 发布话题
发布话题大模型剪枝技术原理(一)-概述
大模型开发/技术交流
- LLM
2024.04.154541看过
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,从而导致模型变得越来越大,因此,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。而大模型压缩主要分为如下几类:
-
模型剪枝(Pruning)
-
知识蒸馏(Knowledge Distillation)
-
模型量化(Quantization)
-
低秩分解(Low-Rank Factorization)
本文将针对当前大模型剪枝相关的一些工作进行讲述。
剪枝简介
模型剪枝(Model Pruning)是一种用于减少神经网络模型参数数量和计算量的技术。它通过识别和去除在训练过程中对模型性能影响较小的参数或连接,从而实现模型的精简和加速。
通常,模型剪枝可以分为两种类型:结构化剪枝(Structured Pruning)、非结构化剪枝(Unstructured Pruning)。
结构化剪枝和非结构化剪枝的主要区别在于剪枝目标和由此产生的网络结构。结构化剪枝根据特定规则删除连接或层结构,同时保留整体网络结构。而非结构化剪枝会剪枝各个参数,从而产生不规则的稀疏结构。
模型剪枝的一般步骤包括:
-
训练初始模型:首先,需要训练一个初始的大模型,通常是为了达到足够的性能水平。
-
评估参数重要性:使用某种评估方法(如:权重的绝对值、梯度信息等)来确定模型中各个参数的重要性。
-
剪枝:根据评估结果,剪枝掉不重要的参数或连接,可以是结构化的或非结构化的。
-
修正和微调:进行剪枝后,需要进行一定的修正和微调,以确保模型的性能不会显著下降。
模型剪枝可以带来多方面的好处,包括减少模型的存储需求、加速推理速度、减少模型在边缘设备上的资源消耗等。然而,剪枝可能会带来一定的性能损失,因此需要在剪枝前后进行适当的评估和调整。
下面来探讨一些将LLMs与剪枝技术相结合的方法,旨在解决LLMs巨大尺寸和计算成本的问题。
非结构化剪枝方法
非结构化剪枝通过删除特定参数而不考虑其内部结构来简化 LLM。这种方法针对 LLM 中的单个权重或神经元进行,通常通过将阈值以下的参数归零。但是此方法忽略了 LLM 整体结构,导致不规则的稀疏模型,这种不规则性需要专门的压缩技术来有效存储和计算剪枝后的模型。
非结构化修剪通常涉及对 LLM 进行大量重新训练以重新获得准确性,这对于LLMs来说尤其昂贵。该领域的一种创新方法是 SparseGPT(论文:SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot)。它引入了一种不需要重新训练的一次性剪枝策略。该方法将剪枝视为广泛的稀疏回归问题,并使用近似稀疏回归求解器对其进行求解。 SparseGPT 实现了显著的非结构化稀疏性,在 OPT-175B 和 BLOOM-176B 等大模型上甚至高达 60%,而困惑度的增加很小。
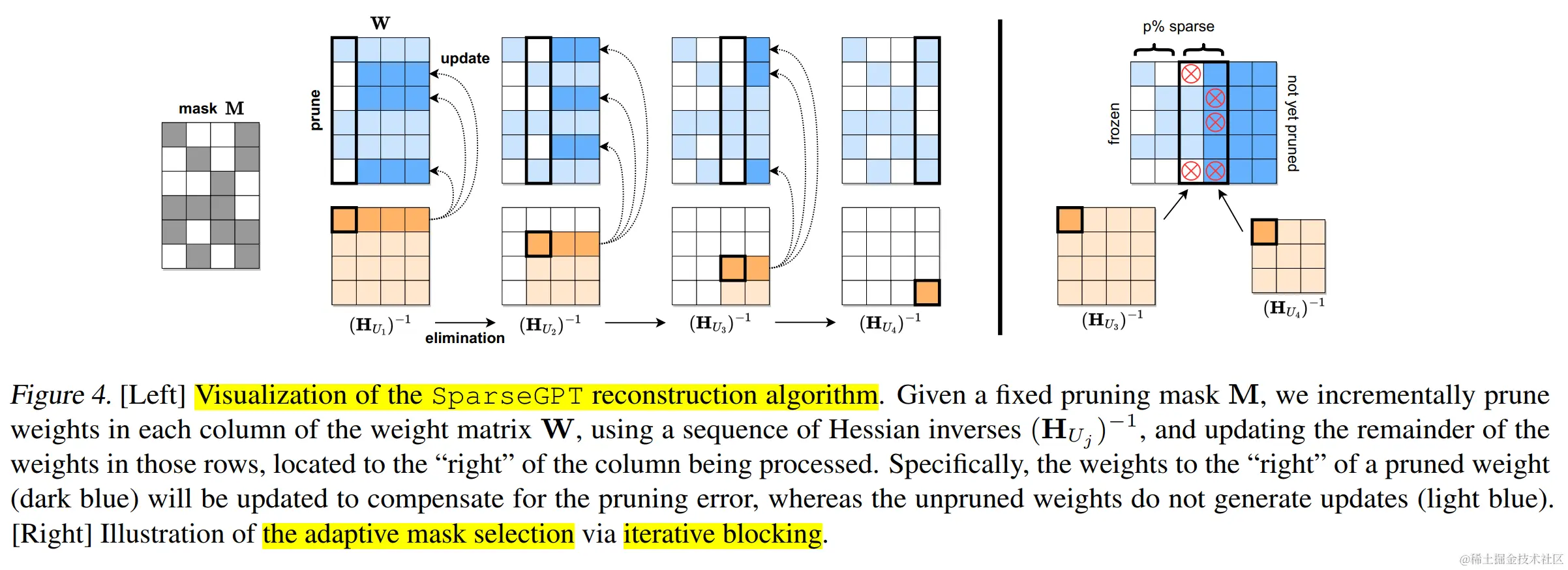
与此相反,Syed 等人[Syed et al., 2023]提出一种迭代剪枝技术,在剪枝过程中以最少的训练步骤微调模型。
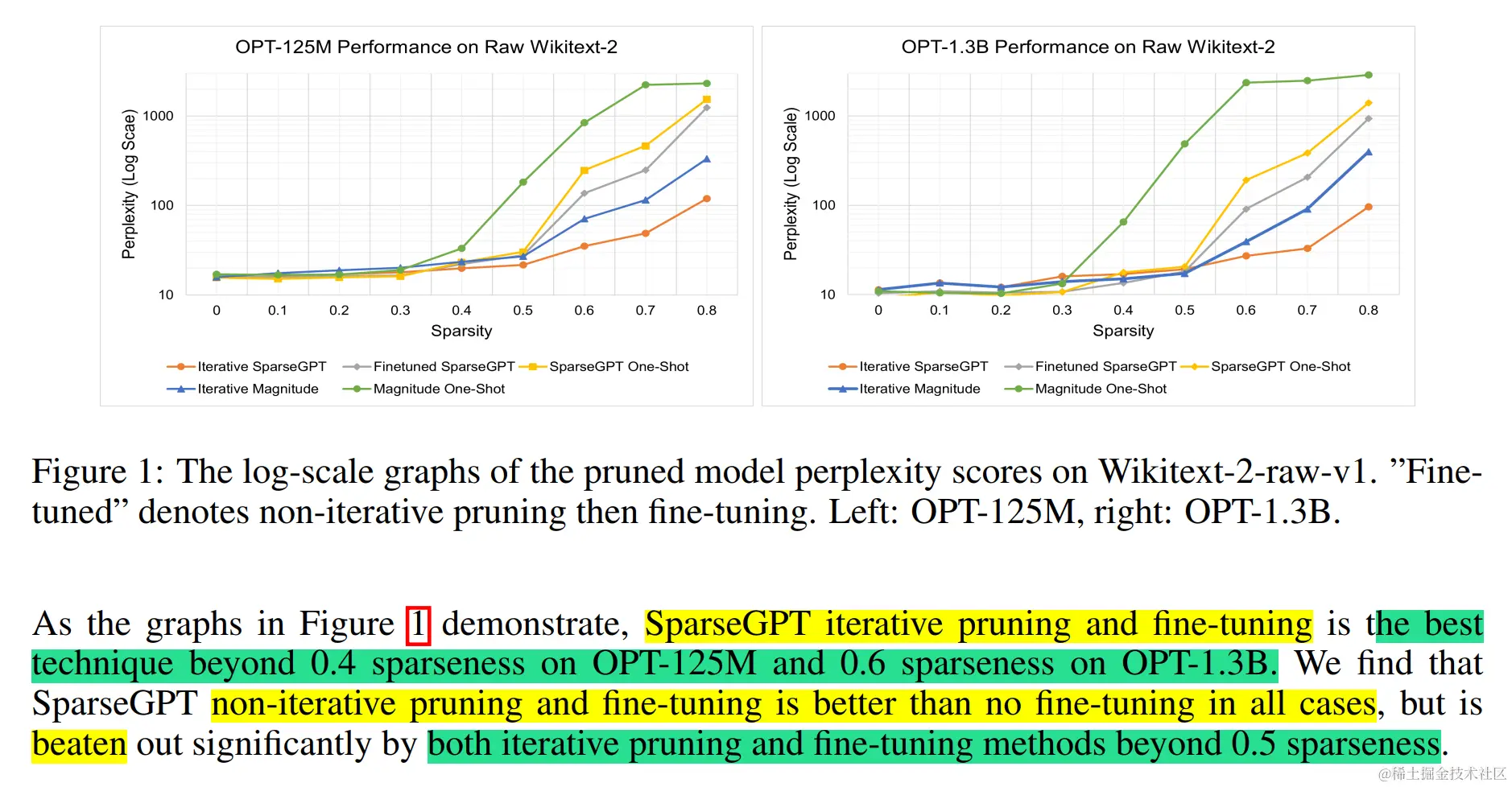
另一个优化是 LoRAPrune(论文:LoRAPrune: Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning),它将参数高效调整 (PEFT) 方法与剪枝相结合,以增强下游任务的性能。它引入了一种独特的参数重要性标准 [Hu et al., 2022] 使用低秩自适应 (LoRA) 的值和梯度。
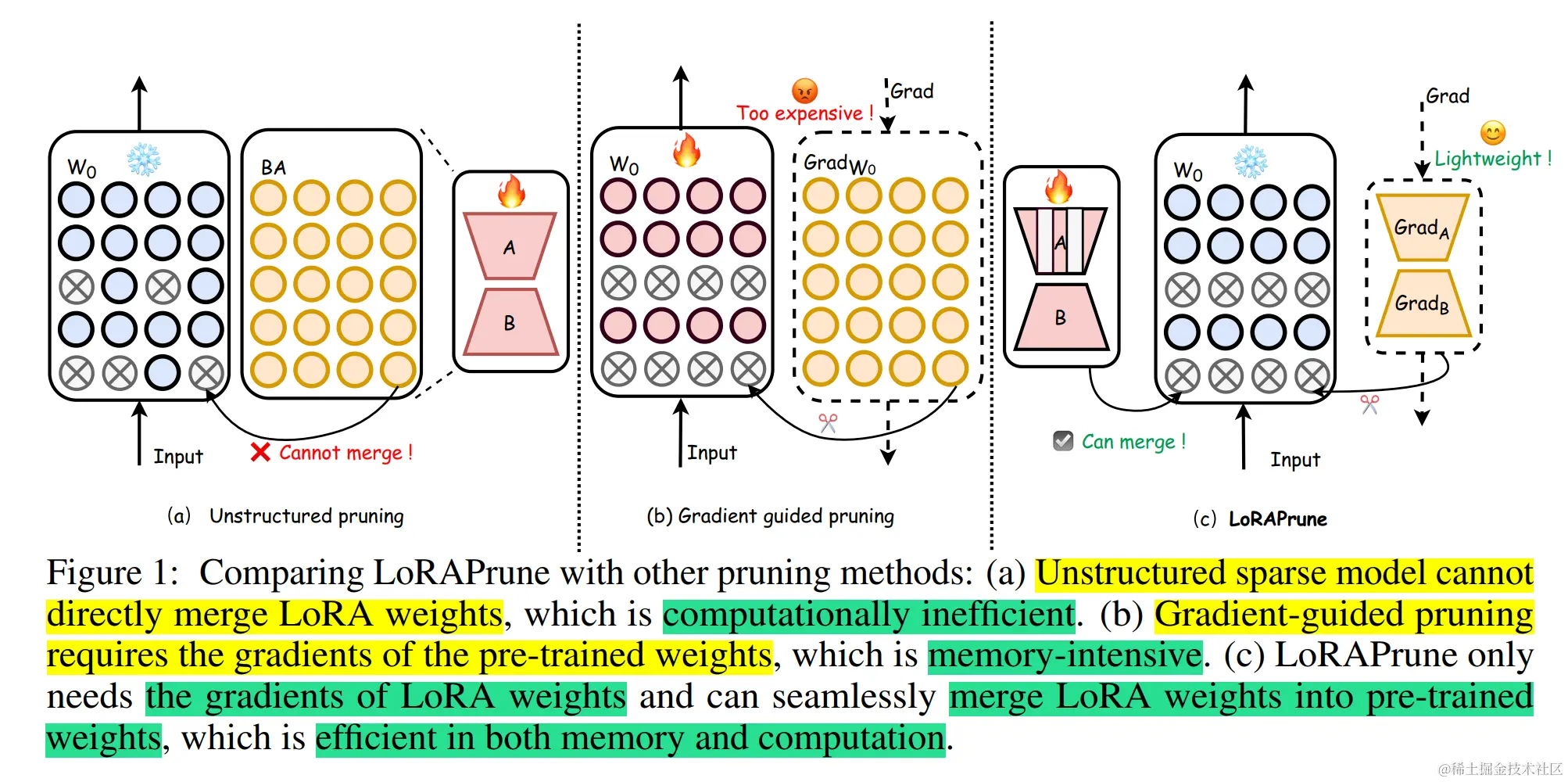
为了解决 SparseGPT 仍然需要的资源密集型权重更新过程,Wanda(论文:Simple and Effective Pruning Approach for Large Language Models)提出了一种新的剪枝指标。 Wanda 根据每个权重的大小和相应输入激活的范数的乘积来评估每个权重,并使用小型校准数据集进行近似。该指标用于线性层输出内的局部比较,从而能够从 LLMs 中删除较低优先级的权重。
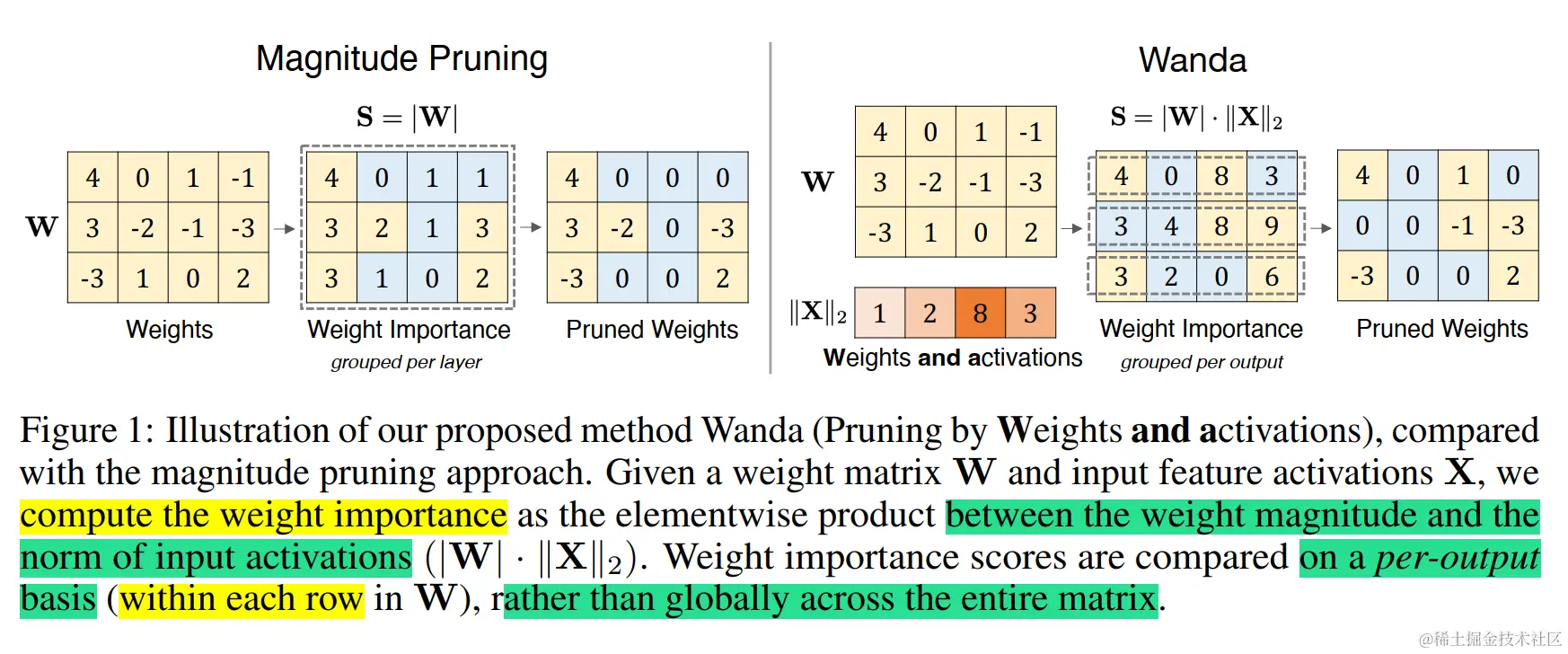
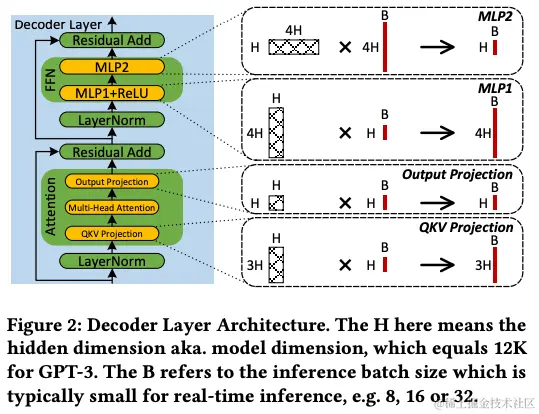
通过观察到 LLM 推理性能和内存使用量很大程度上受到下图四种类型的 Skinny MatMul 的限制。 因此,Flash-LLM 旨在基于称为“稀疏加载和密集计算”(LSCD) 的关键方法来优化四个 MatMul。Flash-LLM 作为另一个用于非结构化模型剪枝的大语言模型推理加速方法。主要包含基于Tensor-Core加速的非结构化稀疏矩阵乘法计算的高效GPU代码,可以有效加速LLM中常见矩阵计算的性能。使用Flash-LLM,修剪后的LLM模型可以以更少的内存消耗部署到GPU上,并且可以更高效地执行。
结构化剪枝方法
结构化剪枝通过删除整个结构组件(例如:神经元、通道或层)来简化 LLM。这种方法同时针对整组权重,具有降低模型复杂性和内存使用量的优点,同时保持整体 LLM 结构完整。
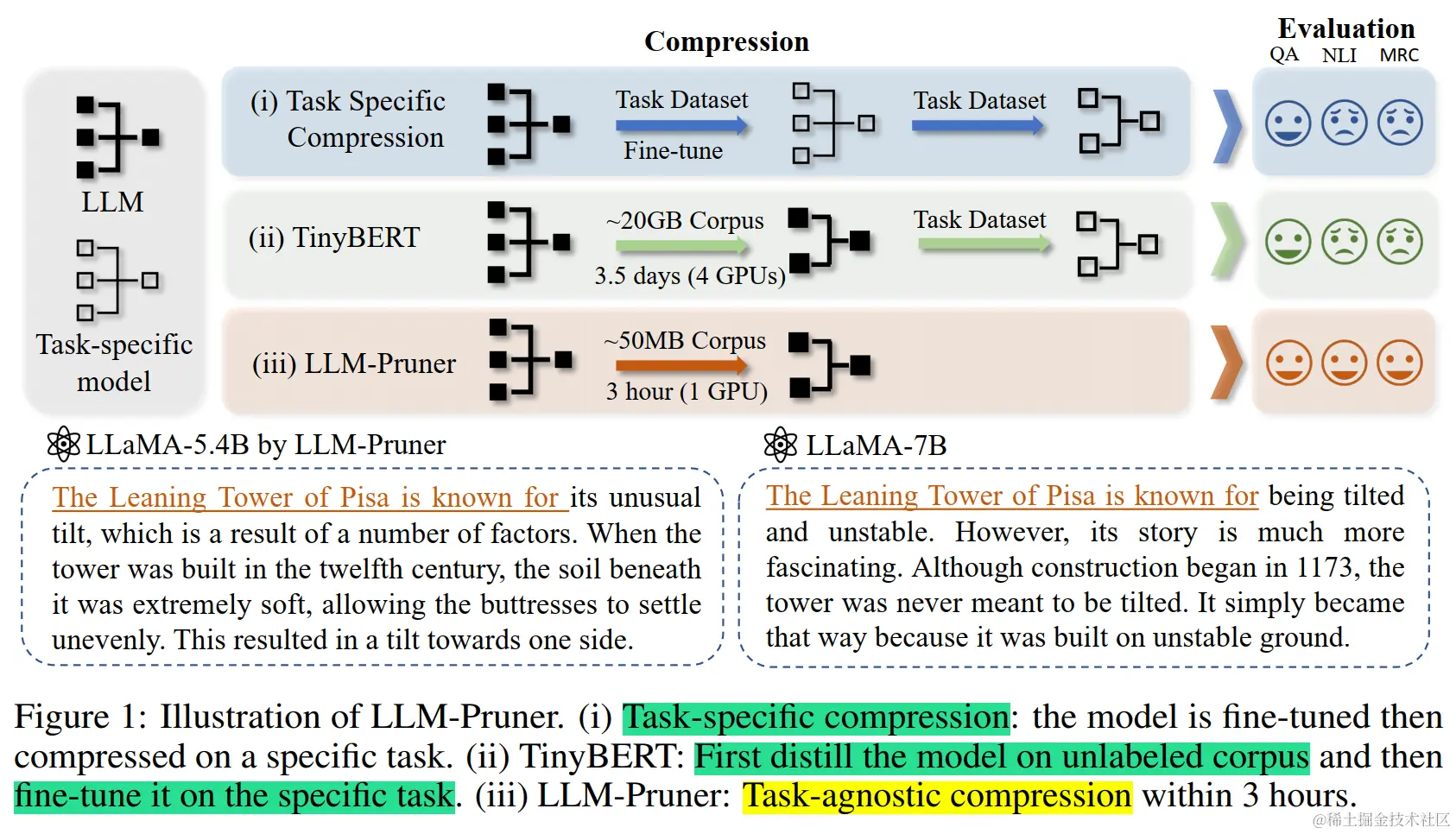
这个领域的一个例子是 LLM-Pruner(论文:LLM-Pruner: On the Structural Pruning of Large Language Models),它采用通用方法来压缩 LLMs,同时保护其多任务解决能力和语言生成能力。此外,LLM-Pruner 还解决了 LLMs 使用大量训练数据带来的挑战,这可能导致大量的数据传输。为了克服这些挑战,LLM-Pruner 结合了依赖性检测算法来查明模型中相互依赖的结构。它还实现了一种有效的重要性估计方法,该方法考虑一阶信息和近似的 Hessian 信息。该策略有助于选择最佳的组用于剪枝,从而改进压缩过程。
通过研究能否利用现有的预训练 LLMs 来生成更小、通用且具有竞争力的 LLM,同时使用比从头开始训练要少得多的计算量?LLM-Shearing 提出了另外一种结构化剪枝方法。该方法提出了两种技术:
-
有针对性的结构化剪枝:将源模型剪枝为预先指定的目标架构,同时最大化剪枝模型的性能。
-
动态批量加载:修剪会导致跨域的信息保留发生变化。本方法为恢复缓慢的域加载更多数据,并且加载比例是动态决定的。

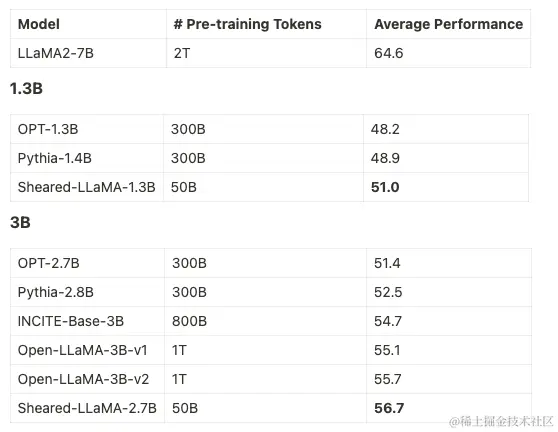
通过评估一系列广泛的下游任务,包括推理、阅读理解、语言建模和知识密集型任务,我们的 Sheared-LLaMA 模型优于现有的大语言模型。
结语
本文简单讲述了目前大模型剪枝的一些工作,在大模型参数量越来越大的今天,该方向的研究对于减少模型的大小以及复杂性非常有用。
码字不易,如果觉得有帮助,欢迎点赞收藏加关注。
参考文档:
————————————————
版权声明:本文为稀土掘金博主「吃果冻不吐果冻皮」的原创文章
原文链接:https://juejin.cn/post/7355347789677428787
如有侵权,请联系千帆社区进行删除
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,从而导致模型变得越来越大,因此,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。而大模型压缩主要分为如下几类:
- 模型剪枝(Pruning)
- 知识蒸馏(Knowledge Distillation)
- 模型量化(Quantization)
- 低秩分解(Low-Rank Factorization)
本文将针对当前大模型剪枝相关的一些工作进行讲述。
剪枝简介
模型剪枝(Model Pruning)是一种用于减少神经网络模型参数数量和计算量的技术。它通过识别和去除在训练过程中对模型性能影响较小的参数或连接,从而实现模型的精简和加速。
通常,模型剪枝可以分为两种类型:结构化剪枝(Structured Pruning)、非结构化剪枝(Unstructured Pruning)。
结构化剪枝和非结构化剪枝的主要区别在于剪枝目标和由此产生的网络结构。结构化剪枝根据特定规则删除连接或层结构,同时保留整体网络结构。而非结构化剪枝会剪枝各个参数,从而产生不规则的稀疏结构。
模型剪枝的一般步骤包括:
- 训练初始模型:首先,需要训练一个初始的大模型,通常是为了达到足够的性能水平。
- 评估参数重要性:使用某种评估方法(如:权重的绝对值、梯度信息等)来确定模型中各个参数的重要性。
- 剪枝:根据评估结果,剪枝掉不重要的参数或连接,可以是结构化的或非结构化的。
- 修正和微调:进行剪枝后,需要进行一定的修正和微调,以确保模型的性能不会显著下降。
模型剪枝可以带来多方面的好处,包括减少模型的存储需求、加速推理速度、减少模型在边缘设备上的资源消耗等。然而,剪枝可能会带来一定的性能损失,因此需要在剪枝前后进行适当的评估和调整。
下面来探讨一些将LLMs与剪枝技术相结合的方法,旨在解决LLMs巨大尺寸和计算成本的问题。
非结构化剪枝方法
非结构化剪枝通过删除特定参数而不考虑其内部结构来简化 LLM。这种方法针对 LLM 中的单个权重或神经元进行,通常通过将阈值以下的参数归零。但是此方法忽略了 LLM 整体结构,导致不规则的稀疏模型,这种不规则性需要专门的压缩技术来有效存储和计算剪枝后的模型。
非结构化修剪通常涉及对 LLM 进行大量重新训练以重新获得准确性,这对于LLMs来说尤其昂贵。该领域的一种创新方法是 SparseGPT(论文:SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot)。它引入了一种不需要重新训练的一次性剪枝策略。该方法将剪枝视为广泛的稀疏回归问题,并使用近似稀疏回归求解器对其进行求解。 SparseGPT 实现了显著的非结构化稀疏性,在 OPT-175B 和 BLOOM-176B 等大模型上甚至高达 60%,而困惑度的增加很小。
与此相反,Syed 等人[Syed et al., 2023]提出一种迭代剪枝技术,在剪枝过程中以最少的训练步骤微调模型。
另一个优化是 LoRAPrune(论文:LoRAPrune: Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning),它将参数高效调整 (PEFT) 方法与剪枝相结合,以增强下游任务的性能。它引入了一种独特的参数重要性标准 [Hu et al., 2022] 使用低秩自适应 (LoRA) 的值和梯度。
为了解决 SparseGPT 仍然需要的资源密集型权重更新过程,Wanda(论文:Simple and Effective Pruning Approach for Large Language Models)提出了一种新的剪枝指标。 Wanda 根据每个权重的大小和相应输入激活的范数的乘积来评估每个权重,并使用小型校准数据集进行近似。该指标用于线性层输出内的局部比较,从而能够从 LLMs 中删除较低优先级的权重。
通过观察到 LLM 推理性能和内存使用量很大程度上受到下图四种类型的 Skinny MatMul 的限制。 因此,Flash-LLM 旨在基于称为“稀疏加载和密集计算”(LSCD) 的关键方法来优化四个 MatMul。Flash-LLM 作为另一个用于非结构化模型剪枝的大语言模型推理加速方法。主要包含基于Tensor-Core加速的非结构化稀疏矩阵乘法计算的高效GPU代码,可以有效加速LLM中常见矩阵计算的性能。使用Flash-LLM,修剪后的LLM模型可以以更少的内存消耗部署到GPU上,并且可以更高效地执行。
结构化剪枝方法
结构化剪枝通过删除整个结构组件(例如:神经元、通道或层)来简化 LLM。这种方法同时针对整组权重,具有降低模型复杂性和内存使用量的优点,同时保持整体 LLM 结构完整。
这个领域的一个例子是 LLM-Pruner(论文:LLM-Pruner: On the Structural Pruning of Large Language Models),它采用通用方法来压缩 LLMs,同时保护其多任务解决能力和语言生成能力。此外,LLM-Pruner 还解决了 LLMs 使用大量训练数据带来的挑战,这可能导致大量的数据传输。为了克服这些挑战,LLM-Pruner 结合了依赖性检测算法来查明模型中相互依赖的结构。它还实现了一种有效的重要性估计方法,该方法考虑一阶信息和近似的 Hessian 信息。该策略有助于选择最佳的组用于剪枝,从而改进压缩过程。
通过研究能否利用现有的预训练 LLMs 来生成更小、通用且具有竞争力的 LLM,同时使用比从头开始训练要少得多的计算量?LLM-Shearing 提出了另外一种结构化剪枝方法。该方法提出了两种技术:
- 有针对性的结构化剪枝:将源模型剪枝为预先指定的目标架构,同时最大化剪枝模型的性能。
- 动态批量加载:修剪会导致跨域的信息保留发生变化。本方法为恢复缓慢的域加载更多数据,并且加载比例是动态决定的。
通过评估一系列广泛的下游任务,包括推理、阅读理解、语言建模和知识密集型任务,我们的 Sheared-LLaMA 模型优于现有的大语言模型。
结语
本文简单讲述了目前大模型剪枝的一些工作,在大模型参数量越来越大的今天,该方向的研究对于减少模型的大小以及复杂性非常有用。
码字不易,如果觉得有帮助,欢迎点赞收藏加关注。
参考文档:
————————————————
版权声明:本文为稀土掘金博主「吃果冻不吐果冻皮」的原创文章
原文链接:https://juejin.cn/post/7355347789677428787
如有侵权,请联系千帆社区进行删除
评论
![preview]()
发表评论
