AI大模型学习笔记之二:什么是 AI 大模型的训练和推理?
大模型开发/技术交流
- LLM
- 大模型训练
3月14日7041看过
在人工智能(AI)的领域中,我们经常听到训练(Training) 和 推理(Inference) 这两个词汇,它们是构建强大 AI 模型的关键步骤。我们通过类比人类的学习过程来理解这两个概念,可以更加自然而生动地理解AI大模型的运作原理。
想象一下,当一个人类宝宝刚刚降临人间,还没开始学会说话,但是已经开始了对周围生活环境的观察和学习,在这个早期的学习阶段,婴儿周围会有很多人类语言输入,包括听到医生、护士、母亲和家人的对话、感知周围的环境,甚至是听音乐和观看视频。这个过程就像AI大模型的初始训练,大模型通过海量的数据输入来学习人类自然语言的规律和模式。
随着时间的推移,婴儿开始渐渐模仿和理解大人说的话,逐渐掌握了发出有意义的声音和词汇。这类似于人工智能在经过海量的数据训练后构建了一个具有理解和预测能力的模型,模型的参数就像是婴儿学习过程中不断调整和学习的语言能力。

当婴儿逐渐长大学会说话后,他们就可以和父母进行日常对话,理解意思并表达自己的感受和想法,产生了自己的语言。这阶段类似于AI大模型的推理,模型能够对新的语言和文本输入进行预测和分析。婴儿通过语言能力表达感受、描述物体和解决各种问题,这也类似于AI大模型在完成训练投入使用后在推理阶段应用于各类特定的任务,例如图像分类、语音识别等。
通过这个简单而贴近生活的类比,我们可以更加自然地理解AI大模型的训练和推理过程。就像人类学习语言一样,AI大模型通过大量数据的学习和模仿,逐渐构建起丰富而高效的模型,为解决各种实际问题提供了强大的工具。在这个学习过程中,我们更能感受到人工智能与人类学习的共通之处。
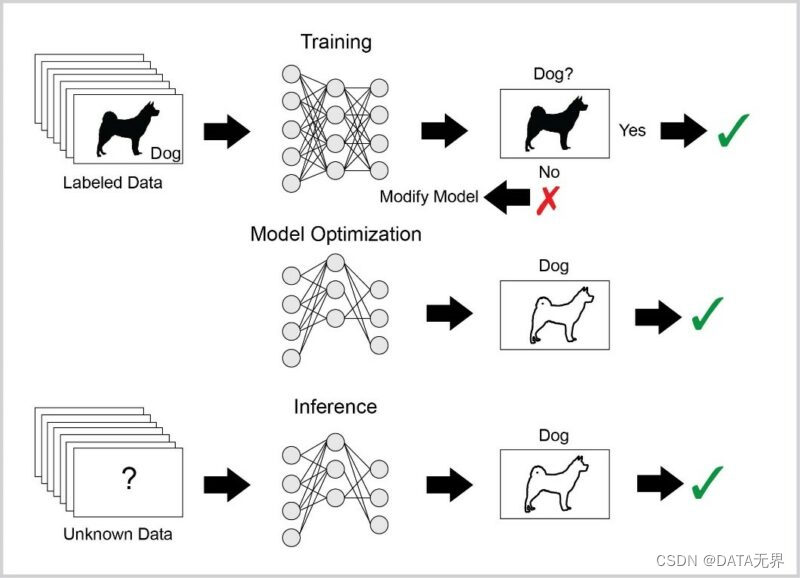
训练(Training)和推理(Inference)是AI大模型两个核心能力的基石。
在训练(Training)阶段,通过大量数据和算法,AI模型学会识别和生成规律。模型参数在此过程中不断调整,以最小化预测与实际值之间的误差,从而使其具备适应各种任务的学习能力,涵盖图像识别到自然语言处理等多个领域。
在训练阶段,大模型通过深度学习技术,通过多层神经网络,对接收输入的海量数据进行学习和优化,并通过学习调整模型的参数,使其能够对输入数据进行准确的预测。
这通常涉及到使用反向传播算法和优化器来最小化模型预测与实际标签之间的误差。为了提高模型的性能,一般需要使用大规模的数据集进行训练,以确保模型能够泛化到各种不同的情况。
这种学习方式,使得AI模型能够从数据中自动提取特征,进而实现对数据的自适应分析和处理。同时,AI大模型还采用了迁移学习技术,将已经在其他任务上训练好的模型,迁移到新的任务中,大大提高了训练效率。
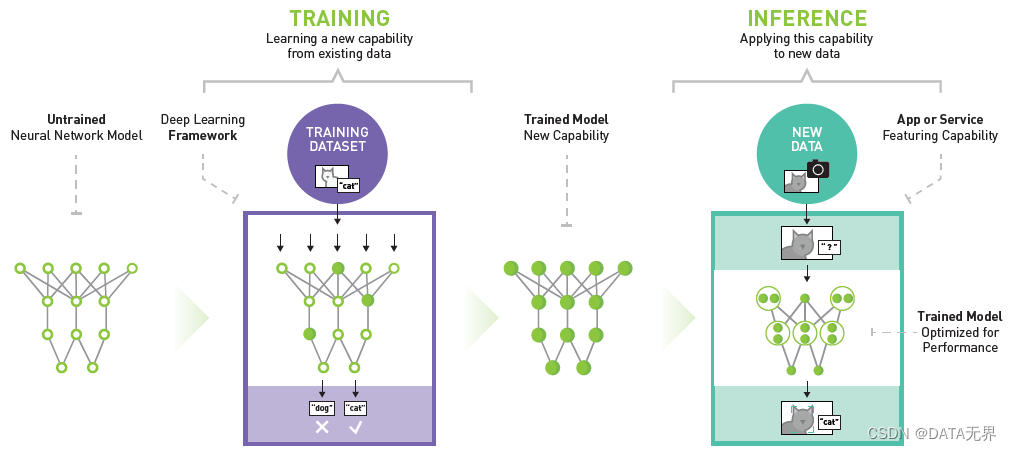
推理(Inference)阶段则建立在训练完成的基础上,将训练好的模型应用于新的、未见过的数据。模型利用先前学到的规律进行预测、分类或生成新内容,使得AI在实际应用中能够做出有意义的决策,例如在医疗诊断、自动驾驶和自然语言理解等领域。
在推理阶段,训练好的模型被用于对新的、未见过的数据进行预测或分类。大型模型在推理阶段可以处理各种类型的输入,并输出相应的预测结果。推理可以在生产环境中进行,例如在实际应用中对图像、语音或文本进行分类,也可以用于其他任务,如语言生成、翻译等。
这两个关键能力的有机结合使得AI模型成为企业数据分析和决策的强大工具。
通过训练,模型从历史数据中提取知识;
通过推理,将这些知识应用于新场景,从而做出智能决策。
这强调了数据的关键作用,因为高质量的训练数据对确保模型性能和泛化能力至关重要。
下面我们以一个图像分类任务为例简要说明大模型的训练和推理过程:
假设我们要训练一个卷积神经网络(CNN)模型来对猫和狗的图片进行分类。
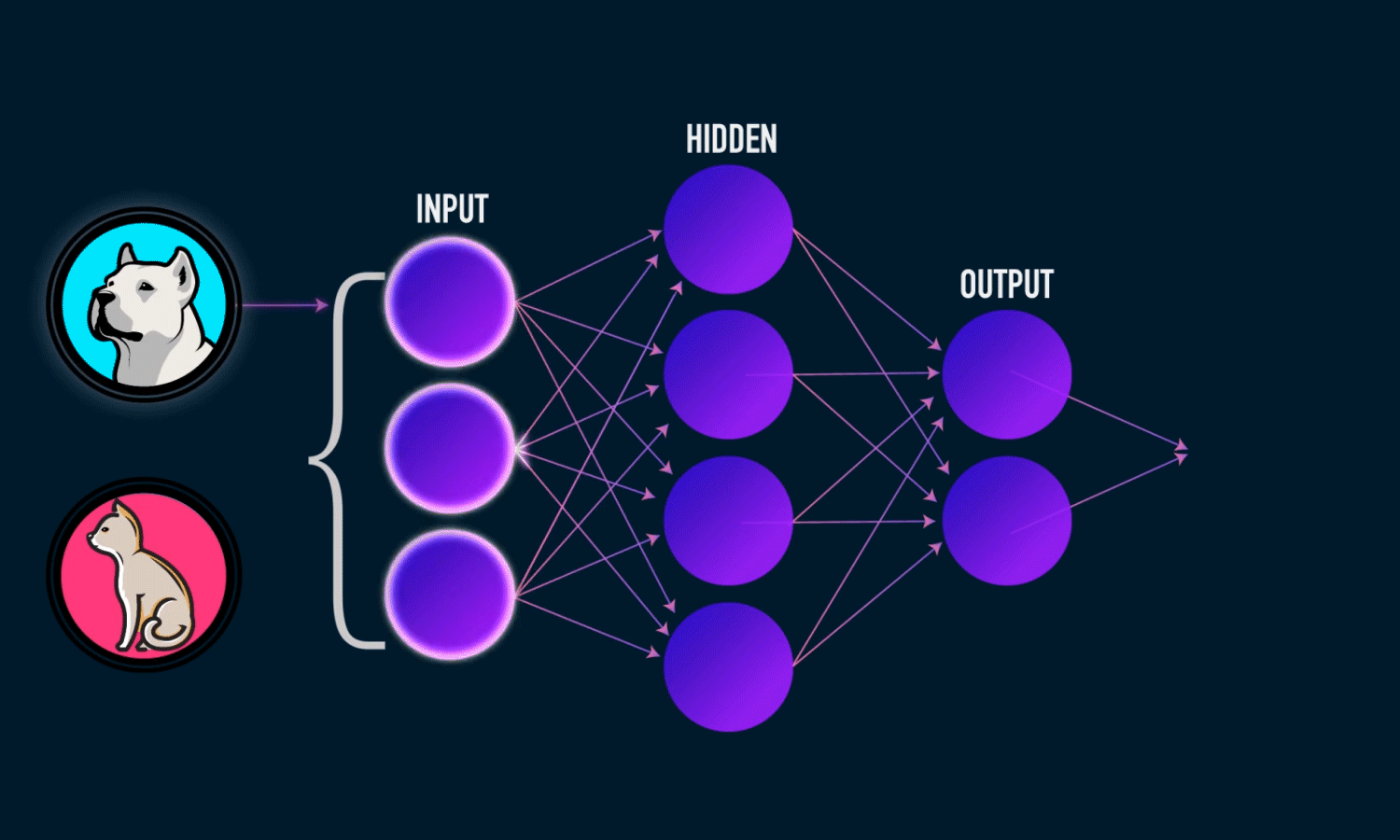
训练过程:
首先,我们需要构建一个庞大而多样的数据集,其中包含了大量标记有猫和狗的图像,以确保模型能够学到各种猫狗的特征。
接下来,我们选择深度学习框架(例如TensorFlow或PyTorch)来构建我们的卷积神经网络(CNN)模型。在这个例子中,我们可以借助预训练的CNN模型,并在其基础上添加一些自定义的层,以使其适应我们的猫狗分类任务。定义损失函数(比如交叉熵损失)和优化器(例如随机梯度下降SGD)是训练的基础。
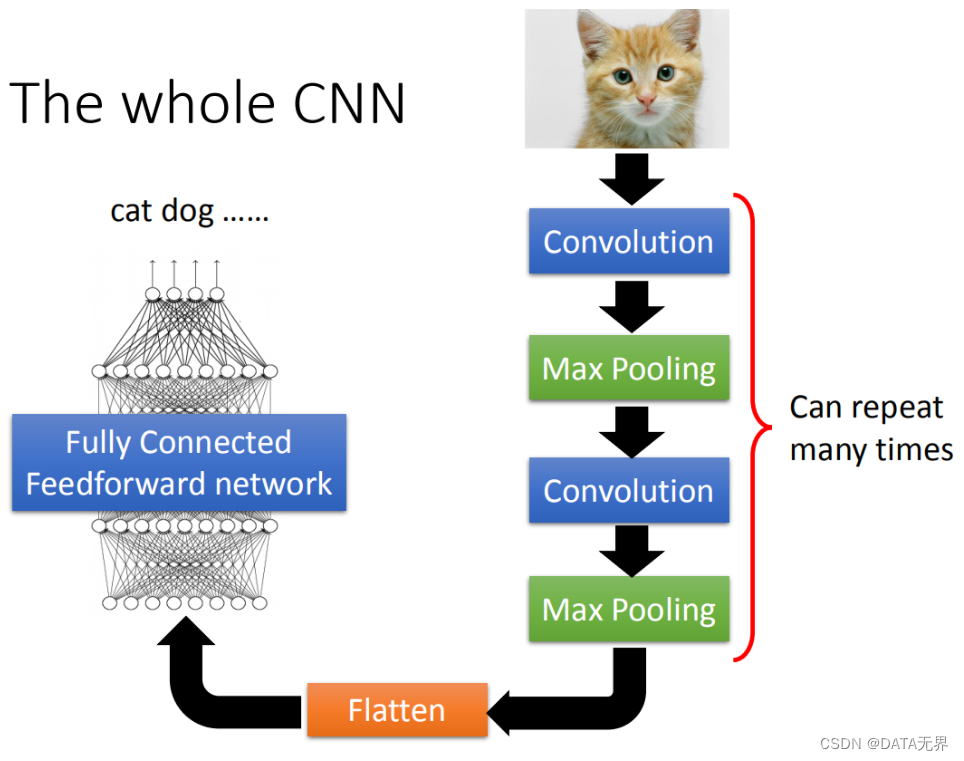
接着将整个数据集分成训练集和验证集,训练集用于更新模型的参数,验证集用于评估模型的性能。通过将训练集输入到模型中,进行前向传播和反向传播,不断地更新模型参数以提高性能。通过监控验证集的表现,我们可以调整超参数,确保模型能够在未见过的数据上泛化。
经过多轮迭代后,当模型达到满意的性能水平时,我们保存模型以备后续的推理使用。
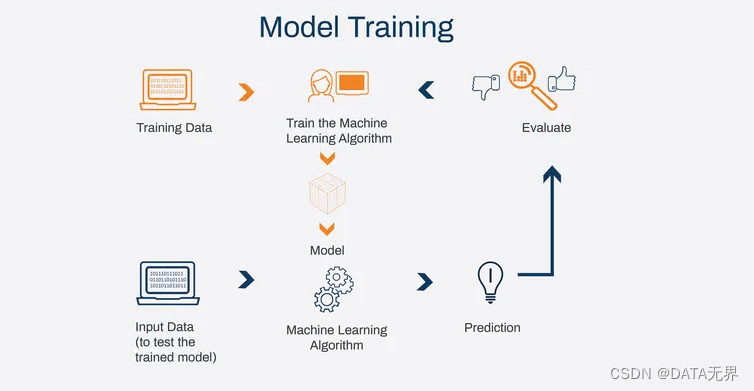
推理过程:
在推理过程中,我们需要对新的、未见过的图像进行分类。
首先,我们加载之前训练好的模型,包括保存的模型参数和结构。
然后,将新的图像输入到模型中进行前向传播,得到模型的输出结果。这个输出结果通常是对每个类别的分数或概率。
通过应用softmax函数,我们将这些分数转换为表示每个类别概率的分布。这使得我们可以知道图像属于每个类别的可能性有多大。
最后,我们选择具有最高概率的类别作为模型的最终预测结果。这就是我们的模型根据学到的特征和规律对新图像进行分类的过程。
在整个训练和推理的过程中,我们可能会面临一些挑战,比如过拟合问题。为了解决这些问题,我们可以采用正则化技术,如L1、L2正则化或dropout,来限制模型的复杂性。此外,通过数据增强技术,如图像的旋转、缩放、翻转等,我们可以扩充训练数据集,提高模型的泛化能力。
在实际应用中,了解并处理这些挑战是确保模型在各种情况下表现良好的关键。
————————————————
版权声明:本文为CSDN博主「DATA无界」的原创文章
原文链接:https://blog.csdn.net/GYN_enyaer/article/details/135604368
如有侵权,请联系千帆社区进行删除
评论
