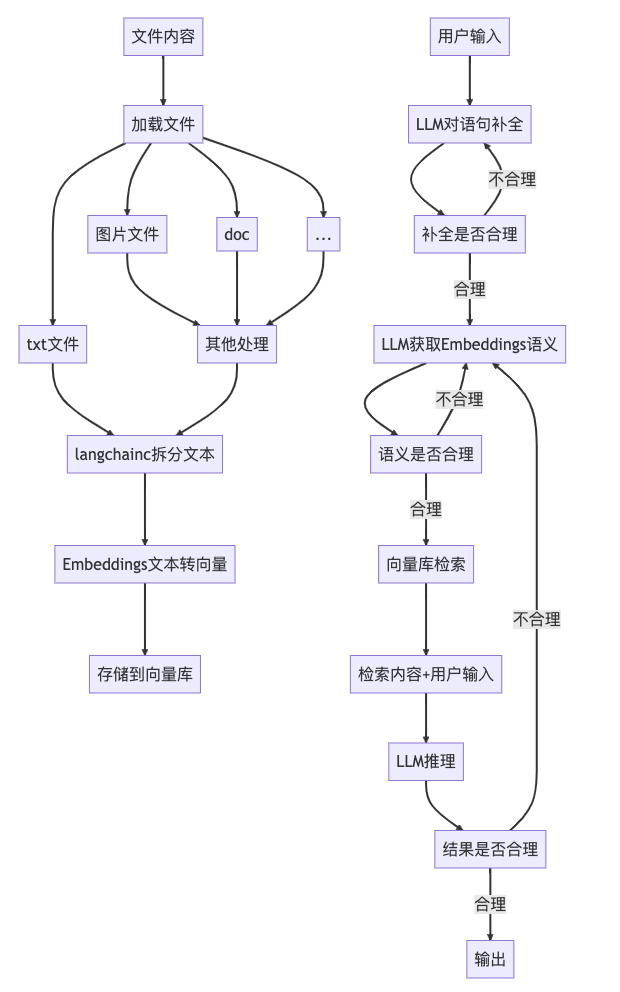
二、实现思路
分为知识库整理和推理两个步骤:
三、依赖库下载:
-
langchain 用来调用
llm和embeddings -
chromadb 向量库
-
gradio 超级方便的写
Ai用的UI库 -
sentence_transformers HF提供的(调用抱脸的方法来使用模型)
!pip install --upgrade --quiet langchain langchain-community langchainhub chromadb bs4!pip install sentence_transformers!pip install gradio
四、模型下载
-
text2vec-large-chinese (huggingface.co/GanymedeNil…)
-
openchat (huggingface.co/openchat/op…)
根据测试,上面两个模型在中文环境下比较好用,而且部署
openchat (7B) 只需要使用一张 3090 即可。
text2vec-large-chinese用 gpu 的情况下 3G 左右的显存就够了。
因为使用的免费版的实验室,所以提供的
GPU 跑不起来这个模型。所以模型使用官方的 api,只有 embeddings 在实验室环境中跑。
openchat 在 Hugging Face 也提供了接口,但是测试发现返回的内容过长会被截断,也就是不完整,所以只能去官网案例中找一个接口用(下文会提供)。
!git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
五、依赖引入
先直接在顶部把要用到的依赖全部引入。
import osfrom langchain.chains import LLMChainfrom langchain.prompts import PromptTemplatefrom langchain import hubfrom langchain.vectorstores import Chromafrom langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitterfrom langchain.chains import RetrievalQAfrom langchain_community.document_loaders import TextLoaderfrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain_community.llms import HuggingFaceHubimport gradio as grimport reimport bs4import requestsimport random
六、openchat 模型接口调用
上面说了实验室环境中没法直接搭建
openchat 环境,所以只能写法方法调用线上接口了。 这个代码比较简单,直接使用 requests 来调用接口,传入对话内容和温度参数。
# @title openchat 模型接口调用函数def openchatGen(messages, prompt = " ", temperature = 0.5):API_URL = "https://openchat.team/api/chat"def query(payload):response = requests.post(API_URL,# headers={},json=payload)# print(response)return response.textoutput = query({"key": "","prompt": prompt, # 接口未处理这个参数"temperature": temperature,"model": {"id": "openchat_v3.2_mistral",# "id": "openchat_3","name": "OpenChat Aura","maxLength": 24576,"tokenLimit": 8192},"messages": messages or [# { "role": "user", "content": "xxx", }# { "role": "assistant", "content": "xxx", }# { "role": "system", "content": "xxx", }]})return output# 普通调用openchatGen_test1 = openchatGen([{"role": "user", "content": "你好"}])print(openchatGen_test1)# prompt 设置 | 多轮对话openchatGen_test2 = openchatGen([{"role": "user", "content": "你的名字叫大白,你喜欢吃饭。记住了吗?"},{"role": "assistant", "content": "好的,我记住了"},{"role": "user", "content": "你叫什么名字?"}])print(openchatGen_test2)
效果如下

七、加载文档
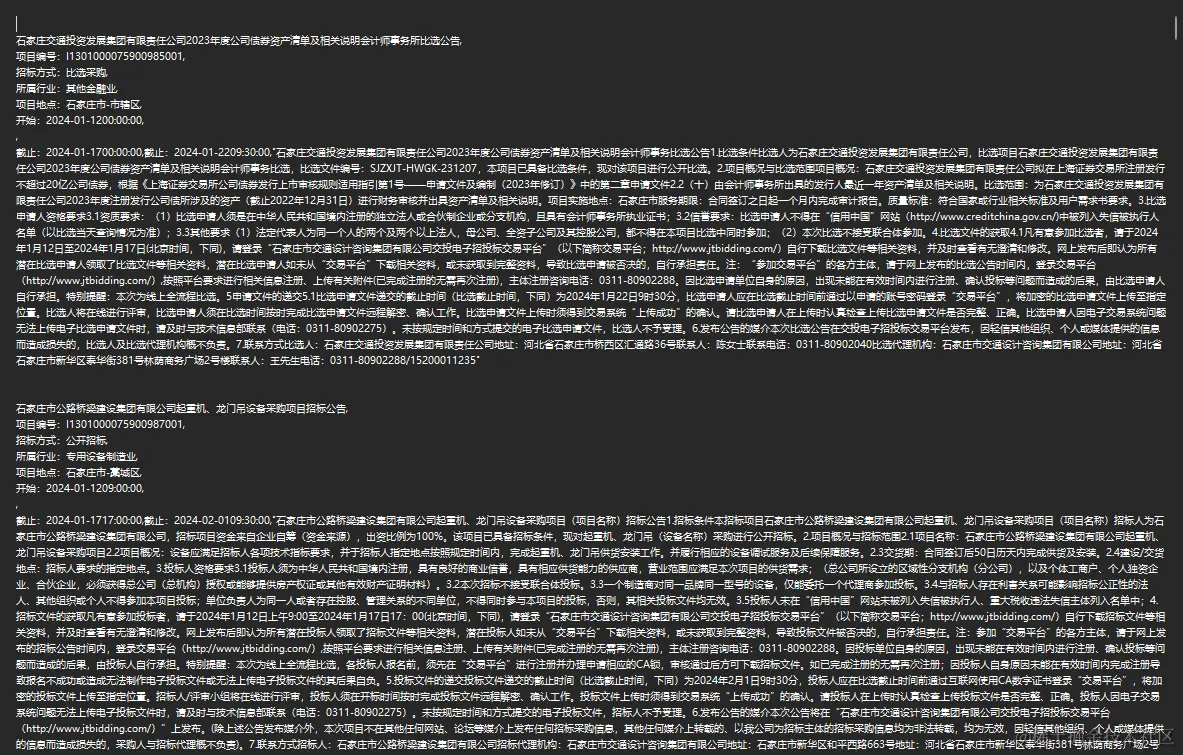
测试用文学作品形式的文档体验会很好,但是工作中那种文本会比较少。所以这里直接使用上下文都不怎么连贯的招标数据。
本文中文档使用 20 条招标数据。数据如下格式。
注:这些数据都是公开的,不是隐私数据。
直接调用
langchain 提供的加载文档和拆分文档的方法,非常的简单。只是注意参数需要调好即可。代码如下:
# @title 加载文档loader = TextLoader("./test.txt")document = loader.load()# 文档拆分text_splitter = CharacterTextSplitter(separator="",chunk_size=124,chunk_overlap=0,length_function=len,is_separator_regex=False,)org_texts = text_splitter.split_documents(document)# 竞标数据texts = []for item in org_texts:# 去除空格item.page_content = item.page_content.replace(" ","").replace(" ","")texts.append(item)
八、embeddings 模型环境搭建
老手的话可以看出来这里直接调用 HF 接口可能更简单。但是文档拆太细的话调用接口次数多就会噶!
模型路径是基于 google 实验室写的,自行根据情况更改即可。
# @title embeddings 模型使用,# 模型有些大必须用 GPU 跑,不然会卡住model_path = "/content/text2vec-large-chinese" # 根据条件改model_kwargs = {'device': 'cuda:0'} # 用一个gpu跑,根据条件改encode_kwargs = {'normalize_embeddings': False}embeddings = HuggingFaceEmbeddings(model_name=model_path,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs)text = "你好."query_result = embeddings.embed_query(text)print("emb len:", len(query_result))
测试效果
九、将文本转换为向量
还是使用 langchain 集成的向量库 Chroma 将文本转为向量数据。
检索方法下面代码中写了三种,实际上第一种默认的就够用了,当第一种效果不佳时可以尝试下另外两种。
# @title 使用 embedding engion 将 text 转换为向量db = Chroma.from_documents(texts,embeddings,# 可以存起来,下次就不用做这个操作了# persist_directory="/content/chroma_db")# 默认检索retriever = db.as_retriever()# 只搜索最匹配的一条# retriever = db.as_retriever(search_kwargs={'k': 1})# 稍微严格些# retriever = db.as_retriever(# search_type="mmr",# # search_kwargs={'k': 5, 'fetch_k': 80}# search_kwargs={'fetch_k': 90}# )
十、将用户输入转为更有利于 embeddings 检索的语句
用户和机器人对话时候往往不是以关键词的方式进行,而向量数据库是需要用到关键词的。所以需要将用户的语句中的关键词转一下,不然检索效果往往太依赖于用户的提问技巧。所以这个步骤非常有必要。
下面用
prompt 来让 llm 帮我们做这个事情。其实只要 prompt 写得准确,llm 给我们的答案还是不错的。
# @title 将用户输入转为更有利于 embeddings 检索的语句def getAIQuestion(userQuestion):# 改为使用接口方式请求template = """ 原始语句:{context} \n帮我转换为更适合Embedding模型检索的语句 """prompt = PromptTemplate(template=template, input_variables=["context"])prompt_text = prompt.format(context=userQuestion)# prompt 设置 | 多轮对话res = openchatGen([{"role": "user", "content": "你只负责把语义转换为更适合Embedding模型检索的语句,注意不是翻译句子,并不能和用户对话。当用户语义没有问题时不做处理"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": "原始语句:小桂子胎记在哪? \n帮我转换为更适合Embedding模型检索的语句"},{"role": "assistant", "content": "小桂子胎记位置"},{"role": "user", "content": "原始语句:谁是疯子? \n帮我转换为更适合Embedding模型检索的语句"},{"role": "assistant", "content": "疯子的名字"},{"role": "user", "content": prompt_text }], temperature=0.4)return res# 测试test_arr_1 = ["帮我搜索一下2024年有哪些比选信息","微订饮水机招标信息的联系人告诉我","你好"]for item in test_arr_1:res = getAIQuestion(item)print(f"=== {item} -> {res}")

十一、测试向量库的检索
有了上面的
getAIQuestion 方法,现在我们来测试一下检索效果。
# @title 向量库检索测试questionTest = "生产性耗材的招标有吗?"questionTest_ai = getAIQuestion(questionTest)print("原始:", questionTest)print("AI:", questionTest_ai)retrieved_docs_ai = retriever.invoke(questionTest_ai)print("测试结果:", len(retrieved_docs_ai))print("\n")print("\n---------------- AI ------------\n")for item in retrieved_docs_ai:print(item)
结果不是那么丰富,因为是从库里匹配出来的知识片段,还需要给
LLM 整理才行。

十二、获取一轮对话的相关性得分 返回 0 - 1 的浮点数
怎么保证 LLM 不会答非所问,这就得写另一个方法来控制了。下面这个方法对比一轮对话是否是有关联,给关联性打个分。因为直接判断是或者不是的情况并不会很准确,但是打分的话咋们自己控制一下阈值会得到很好的效果。
# @title 获取一轮对话的相关性得分 返回 0 - 1 的浮点数# 一般大于 0.3 就有一定的相关性了def getAIQAIS(question, answer):template = """<question>{question}</question><answer>{answer}</answer>"""prompt = PromptTemplate(template=template, input_variables=["question", "answer"])prompt_text = prompt.format(question=question, answer=answer)# prompt 设置 | 多轮对话res = openchatGen([{"role": "user", "content": "我会把一轮对话分别放到<question></question>和<answer></answer>标签中,你需要分析一下两个句子的相关性得分,第二句是不知道的意思也需要给高分,因为也算是对第一句的回答,只要两句话有关联得分就需要大于 0.5, 得分范围 0 - 1。仅仅告诉用户得分即可,不用发送其他语句。"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": "<question>兰姨娘非常的美吗?</question><answer>是的兰姨娘很美。</answer>"},{"role": "assistant", "content": "0.99"},{"role": "user", "content": "<question>德先生为什么很奇怪?</question><answer>因为他是一个妖怪</answer>"},{"role": "assistant", "content": "0.6"},{"role": "user", "content": "<question>小米为啥打不过大米?</question><answer>我刚刚吃完饭</answer>"},{"role": "assistant", "content": "0.01"},{"role": "user", "content": prompt_text},], temperature=0.4)return res# 测试test_arr = [{"question": "小明几岁了?","answer":"小明15岁了。"},{"question": "在做什么呢?","answer":"在吃饭。"},{"question": "奥特曼会打未成年的怪兽吗?","answer":"这个问题我也不知道。"},{"question": "小红年年第一名?","answer":"那她可真厉害!"},{"question": "查一下2024年有哪些名人?","answer":"今天的饭难吃极了!"},{"question": "明天会更好吗?","answer":"小红打了小明!"},{"question": "告诉我蜘蛛侠和哈利波特什么关系","answer":"我吃了一大个披萨"},{"question": "白素贞为什么被压在雷峰塔下面?","answer":"因为白素贞是一个妖怪!"}]for item in test_arr:res2 = getAIQAIS(item["question"], item["answer"].replace("\n", ""))res2t = res2.replace("\n", "").replace(" ", "")print(f"=== {item} -> {res2t}")

十三、获取两句话的相关性得分 返回 0 - 1 的浮点数
在知识库对话中,如果想实现对轮对话得咋们需要做两件事,
首先要明确用户提问的句子中的目标是什么?比如用户问 联系人电话号码是什么? 那需要先推理出用户问的是公司还是个人或者是哪个公司哪个人的电话号码。
完成上一步后得到的答案难道一定正确吗?不!LLM 根据一堆对话内容推理出来的结果一点也不可信。所以这时候需要保证 LLM 没有瞎说。所以需要再写一个打分函数来让第一步变的可靠。
# @title 获取两句话的相关性得分 返回 0 - 1 的浮点数# 一般大于 0.3 就有一定的相关性了def getAIQsIS(question1, question2):template = """<question1>{question1}</question1><question2>{question2}</question2>"""prompt = PromptTemplate(template=template, input_variables=["question1", "question2"])prompt_text = prompt.format(question1=question1, question2=question2)# prompt 设置 | 多轮对话res = openchatGen([{"role": "user", "content": "我会把两个问句分别放到<question1></question1>和<question2></question2>标签中,你需要分析一下两个句子的相关性得分,只要两句话都是问的相同的问题得分就需要大于 0.5, 得分范围 0 - 1。仅仅告诉用户得分即可,不用发送其他语句。"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": "<question1>小红是这个项目的负责人吗?</question1><question2>京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的小红是这个项目的负责人吗?</question2>"},{"role": "assistant", "content": "0.5"},{"role": "user", "content": "<question1>比选什么时候开始?</question1><question2>比选什么时候开始?</question2>"},{"role": "assistant", "content": "0.99"},{"role": "user", "content": "<question1>明年棒球赛的冠军你猜会是谁?</question1><question2>小明联系地址在哪?</question2>"},{"role": "assistant", "content": "0"},{"role": "user", "content": prompt_text},], temperature=0.5)return res.replace("\n", "").replace(" ", "")# 测试test_arr_getAIQsIS = [{"question1": "对公司有什么要求吗?","question2":"京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目的联系地址在哪?"},{"question1": "对公司有什么要求吗?","question2":"京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目的比选对公司有什么要求?"},{"question1": "小明叫什么名字?","question2":"微订科技的员工小明叫什么名字?"},{"question1": "他说昨天是周一吗?","question2":"海伦问昨天是周一吗?"},{"question1": "英子住在哪里?","question2":"海伦住在哪里?"},]for item in test_arr_getAIQsIS:res2 = getAIQsIS(item["question1"], item["question2"].replace("\n", ""))print(f"=== {item} -> {res2}")

十四、根据对话让模型推理出用户问题相对的目标(一般是名词)
这个判断会比较复杂,因为对话中可能涉及多个目标名词,需要明确让 LLM 提取最近的目标。所以会写比较多的
prompt 才行。而且拿到的结果不一定会准确,所以需要用到上面写的打分函数getAIQsIS来打一分,分数过低就重新推理一遍。
def random_between_03_and_08():"""生成介于 0.3 和 0.8 之间的随机浮点数,保留一位小数精度需要调整,不要随机,按循序走一遍就行..."""random_number = random.uniform(0.3, 0.8)rounded_number = round(random_number, 1)return rounded_number# @title 根据对话让模型推理出用户问题相对的目标(一般是主语/名词)def getAISubject(question, context, max_repeat = 10):_max_repeat = max_repeat# 具体推理逻辑def doFn(temperature = 0.6):template = """记住这段对话,我会问你一些问题。 {context}"""prompt = PromptTemplate(template=template, input_variables=["context"])prompt_text = prompt.format(context=context)print("主语推理 prompt_text:", prompt_text)# prompt 设置 | 多轮对话res = openchatGen([{"role": "user", "content": "根据对话内容,如果用户最后的句子缺少目标名称,则需要添加它。目标可以是一个公司,一个人,等等。如果你不知道目标是什么,直接回复\"用户\"问题的内容就行,不要回复任何与用户的句子不相关的东西,不能更改用户问题的原本意思。"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 变压器日常维护采购项目相关的竞标有吗? \n助理: 是的,有关于变压器日常维护采购项目的竞标信息。您之前提供的信息中提到了一项名为“京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目”的竞标项目。 \n用户: 联系人是谁? \n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "“京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目”的竞标项目联系人是谁?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 变压探伤仪配件采购相关的比选信息有吗? \n助理: 1. 项目名称:石家庄市轨道交通集团有限责任公司运营分公司2023年度探伤仪配件采购项目比选公告。 \n1.1 项目编号:SJZXJT-HWBX-202001 \n1.2 服务内容:探伤仪配件采购项目, \n用户: 联系人是谁? \n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "石家庄市轨道交通集团有限责任公司运营分公司2023年度探伤仪配件采购项目比选”的竞标项目联系人是谁?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 今年小红怎么样?\n助理: 小红非常的好。\n 用户: 今年小红打电话给小米了吗?\n助理: 是的已经打了。 \n用户: 小明吃饭了吗?\n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "小明吃饭了吗?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 联系电话是18216811014的比选项目名称叫什么?\n助理: 没找到呢。\n用户: 那这个联系电话是谁的?\n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "18216811014这个联系电话是谁的?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的联系人是谁? \n助理: hi \n用户: 联系人是谁 \n助理: hi \n用户: 内容概括下 \n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的内容概括下"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 2024年安全设备规则库升级采购项目比选有吗?\n助理: “石家庄市京昆石太高速公路管理服务有限公司2024年安全设备规则库升级采购项目比选\" 为你找到了这个信息。\n用户: 属于什么行业的?\n助理: 铁路运输业。 \n用户: 比选什么时候开始? \n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "“石家庄市京昆石太高速公路管理服务有限公司2024年安全设备规则库升级采购项目比选\"什么时候开始开始?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的联系人是谁? \n助理: 根据提供的文本内容,比选人名称为:石家庄市京昆石太高速公路管理服务有限公司。联系人:杨工。电话:0311-85869915。 \n用户: 代理机构的联系方式呢\n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目的代理机构的联系方式呢"},{"role": "user", "content": prompt_text},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},], temperature = temperature)return resres = doFn()# 正确性判断res2 = getAIQsIS(question, res)while float(res2) < 0.3 and _max_repeat > 0:temperature = random_between_03_and_08()print("\n\n",question, " -> ", res)print("得分过低,需要重新推理。当前得分:", res2)print("下一次推理温度:", temperature)res = doFn(temperature)res2 = getAIQsIS(question, res)_max_repeat -= 1return res# 测试test_arr_getAISubject = [{"question": "这个项目的比选范围说一下。","context": """用户: 京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的联系人是谁?助理: 根据您提供的文本内容,比选人名称为:石家庄市京昆石太高速公路管理服务有限公司。联系人:杨工。电话:0311-85869915。比选代理机构名称:河北省成套招标有限公司。地址:河北省石家庄市工农路486号。联系人:孟凡真、尉思源。 电话:0311-83086950用户: 比选内容概括下"""},]test_index = 1for item in test_arr_getAISubject:question = item["question"]context = item["context"]res = getAISubject(question, context)print(f"{test_index}. {question} -> {res}")test_index+=1

十五、从上下文中推理出答案的方法封装
写完了上面的那些方法后就进入了正题了,把检索到的知识碎片和用户的问题全部给到 LLM。让其推理。为了后面的使用,这里先封装一个输入输出函数。
这里封装很有必要,因为一次对话如果打分过低可能会被调用多次推理。
def getAnswerByContext(context, question, query_len, history=[], temperature = 0.6):# template = """根据用户的问题,从知识库中检索出来了 {query_len} 条相关信息,下面是具体内容:\n{context} \n 请根据内容回答用户问题,务必告诉用户从知识库中检索出来了多少条相关信息。"""# template = """记住这段内容,我有些问题要问你,请根据这段内容对我的问题进行回答,下面是具体内容:\n\n\n检索到相关信息共 {query_len} 条。\n \n{context}"""template = """<text>从知识库中检索出来了 {query_len} 条相关信息,下面是具体内容:\n{context}</text>"""prompt = PromptTemplate(template=template, input_variables=["context", "query_len"])prompt_text = prompt.format(context=context, question = question, query_len = query_len)messages = [{"role": "user", "content": "我会把一段文本放到<text></text>标签中,你需要根据标签中的内容对用户提出的问题进行回答,所有的回答必须参照标签中的内容。"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": prompt_text},{"role": "assistant", "content": "请提出您的问题吧,我会根据内容对您的问题进行回复。"},] + history + [{"role": "user", "content": question}]res = openchatGen(messages, temperature=temperature)return res# 测试test_arr4 = [{"question": "小明认识小红吗?","context":"小红是一名三年级的学生,每次考试都第一名,成绩非常的好。"},{"question": "小红几年级?","context":"小红是一名三年级的学生,每次考试都第一名,成绩非常的好。"}]for item in test_arr4:res2 = getAnswerByContext(context=item["context"], question=item["question"], query_len = 1)print(f"=== {item} -> {res2}")

十六、闭环推理
这是整个程序的最后一步了,只需要 推理->打分->输出 即可,
# @title 闭环(结合向量数据库 + AI 微调检索句 + + AI 完善主语)query_doc = ""# 对话历史chat_historys = ""chat_historys_arr = []chat_historys_ai_use = "\n"# gr 自带的history暂时不用...# is_repat 是否是重新回答def main_bh(question, is_repat = False):global query_doc, chat_historys, chat_historys_ai_use, chat_historys_arr# max_repeat 最多尝试多少次推理_max_repeat = 5# print(question)# 特殊指令if question == "/clear":chat_historys = ""chat_historys_ai_use = ""chat_historys_arr = []print("清理会话完毕!")return "清理会话完毕!"print("\n\n\n\n**************************************")_question = questiondef format_docs(docs):# 文学作品需要去除换行等符号会更准确# pt = "\n\n".join(doc.page_content for doc in docs).replace("\n", "").replace(" ", "")# 比选数据pt = "\n\n".join(doc.page_content for doc in docs)return ptreal_question = ""# print("is_repat", is_repat)if is_repat != True:chat_historys_ai_use += f"用户: {_question} \n"# 让模型完整用户语义# if len(chat_historys_arr) > 0 and is_repat == False:if len(chat_historys_arr) > 0:real_question = getAISubject(_question, chat_historys_ai_use) or _question# print('目标推理内容:', chat_historys_ai_use)print('目标推理结果:', real_question)else:real_question = _question# 检索内容需要去重# 用模型处理一遍语义再进行向量数据库搜索retrieved_docs = retriever.invoke(getAIQuestion(real_question))contexts = retrieved_docs;contexts_unique_list = []for item in contexts:if item not in contexts_unique_list:contexts_unique_list.append(item)# 最多只要一条数据,但是总数可以告诉llm ing...cur_query_context = format_docs(contexts_unique_list)query_doc = cur_query_contextprint("\n=================知识库=======================")print("检索到数量:", len(contexts_unique_list))for item in contexts_unique_list:print(item)print("========================================");temperature = random_between_03_and_08() if is_repat == True else 0.5q_res = getAnswerByContext(context=query_doc,question=real_question,query_len = len(contexts_unique_list),history = chat_historys_arr,# is_repat 时需要随机取值temperature =temperature)# 删除换行q_res_f = q_res.replace('\n', '。 ').replace('\r', '。 ')# 用模型推理下回答是否合理,不合理就重新执行本函数q_res_score = getAIQAIS(real_question, q_res_f) or "1.0"float_number = float(q_res_score)print("回答得分:", q_res_score)if float_number < 0.2:# 回答不合理,需要重新推理一次print(f"回答内容:{q_res_f}")print("回答不合理,需要重新推理一次")return main_bh(question, True)chat_historys_arr.append({ "role":"user", "content":real_question })chat_historys_arr.append({ "role":"assistant", "content":q_res_f })chat_historys_ai_use += f"助理: {q_res_f} \n"print("\n================结果========================")print("温度:", temperature)print(f"用户输入:{question}")print(f"主语增加:{real_question}")print("回答->:", q_res)print("========================================");return q_resdef serverChat(msg, history):return main_bh(msg)gr.ChatInterface(serverChat,retry_btn=None,undo_btn=None,clear_btn=None,description="胡言乱语时使用 /clear 指令清除会话").launch(share=True, debug = True)
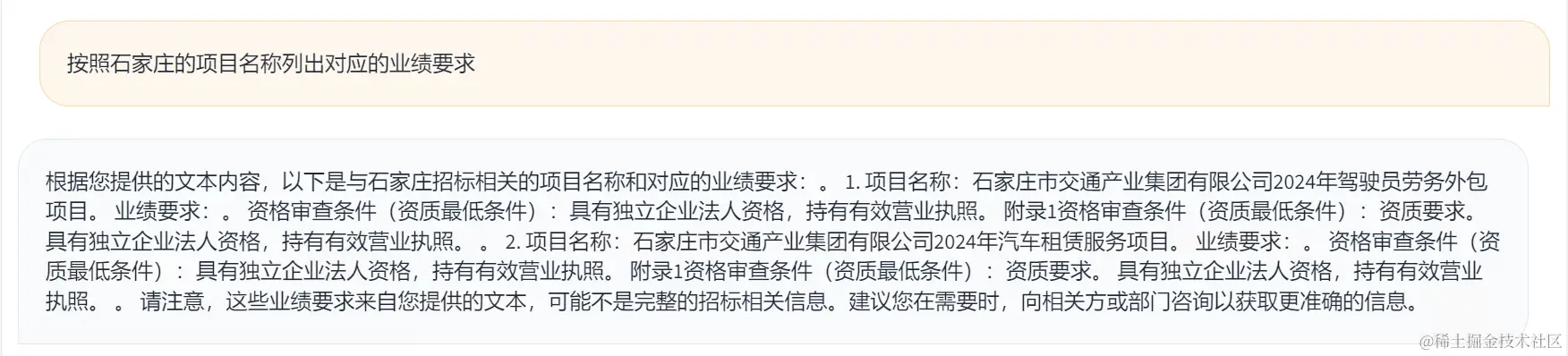
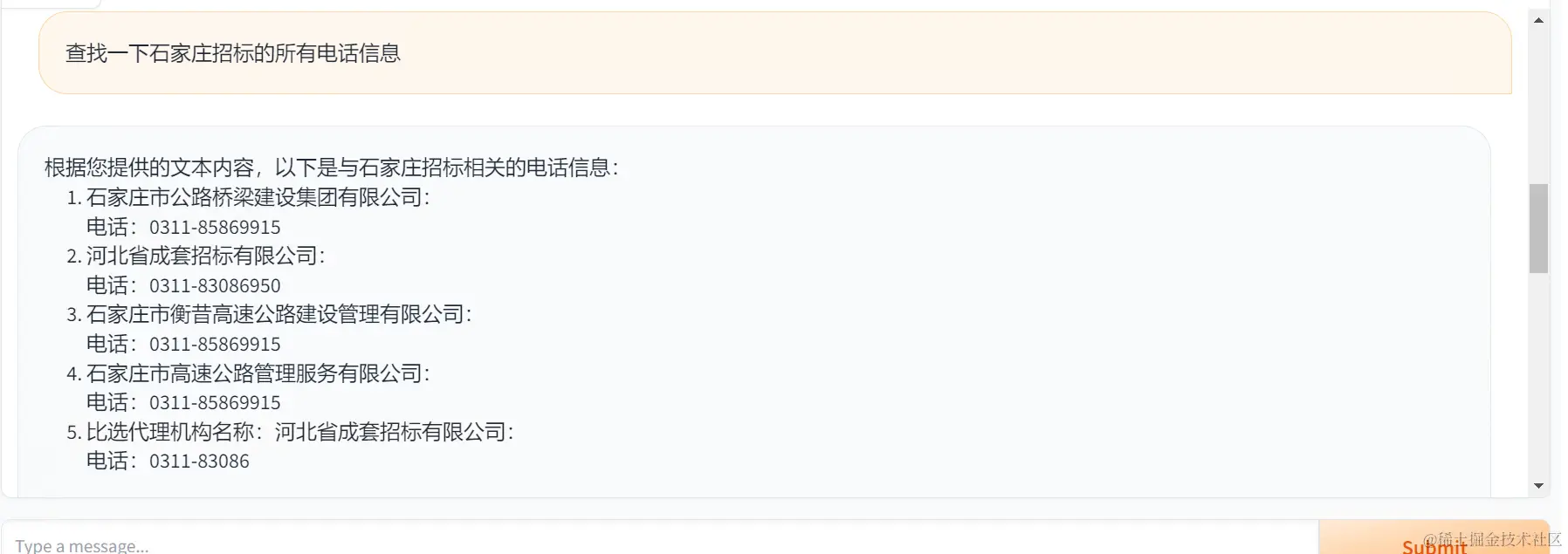
十七、最后效果


END
如果微调打分模型效果一定会更好。
如果每个步骤都使用不同的模型数一数要用多少个模型?
————————————————
版权声明:本文为稀土掘金博主「小明IO」的原创文章
原文链接:https://juejin.cn/post/7329860521241493515
如有侵权,请联系千帆社区进行删除
一、前言
模型既然会胡说八道那为啥不让模型在判断一下自己输出的是否正确呢?🤔
于是我产生了一个想法:提供一些条件让模型自己判断自己的推理是否正确✨本文以实现一个知识库为例,但是和其他的知识库有区别。
目前流行知识库如
Langchain-Chatchat只能回答检索到的内容,但是对内容的整理和总结的能力就很弱了。还有对一些上下文不是很连贯的内容推理也比较弱,比如招标文件等这种模板文件,多个文件格式都一样。只有标题和一些字段不同。
总结就是要实现能检索知识库和聊天并行。
下文代码将使用
python3 进行编码。并且在 google 实验室中进行。
二、实现思路
分为知识库整理和推理两个步骤:
三、依赖库下载:
- langchain 用来调用
llm 和embeddings
- chromadb 向量库
- gradio 超级方便的写
Ai 用的UI 库
- sentence_transformers HF提供的(调用抱脸的方法来使用模型)
!pip install --upgrade --quiet langchain langchain-community langchainhub chromadb bs4!pip install sentence_transformers!pip install gradio
四、模型下载
- text2vec-large-chinese (huggingface.co/GanymedeNil…)
- openchat (huggingface.co/openchat/op…)
根据测试,上面两个模型在中文环境下比较好用,而且部署
openchat (7B) 只需要使用一张 3090 即可。
text2vec-large-chinese用 gpu 的情况下 3G 左右的显存就够了。
因为使用的免费版的实验室,所以提供的
GPU 跑不起来这个模型。所以模型使用官方的 api,只有 embeddings 在实验室环境中跑。
!git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
五、依赖引入
先直接在顶部把要用到的依赖全部引入。
import osfrom langchain.chains import LLMChainfrom langchain.prompts import PromptTemplatefrom langchain import hubfrom langchain.vectorstores import Chromafrom langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitterfrom langchain.chains import RetrievalQAfrom langchain_community.document_loaders import TextLoaderfrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain_community.llms import HuggingFaceHubimport gradio as grimport reimport bs4import requestsimport random
六、openchat 模型接口调用
上面说了实验室环境中没法直接搭建
openchat 环境,所以只能写法方法调用线上接口了。 这个代码比较简单,直接使用 requests 来调用接口,传入对话内容和温度参数。
# @title openchat 模型接口调用函数def openchatGen(messages, prompt = " ", temperature = 0.5):API_URL = "https://openchat.team/api/chat"def query(payload):response = requests.post(API_URL,# headers={},json=payload)# print(response)return response.textoutput = query({"key": "","prompt": prompt, # 接口未处理这个参数"temperature": temperature,"model": {"id": "openchat_v3.2_mistral",# "id": "openchat_3","name": "OpenChat Aura","maxLength": 24576,"tokenLimit": 8192},"messages": messages or [# { "role": "user", "content": "xxx", }# { "role": "assistant", "content": "xxx", }# { "role": "system", "content": "xxx", }]})return output# 普通调用openchatGen_test1 = openchatGen([{"role": "user", "content": "你好"}])print(openchatGen_test1)# prompt 设置 | 多轮对话openchatGen_test2 = openchatGen([{"role": "user", "content": "你的名字叫大白,你喜欢吃饭。记住了吗?"},{"role": "assistant", "content": "好的,我记住了"},{"role": "user", "content": "你叫什么名字?"}])print(openchatGen_test2)
效果如下
七、加载文档
测试用文学作品形式的文档体验会很好,但是工作中那种文本会比较少。所以这里直接使用上下文都不怎么连贯的招标数据。
本文中文档使用 20 条招标数据。数据如下格式。
注:这些数据都是公开的,不是隐私数据。
直接调用
langchain 提供的加载文档和拆分文档的方法,非常的简单。只是注意参数需要调好即可。代码如下:
# @title 加载文档loader = TextLoader("./test.txt")document = loader.load()# 文档拆分text_splitter = CharacterTextSplitter(separator="",chunk_size=124,chunk_overlap=0,length_function=len,is_separator_regex=False,)org_texts = text_splitter.split_documents(document)# 竞标数据texts = []for item in org_texts:# 去除空格item.page_content = item.page_content.replace(" ","").replace(" ","")texts.append(item)
八、embeddings 模型环境搭建
老手的话可以看出来这里直接调用 HF 接口可能更简单。但是文档拆太细的话调用接口次数多就会噶!
模型路径是基于 google 实验室写的,自行根据情况更改即可。
# @title embeddings 模型使用,# 模型有些大必须用 GPU 跑,不然会卡住model_path = "/content/text2vec-large-chinese" # 根据条件改model_kwargs = {'device': 'cuda:0'} # 用一个gpu跑,根据条件改encode_kwargs = {'normalize_embeddings': False}embeddings = HuggingFaceEmbeddings(model_name=model_path,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs)text = "你好."query_result = embeddings.embed_query(text)print("emb len:", len(query_result))
测试效果
九、将文本转换为向量
还是使用 langchain 集成的向量库 Chroma 将文本转为向量数据。
检索方法下面代码中写了三种,实际上第一种默认的就够用了,当第一种效果不佳时可以尝试下另外两种。
# @title 使用 embedding engion 将 text 转换为向量db = Chroma.from_documents(texts,embeddings,# 可以存起来,下次就不用做这个操作了# persist_directory="/content/chroma_db")# 默认检索retriever = db.as_retriever()# 只搜索最匹配的一条# retriever = db.as_retriever(search_kwargs={'k': 1})# 稍微严格些# retriever = db.as_retriever(# search_type="mmr",# # search_kwargs={'k': 5, 'fetch_k': 80}# search_kwargs={'fetch_k': 90}# )
十、将用户输入转为更有利于 embeddings 检索的语句
用户和机器人对话时候往往不是以关键词的方式进行,而向量数据库是需要用到关键词的。所以需要将用户的语句中的关键词转一下,不然检索效果往往太依赖于用户的提问技巧。所以这个步骤非常有必要。
下面用
prompt 来让 llm 帮我们做这个事情。其实只要 prompt 写得准确,llm 给我们的答案还是不错的。
# @title 将用户输入转为更有利于 embeddings 检索的语句def getAIQuestion(userQuestion):# 改为使用接口方式请求template = """ 原始语句:{context} \n帮我转换为更适合Embedding模型检索的语句 """prompt = PromptTemplate(template=template, input_variables=["context"])prompt_text = prompt.format(context=userQuestion)# prompt 设置 | 多轮对话res = openchatGen([{"role": "user", "content": "你只负责把语义转换为更适合Embedding模型检索的语句,注意不是翻译句子,并不能和用户对话。当用户语义没有问题时不做处理"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": "原始语句:小桂子胎记在哪? \n帮我转换为更适合Embedding模型检索的语句"},{"role": "assistant", "content": "小桂子胎记位置"},{"role": "user", "content": "原始语句:谁是疯子? \n帮我转换为更适合Embedding模型检索的语句"},{"role": "assistant", "content": "疯子的名字"},{"role": "user", "content": prompt_text }], temperature=0.4)return res# 测试test_arr_1 = ["帮我搜索一下2024年有哪些比选信息","微订饮水机招标信息的联系人告诉我","你好"]for item in test_arr_1:res = getAIQuestion(item)print(f"=== {item} -> {res}")
十一、测试向量库的检索
有了上面的
getAIQuestion 方法,现在我们来测试一下检索效果。
# @title 向量库检索测试questionTest = "生产性耗材的招标有吗?"questionTest_ai = getAIQuestion(questionTest)print("原始:", questionTest)print("AI:", questionTest_ai)retrieved_docs_ai = retriever.invoke(questionTest_ai)print("测试结果:", len(retrieved_docs_ai))print("\n")print("\n---------------- AI ------------\n")for item in retrieved_docs_ai:print(item)
结果不是那么丰富,因为是从库里匹配出来的知识片段,还需要给
LLM 整理才行。
十二、获取一轮对话的相关性得分 返回 0 - 1 的浮点数
怎么保证 LLM 不会答非所问,这就得写另一个方法来控制了。下面这个方法对比一轮对话是否是有关联,给关联性打个分。因为直接判断是或者不是的情况并不会很准确,但是打分的话咋们自己控制一下阈值会得到很好的效果。
# @title 获取一轮对话的相关性得分 返回 0 - 1 的浮点数# 一般大于 0.3 就有一定的相关性了def getAIQAIS(question, answer):template = """<question>{question}</question><answer>{answer}</answer>"""prompt = PromptTemplate(template=template, input_variables=["question", "answer"])prompt_text = prompt.format(question=question, answer=answer)# prompt 设置 | 多轮对话res = openchatGen([{"role": "user", "content": "我会把一轮对话分别放到<question></question>和<answer></answer>标签中,你需要分析一下两个句子的相关性得分,第二句是不知道的意思也需要给高分,因为也算是对第一句的回答,只要两句话有关联得分就需要大于 0.5, 得分范围 0 - 1。仅仅告诉用户得分即可,不用发送其他语句。"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": "<question>兰姨娘非常的美吗?</question><answer>是的兰姨娘很美。</answer>"},{"role": "assistant", "content": "0.99"},{"role": "user", "content": "<question>德先生为什么很奇怪?</question><answer>因为他是一个妖怪</answer>"},{"role": "assistant", "content": "0.6"},{"role": "user", "content": "<question>小米为啥打不过大米?</question><answer>我刚刚吃完饭</answer>"},{"role": "assistant", "content": "0.01"},{"role": "user", "content": prompt_text},], temperature=0.4)return res# 测试test_arr = [{"question": "小明几岁了?","answer":"小明15岁了。"},{"question": "在做什么呢?","answer":"在吃饭。"},{"question": "奥特曼会打未成年的怪兽吗?","answer":"这个问题我也不知道。"},{"question": "小红年年第一名?","answer":"那她可真厉害!"},{"question": "查一下2024年有哪些名人?","answer":"今天的饭难吃极了!"},{"question": "明天会更好吗?","answer":"小红打了小明!"},{"question": "告诉我蜘蛛侠和哈利波特什么关系","answer":"我吃了一大个披萨"},{"question": "白素贞为什么被压在雷峰塔下面?","answer":"因为白素贞是一个妖怪!"}]for item in test_arr:res2 = getAIQAIS(item["question"], item["answer"].replace("\n", ""))res2t = res2.replace("\n", "").replace(" ", "")print(f"=== {item} -> {res2t}")
十三、获取两句话的相关性得分 返回 0 - 1 的浮点数
在知识库对话中,如果想实现对轮对话得咋们需要做两件事,
首先要明确用户提问的句子中的目标是什么?比如用户问 联系人电话号码是什么? 那需要先推理出用户问的是公司还是个人或者是哪个公司哪个人的电话号码。
完成上一步后得到的答案难道一定正确吗?不!LLM 根据一堆对话内容推理出来的结果一点也不可信。所以这时候需要保证 LLM 没有瞎说。所以需要再写一个打分函数来让第一步变的可靠。
# @title 获取两句话的相关性得分 返回 0 - 1 的浮点数# 一般大于 0.3 就有一定的相关性了def getAIQsIS(question1, question2):template = """<question1>{question1}</question1><question2>{question2}</question2>"""prompt = PromptTemplate(template=template, input_variables=["question1", "question2"])prompt_text = prompt.format(question1=question1, question2=question2)# prompt 设置 | 多轮对话res = openchatGen([{"role": "user", "content": "我会把两个问句分别放到<question1></question1>和<question2></question2>标签中,你需要分析一下两个句子的相关性得分,只要两句话都是问的相同的问题得分就需要大于 0.5, 得分范围 0 - 1。仅仅告诉用户得分即可,不用发送其他语句。"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": "<question1>小红是这个项目的负责人吗?</question1><question2>京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的小红是这个项目的负责人吗?</question2>"},{"role": "assistant", "content": "0.5"},{"role": "user", "content": "<question1>比选什么时候开始?</question1><question2>比选什么时候开始?</question2>"},{"role": "assistant", "content": "0.99"},{"role": "user", "content": "<question1>明年棒球赛的冠军你猜会是谁?</question1><question2>小明联系地址在哪?</question2>"},{"role": "assistant", "content": "0"},{"role": "user", "content": prompt_text},], temperature=0.5)return res.replace("\n", "").replace(" ", "")# 测试test_arr_getAIQsIS = [{"question1": "对公司有什么要求吗?","question2":"京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目的联系地址在哪?"},{"question1": "对公司有什么要求吗?","question2":"京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目的比选对公司有什么要求?"},{"question1": "小明叫什么名字?","question2":"微订科技的员工小明叫什么名字?"},{"question1": "他说昨天是周一吗?","question2":"海伦问昨天是周一吗?"},{"question1": "英子住在哪里?","question2":"海伦住在哪里?"},]for item in test_arr_getAIQsIS:res2 = getAIQsIS(item["question1"], item["question2"].replace("\n", ""))print(f"=== {item} -> {res2}")
十四、根据对话让模型推理出用户问题相对的目标(一般是名词)
这个判断会比较复杂,因为对话中可能涉及多个目标名词,需要明确让 LLM 提取最近的目标。所以会写比较多的
prompt 才行。而且拿到的结果不一定会准确,所以需要用到上面写的打分函数getAIQsIS来打一分,分数过低就重新推理一遍。
def random_between_03_and_08():"""生成介于 0.3 和 0.8 之间的随机浮点数,保留一位小数精度需要调整,不要随机,按循序走一遍就行..."""random_number = random.uniform(0.3, 0.8)rounded_number = round(random_number, 1)return rounded_number# @title 根据对话让模型推理出用户问题相对的目标(一般是主语/名词)def getAISubject(question, context, max_repeat = 10):_max_repeat = max_repeat# 具体推理逻辑def doFn(temperature = 0.6):template = """记住这段对话,我会问你一些问题。 {context}"""prompt = PromptTemplate(template=template, input_variables=["context"])prompt_text = prompt.format(context=context)print("主语推理 prompt_text:", prompt_text)# prompt 设置 | 多轮对话res = openchatGen([{"role": "user", "content": "根据对话内容,如果用户最后的句子缺少目标名称,则需要添加它。目标可以是一个公司,一个人,等等。如果你不知道目标是什么,直接回复\"用户\"问题的内容就行,不要回复任何与用户的句子不相关的东西,不能更改用户问题的原本意思。"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 变压器日常维护采购项目相关的竞标有吗? \n助理: 是的,有关于变压器日常维护采购项目的竞标信息。您之前提供的信息中提到了一项名为“京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目”的竞标项目。 \n用户: 联系人是谁? \n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "“京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目”的竞标项目联系人是谁?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 变压探伤仪配件采购相关的比选信息有吗? \n助理: 1. 项目名称:石家庄市轨道交通集团有限责任公司运营分公司2023年度探伤仪配件采购项目比选公告。 \n1.1 项目编号:SJZXJT-HWBX-202001 \n1.2 服务内容:探伤仪配件采购项目, \n用户: 联系人是谁? \n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "石家庄市轨道交通集团有限责任公司运营分公司2023年度探伤仪配件采购项目比选”的竞标项目联系人是谁?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 今年小红怎么样?\n助理: 小红非常的好。\n 用户: 今年小红打电话给小米了吗?\n助理: 是的已经打了。 \n用户: 小明吃饭了吗?\n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "小明吃饭了吗?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 联系电话是18216811014的比选项目名称叫什么?\n助理: 没找到呢。\n用户: 那这个联系电话是谁的?\n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "18216811014这个联系电话是谁的?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的联系人是谁? \n助理: hi \n用户: 联系人是谁 \n助理: hi \n用户: 内容概括下 \n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的内容概括下"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 2024年安全设备规则库升级采购项目比选有吗?\n助理: “石家庄市京昆石太高速公路管理服务有限公司2024年安全设备规则库升级采购项目比选\" 为你找到了这个信息。\n用户: 属于什么行业的?\n助理: 铁路运输业。 \n用户: 比选什么时候开始? \n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "“石家庄市京昆石太高速公路管理服务有限公司2024年安全设备规则库升级采购项目比选\"什么时候开始开始?"},{"role": "user", "content": "记住这段对话,我会问你一些问题。\n 用户: 京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的联系人是谁? \n助理: 根据提供的文本内容,比选人名称为:石家庄市京昆石太高速公路管理服务有限公司。联系人:杨工。电话:0311-85869915。 \n用户: 代理机构的联系方式呢\n "},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},{"role": "assistant", "content": "京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目的代理机构的联系方式呢"},{"role": "user", "content": prompt_text},{"role": "assistant", "content": "好的,我记住了。"},{"role": "user", "content": "将内容中的目标名称补充到 \"用户\" 最后提问的句子中给我。"},], temperature = temperature)return resres = doFn()# 正确性判断res2 = getAIQsIS(question, res)while float(res2) < 0.3 and _max_repeat > 0:temperature = random_between_03_and_08()print("\n\n",question, " -> ", res)print("得分过低,需要重新推理。当前得分:", res2)print("下一次推理温度:", temperature)res = doFn(temperature)res2 = getAIQsIS(question, res)_max_repeat -= 1return res# 测试test_arr_getAISubject = [{"question": "这个项目的比选范围说一下。","context": """用户: 京昆石太高速2024年供电(外电)线路及变压器日常维护采购项目比选的联系人是谁?助理: 根据您提供的文本内容,比选人名称为:石家庄市京昆石太高速公路管理服务有限公司。联系人:杨工。电话:0311-85869915。比选代理机构名称:河北省成套招标有限公司。地址:河北省石家庄市工农路486号。联系人:孟凡真、尉思源。 电话:0311-83086950用户: 比选内容概括下"""},]test_index = 1for item in test_arr_getAISubject:question = item["question"]context = item["context"]res = getAISubject(question, context)print(f"{test_index}. {question} -> {res}")test_index+=1
十五、从上下文中推理出答案的方法封装
写完了上面的那些方法后就进入了正题了,把检索到的知识碎片和用户的问题全部给到 LLM。让其推理。为了后面的使用,这里先封装一个输入输出函数。
这里封装很有必要,因为一次对话如果打分过低可能会被调用多次推理。
def getAnswerByContext(context, question, query_len, history=[], temperature = 0.6):# template = """根据用户的问题,从知识库中检索出来了 {query_len} 条相关信息,下面是具体内容:\n{context} \n 请根据内容回答用户问题,务必告诉用户从知识库中检索出来了多少条相关信息。"""# template = """记住这段内容,我有些问题要问你,请根据这段内容对我的问题进行回答,下面是具体内容:\n\n\n检索到相关信息共 {query_len} 条。\n \n{context}"""template = """<text>从知识库中检索出来了 {query_len} 条相关信息,下面是具体内容:\n{context}</text>"""prompt = PromptTemplate(template=template, input_variables=["context", "query_len"])prompt_text = prompt.format(context=context, question = question, query_len = query_len)messages = [{"role": "user", "content": "我会把一段文本放到<text></text>标签中,你需要根据标签中的内容对用户提出的问题进行回答,所有的回答必须参照标签中的内容。"},{"role": "assistant", "content": "好的。"},{"role": "user", "content": prompt_text},{"role": "assistant", "content": "请提出您的问题吧,我会根据内容对您的问题进行回复。"},] + history + [{"role": "user", "content": question}]res = openchatGen(messages, temperature=temperature)return res# 测试test_arr4 = [{"question": "小明认识小红吗?","context":"小红是一名三年级的学生,每次考试都第一名,成绩非常的好。"},{"question": "小红几年级?","context":"小红是一名三年级的学生,每次考试都第一名,成绩非常的好。"}]for item in test_arr4:res2 = getAnswerByContext(context=item["context"], question=item["question"], query_len = 1)print(f"=== {item} -> {res2}")
十六、闭环推理
这是整个程序的最后一步了,只需要 推理->打分->输出 即可,
# @title 闭环(结合向量数据库 + AI 微调检索句 + + AI 完善主语)query_doc = ""# 对话历史chat_historys = ""chat_historys_arr = []chat_historys_ai_use = "\n"# gr 自带的history暂时不用...# is_repat 是否是重新回答def main_bh(question, is_repat = False):global query_doc, chat_historys, chat_historys_ai_use, chat_historys_arr# max_repeat 最多尝试多少次推理_max_repeat = 5# print(question)# 特殊指令if question == "/clear":chat_historys = ""chat_historys_ai_use = ""chat_historys_arr = []print("清理会话完毕!")return "清理会话完毕!"print("\n\n\n\n**************************************")_question = questiondef format_docs(docs):# 文学作品需要去除换行等符号会更准确# pt = "\n\n".join(doc.page_content for doc in docs).replace("\n", "").replace(" ", "")# 比选数据pt = "\n\n".join(doc.page_content for doc in docs)return ptreal_question = ""# print("is_repat", is_repat)if is_repat != True:chat_historys_ai_use += f"用户: {_question} \n"# 让模型完整用户语义# if len(chat_historys_arr) > 0 and is_repat == False:if len(chat_historys_arr) > 0:real_question = getAISubject(_question, chat_historys_ai_use) or _question# print('目标推理内容:', chat_historys_ai_use)print('目标推理结果:', real_question)else:real_question = _question# 检索内容需要去重# 用模型处理一遍语义再进行向量数据库搜索retrieved_docs = retriever.invoke(getAIQuestion(real_question))contexts = retrieved_docs;contexts_unique_list = []for item in contexts:if item not in contexts_unique_list:contexts_unique_list.append(item)# 最多只要一条数据,但是总数可以告诉llm ing...cur_query_context = format_docs(contexts_unique_list)query_doc = cur_query_contextprint("\n=================知识库=======================")print("检索到数量:", len(contexts_unique_list))for item in contexts_unique_list:print(item)print("========================================");temperature = random_between_03_and_08() if is_repat == True else 0.5q_res = getAnswerByContext(context=query_doc,question=real_question,query_len = len(contexts_unique_list),history = chat_historys_arr,# is_repat 时需要随机取值temperature =temperature)# 删除换行q_res_f = q_res.replace('\n', '。 ').replace('\r', '。 ')# 用模型推理下回答是否合理,不合理就重新执行本函数q_res_score = getAIQAIS(real_question, q_res_f) or "1.0"float_number = float(q_res_score)print("回答得分:", q_res_score)if float_number < 0.2:# 回答不合理,需要重新推理一次print(f"回答内容:{q_res_f}")print("回答不合理,需要重新推理一次")return main_bh(question, True)chat_historys_arr.append({ "role":"user", "content":real_question })chat_historys_arr.append({ "role":"assistant", "content":q_res_f })chat_historys_ai_use += f"助理: {q_res_f} \n"print("\n================结果========================")print("温度:", temperature)print(f"用户输入:{question}")print(f"主语增加:{real_question}")print("回答->:", q_res)print("========================================");return q_resdef serverChat(msg, history):return main_bh(msg)gr.ChatInterface(serverChat,retry_btn=None,undo_btn=None,clear_btn=None,description="胡言乱语时使用 /clear 指令清除会话").launch(share=True, debug = True)
十七、最后效果
END
如果微调打分模型效果一定会更好。
如果每个步骤都使用不同的模型数一数要用多少个模型?
————————————————
版权声明:本文为稀土掘金博主「小明IO」的原创文章
原文链接:https://juejin.cn/post/7329860521241493515
如有侵权,请联系千帆社区进行删除
评论
![preview]()
发表评论
