【千帆平台】零代码结合知识库或者插件开发一款AI应用,2024年奥运会运动员获奖信息
AI原生应用开发/技术交流
- LLM
- 文心大模型
- Prompt
8月13日1307看过
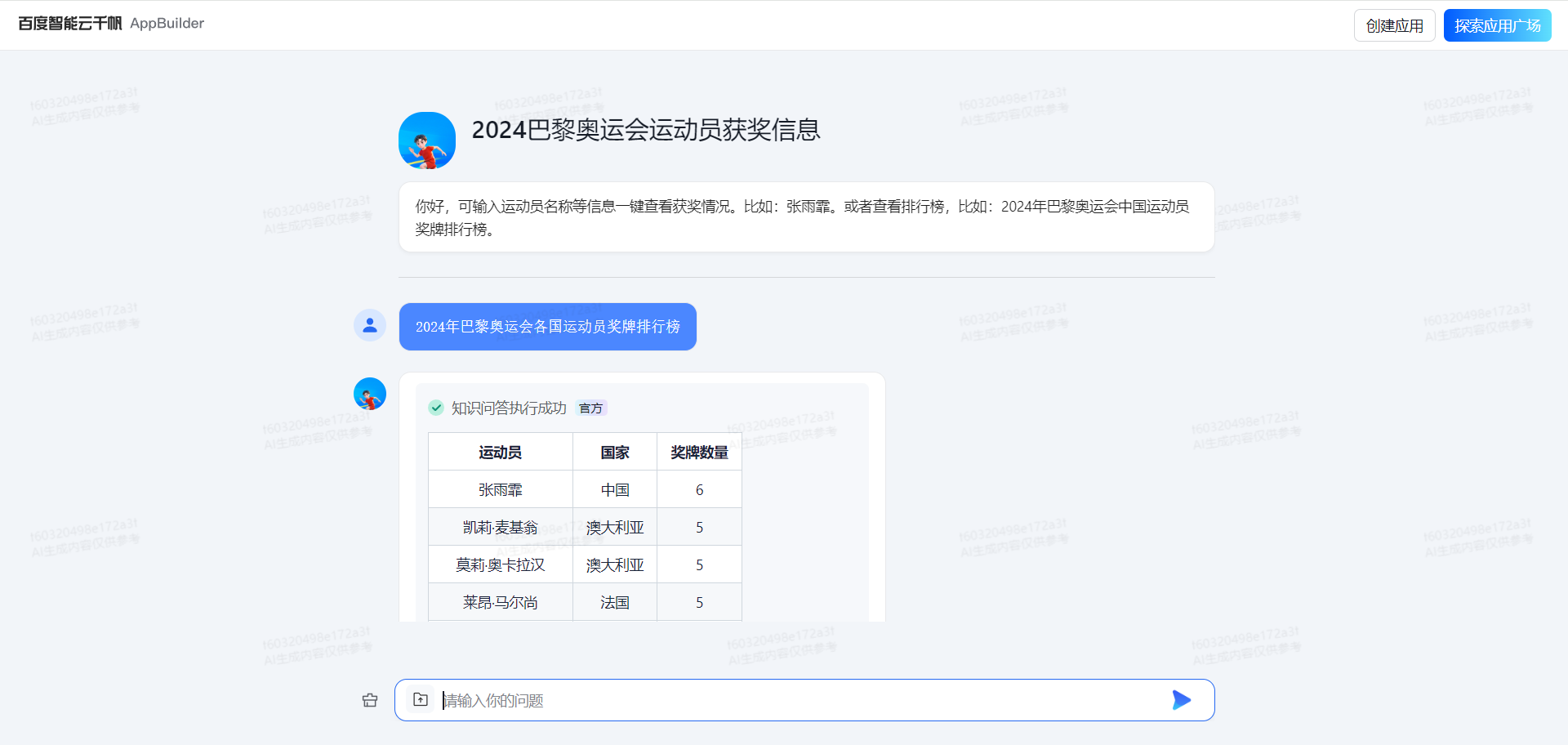
背景
2024年奥运会已经落下帷幕,中国金牌并列第一。
尽管比赛已经结束,网上也有很多奖牌排行榜,但是很少有运动员维度获奖信息或者排行榜。
因此,博主这里通过记录2024年奥运会的每个获奖运动员信息,并且通过知识库方式进行存储查询。
可以查询指定运动员获奖信息,或者各个国家奖牌排行情况等等。
尽管比赛已经结束,网上也有很多奖牌排行榜,但是很少有运动员维度获奖信息或者排行榜。
因此,博主这里通过记录2024年奥运会的每个获奖运动员信息,并且通过知识库方式进行存储查询。
可以查询指定运动员获奖信息,或者各个国家奖牌排行情况等等。
组件方式
prompt
下面是通过调用组件方式编写的prompt,目的是按大模型能够识别到并调用组件
#角色设定你是一名2024巴黎奥运会运动员获奖信息查询小助手,你能够根据用户输入的运动员名称执行插件工具,然后获得插件工具返回数据进行显示。#组件能力1、根据用户输入的运动员名称,执行组件。2、根据用户输入的排行榜,执行组件。3、组件返回数据进行显示。#要求与限制1.输出内容的合法合规,不能具有敏感信息2.要求解析markdown格式表格,并以表格方式显示信息3.输出格式为一个表格
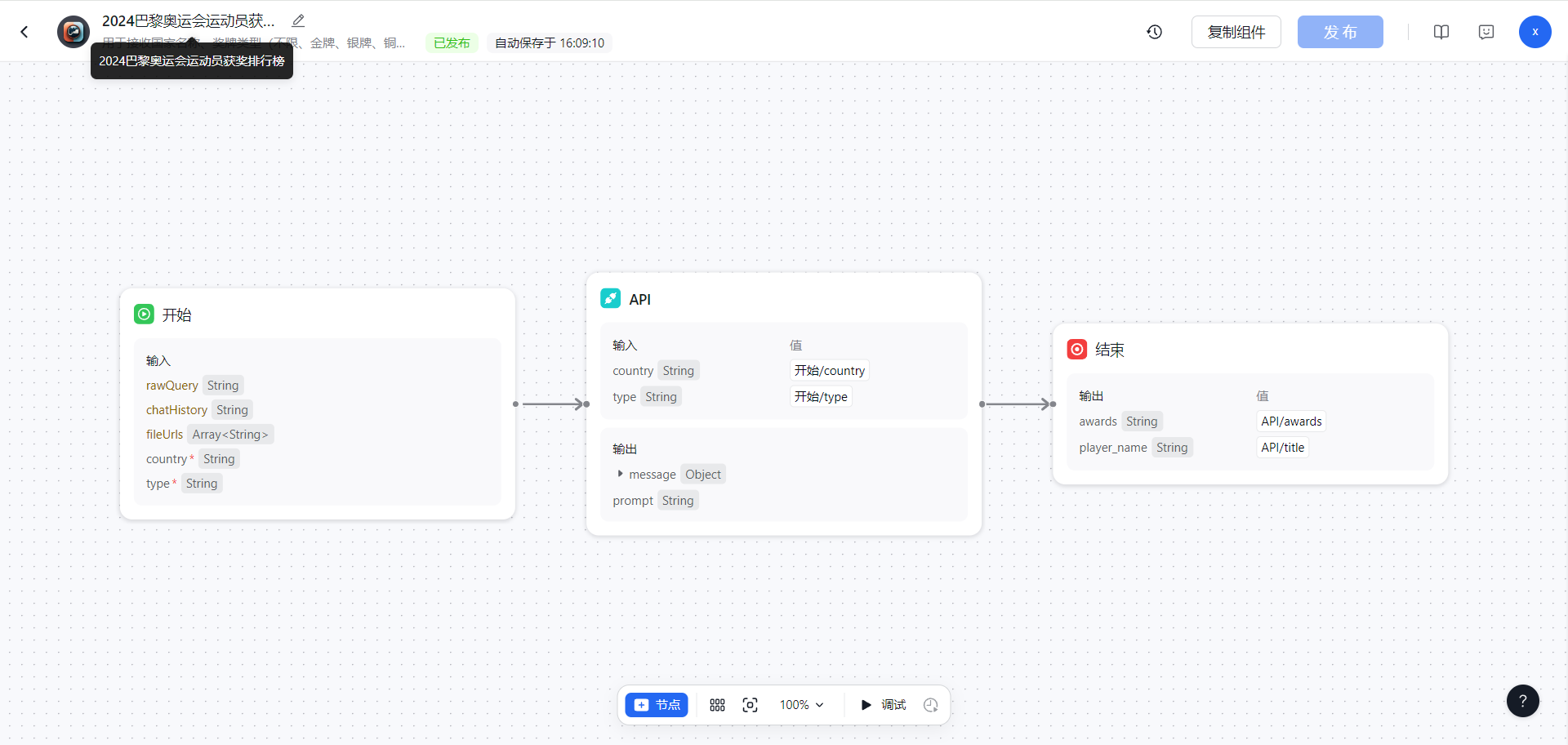
新参数
在开始节点,新增多了两个参数chatHistory和fileUrls。
chatHistory:用户与应用的对话历史(有了这个参数也许可以做到和用户一对一识别后端交互,这个可以验证下)
fileUrls:用户在对话中上传的文件地址
chatHistory:用户与应用的对话历史(有了这个参数也许可以做到和用户一对一识别后端交互,这个可以验证下)
fileUrls:用户在对话中上传的文件地址
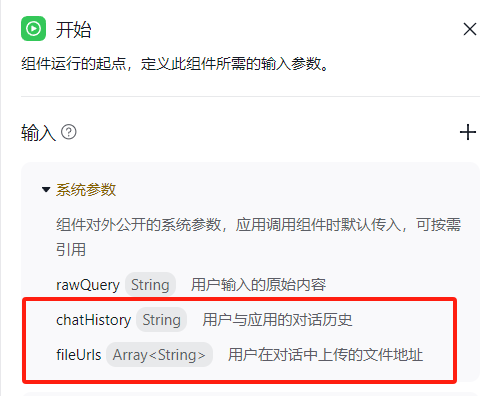
历史对话参数查看情况
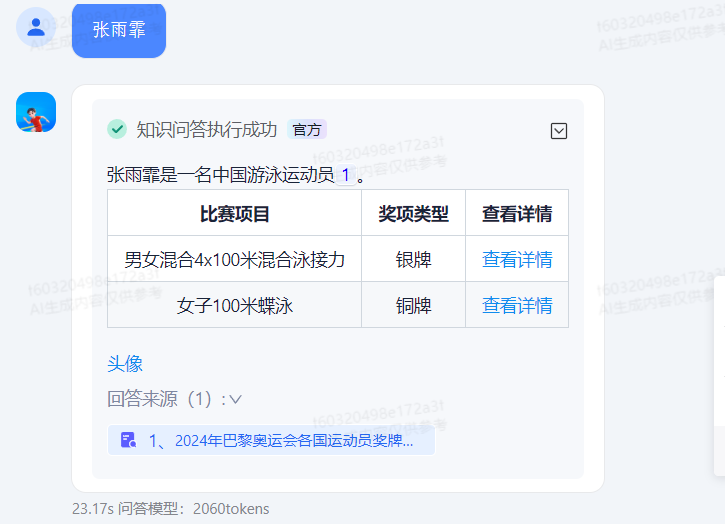
第一次对话,chatHistory历史对话参数没有值
{"input":"张雨霏运动员获奖信息","name":"张雨霏","chatHistory":""}
第二次对话,会把前一次的问答记录传回来
{"input":"苏炳添运动员","name":"苏炳添","chatHistory":"User:张雨霏运动员获奖信息\nAssistant:张雨霏运动员在2024巴黎奥运会上的获奖信息如下:\n| 比赛项目 | 奖牌 |\n| --- | --- |\n| 男女混合4x100米混合泳接力 | 银牌 |\n| 女子100米蝶泳 | 铜牌 |\n| 女子200米蝶泳 | 铜牌 |\n| 女子4x100米混合泳接力 | 铜牌 |\n| 女子4x100米自由泳接力 | 铜牌 |\n| 女子50米自由泳 | 铜牌 |\n以上就是张雨霏运动员在巴黎奥运会上的获奖情况。\n\n"}
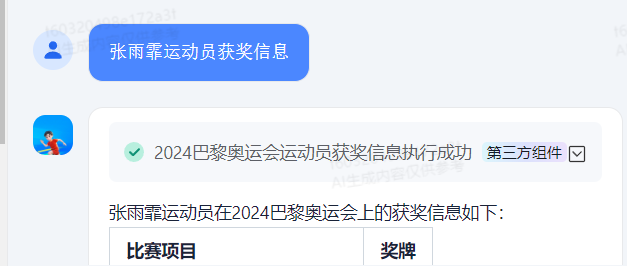
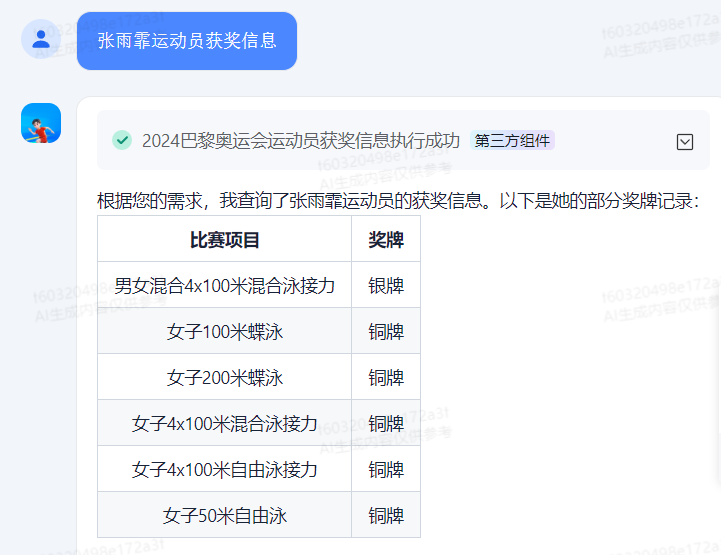
运动员信息组件
组件里使用了一个API节点,api调用的是自己服务器后端接口,通过接口写逻辑查询数据库。
关键还是设置好api接口接收的参数name运动员参数,这个参数的是被由大模型进行识别和赋值。
关键还是设置好api接口接收的参数name运动员参数,这个参数的是被由大模型进行识别和赋值。
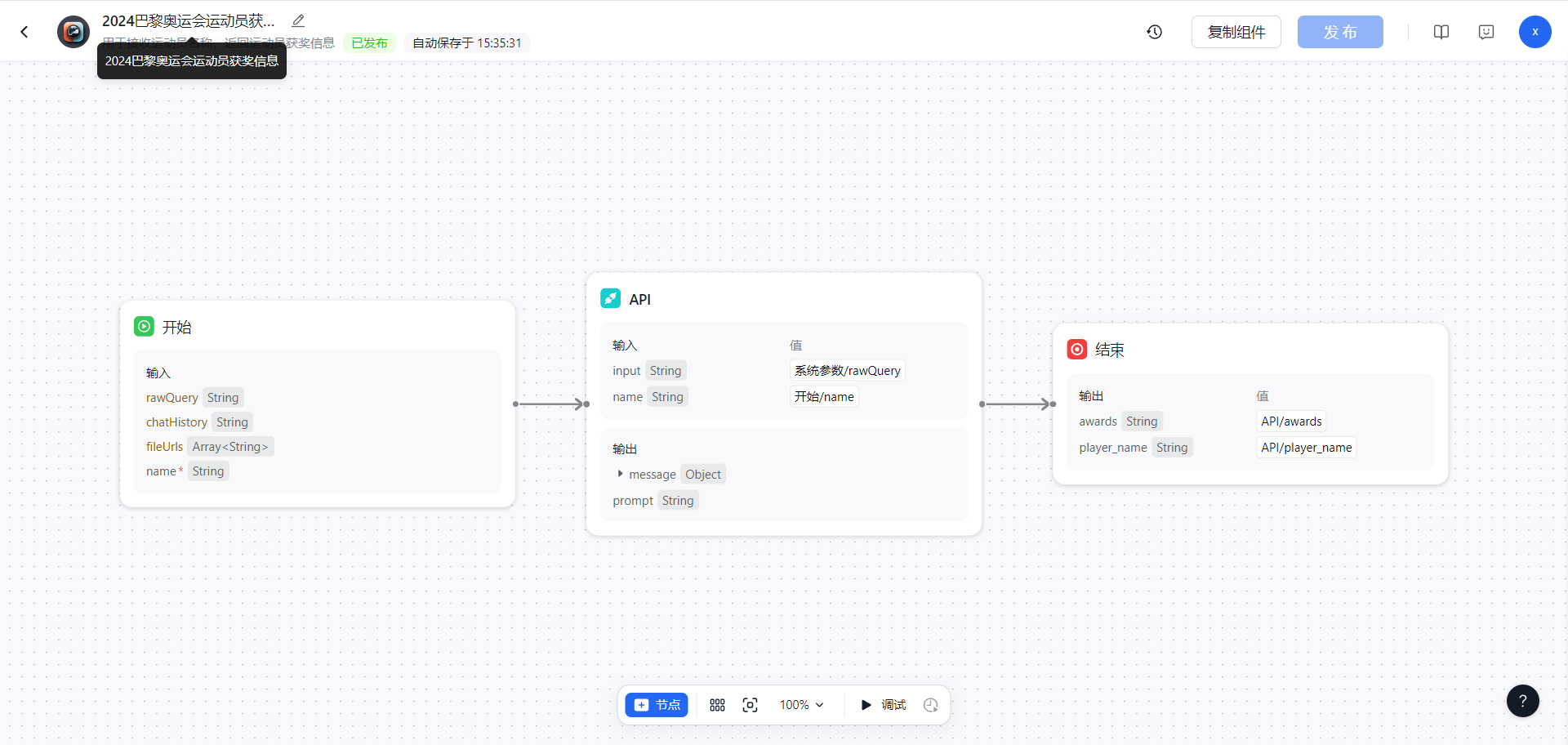
奖牌排行榜组件
组件里使用了一个API节点,api调用的是自己服务器后端接口,通过接口写逻辑查询数据库。
关键还是设置好api接口接收的参数country国家和type奖牌类型参数,这个参数的是被由大模型进行识别和赋值。
关键还是设置好api接口接收的参数country国家和type奖牌类型参数,这个参数的是被由大模型进行识别和赋值。

知识库方式
知识库这里,控制切换的内容长度也是一个非常关键的地方。
prompt
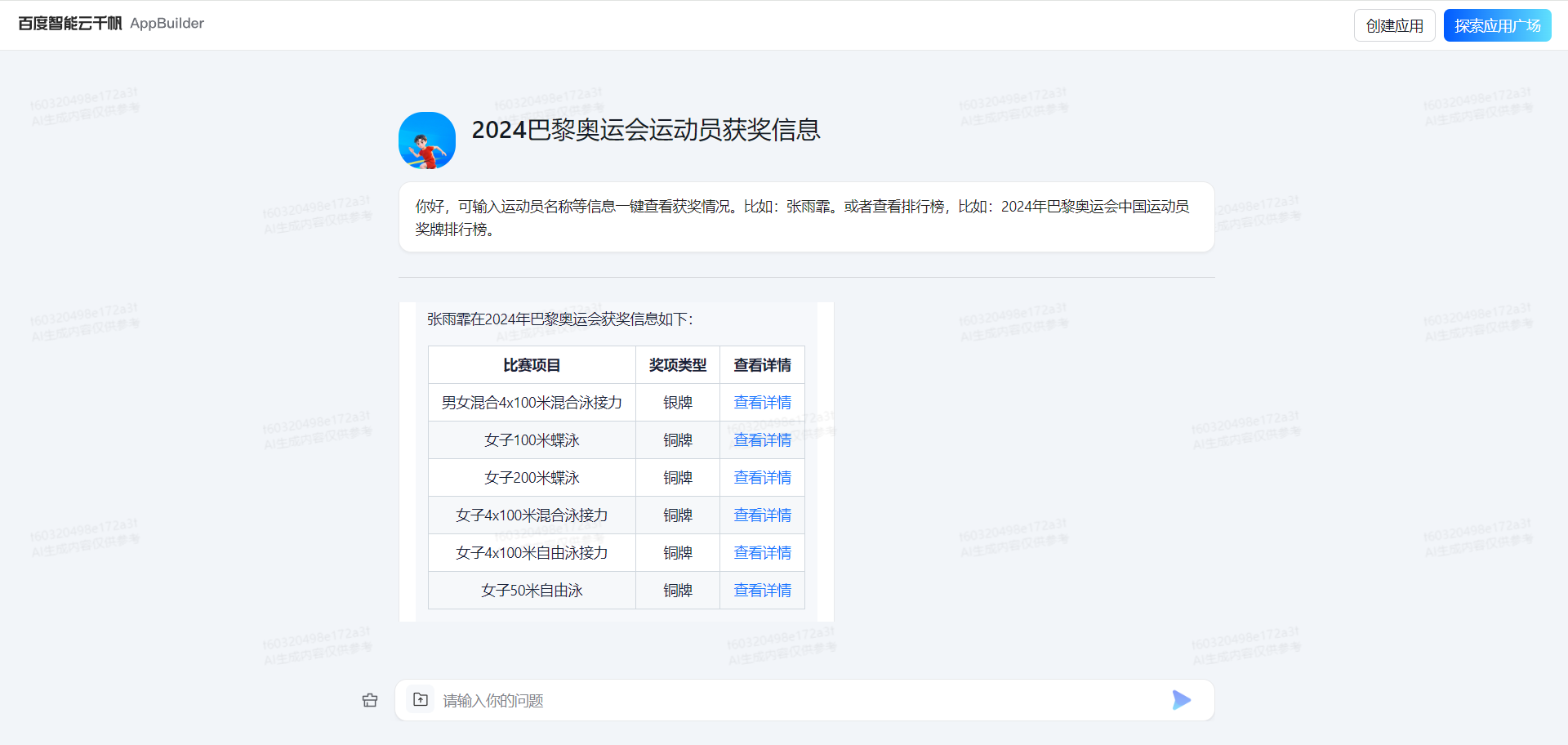
#角色设定你是一名2024巴黎奥运会运动员获奖信息查询小助手,你能够根据用户输入的运动员名称执行知识库查询信息,以及各维度奖牌排行榜信息。#知识库能力1、根据用户输入的运动员名称,执行知识库查询。2、根据用户输入的排行榜,执行知识库查询。3、知识库返回数据进行显示。4、用户输入查询排行榜、奖牌榜等信息时,调用知识库【2024年巴黎奥运会各国运动员奖牌数量排行榜】文件查询#要求与限制1.输出内容的合法合规,不能具有敏感信息2.要求解析markdown格式表格,并以表格方式显示信息3.输出格式为一个表格#运动员输出格式XXX是一名XX国家XX运动员|比赛项目|奖项类型|查看详情|[头像]()#排行榜输出格式|运动员|国家|奖牌数量|
切片断层
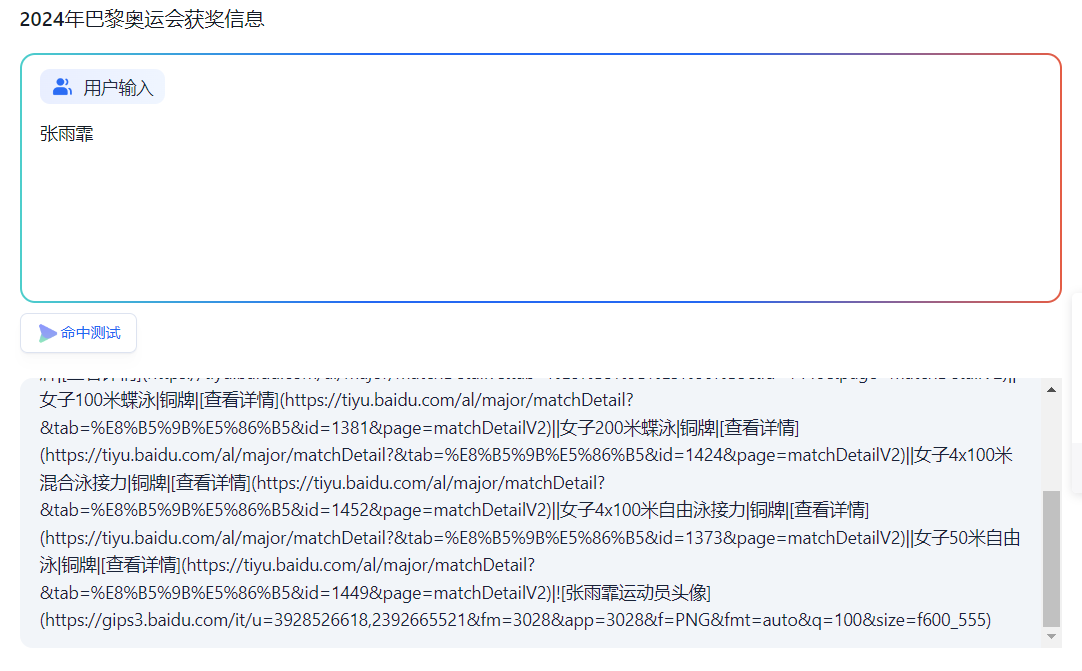
这里使用【张雨霏】运动员作为例子,因为获奖奖牌数量多,所以,她的内容也是会比较多,
这样在默认切片情况下,在命中测试时是会出现断层,从而无法准确查询到所有信息。
这样在默认切片情况下,在命中测试时是会出现断层,从而无法准确查询到所有信息。
-
下面是默认切片效果
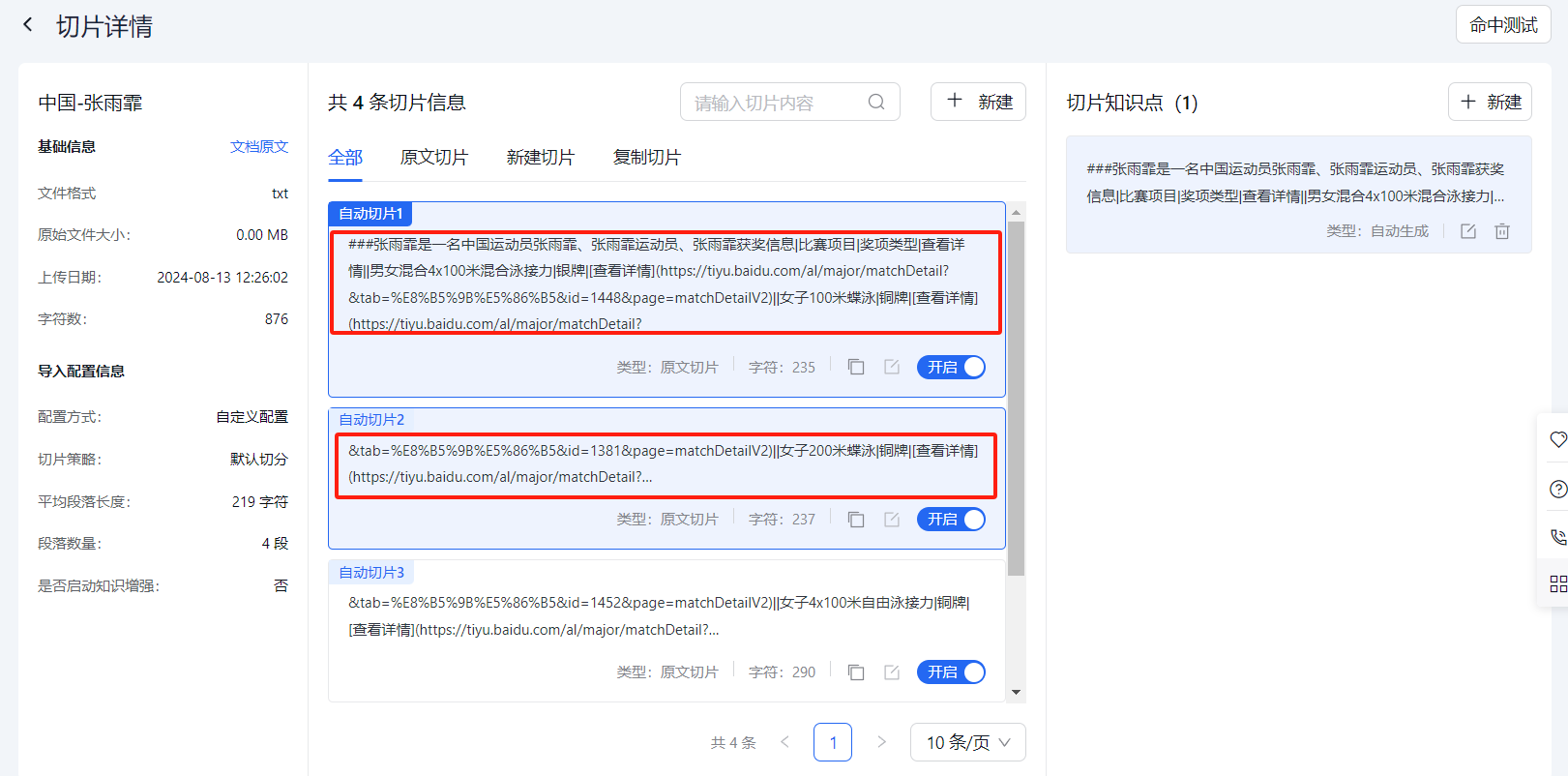
-
下面是根据#井号进行整个运动员信息切片效果
模型输出
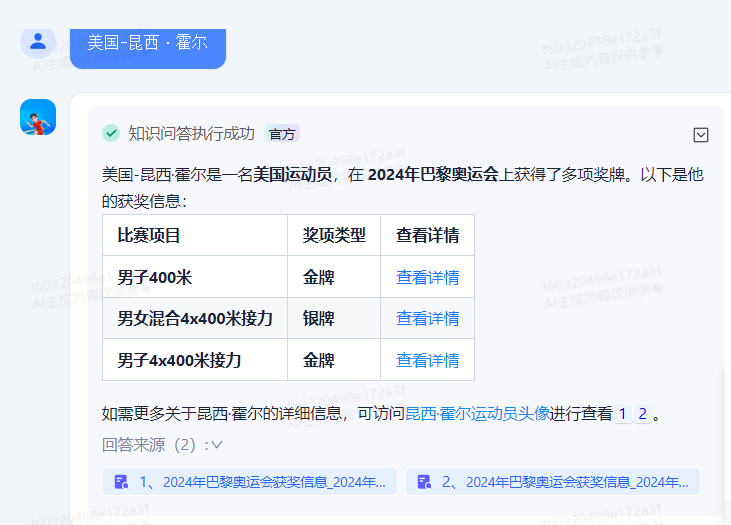
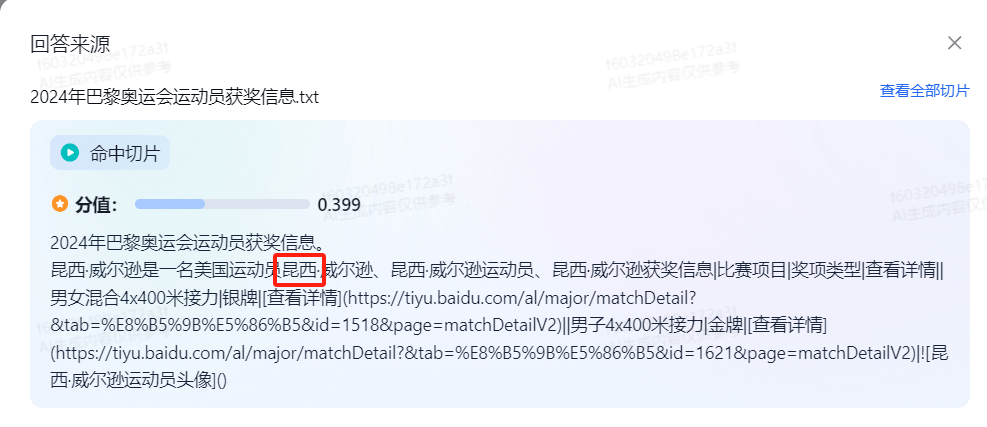
刚开始选择Speed速度上有优势的问答模型,发现会把部分信息混淆输出,导致数据不准确。
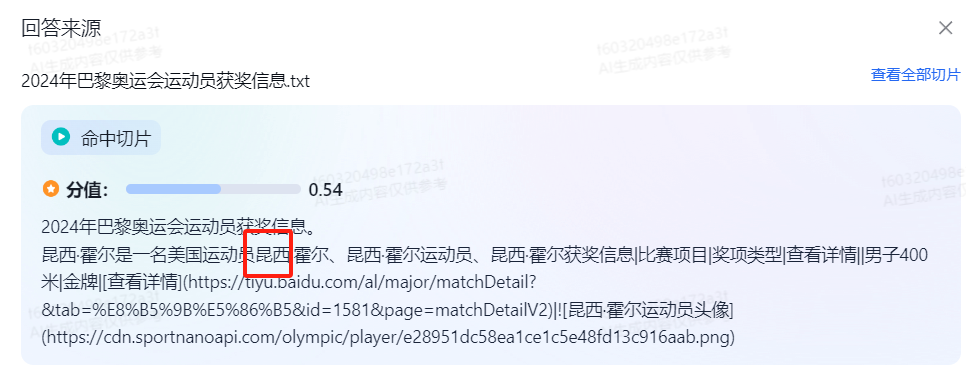
这个【美国昆西·霍尔】关键词,出来两个参考切片,查看内容发现【昆西】这个关键词一样。
为了确保准确性,选择了模型【ERNIE-4.0-8K】,之后测试可以准确输出。
这个【美国昆西·霍尔】关键词,出来两个参考切片,查看内容发现【昆西】这个关键词一样。
为了确保准确性,选择了模型【ERNIE-4.0-8K】,之后测试可以准确输出。
正则表达式
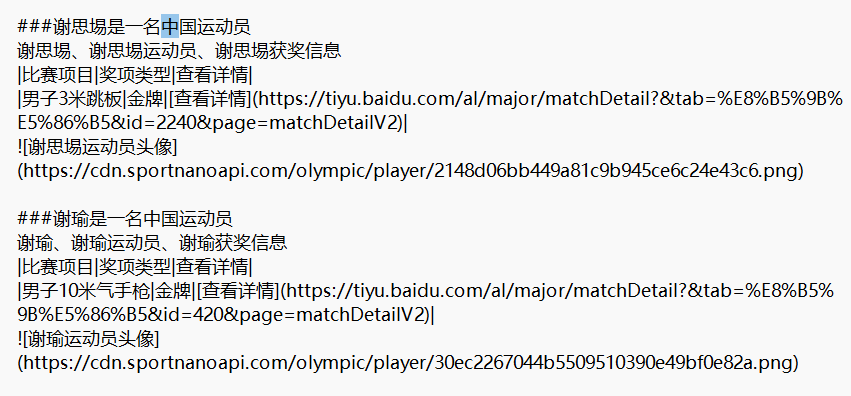
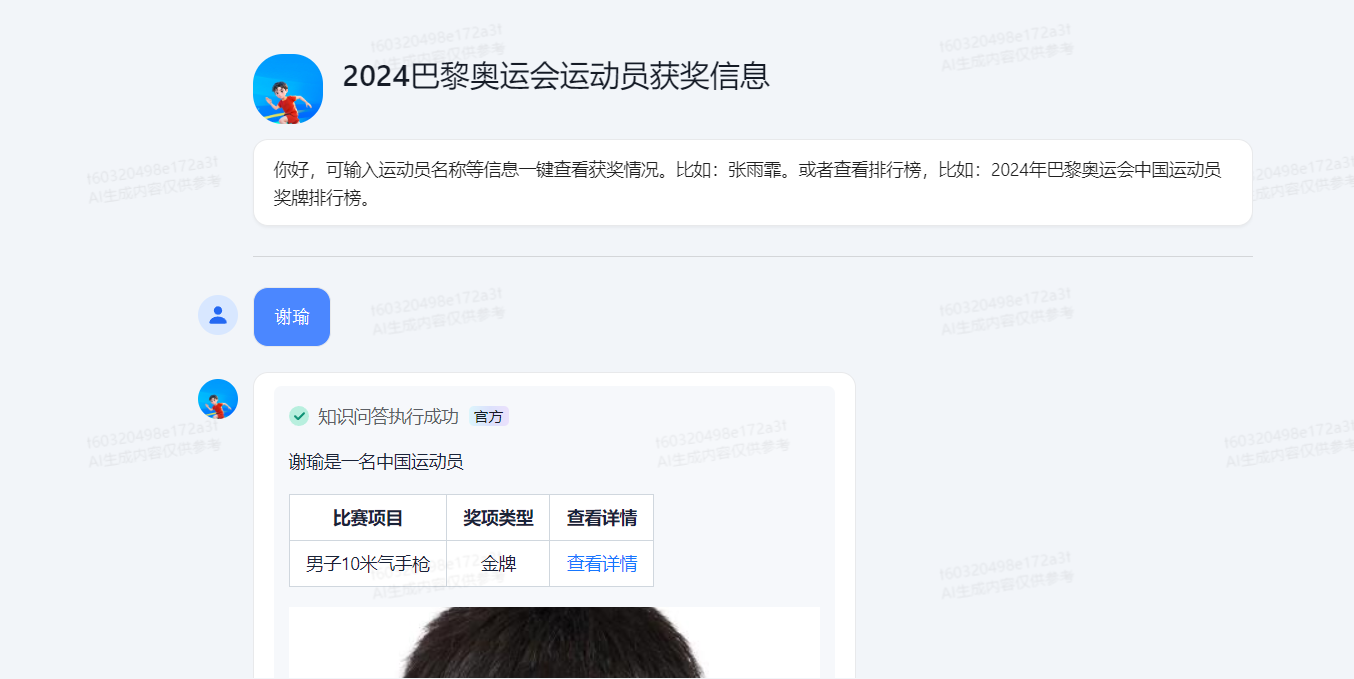
由于按运动员名称进行存储文件,上传到知识库时太多了。
因此,把所有运动员信息保存到同一个txt文档,然后通过#井号符号进行切分。
确保每个切片都是唯一一个运动员的所有信息,所以增加到5000个字符切分,基本能满足了。
因此,把所有运动员信息保存到同一个txt文档,然后通过#井号符号进行切分。
确保每个切片都是唯一一个运动员的所有信息,所以增加到5000个字符切分,基本能满足了。
整个文件作为切片
由于这个文件是各国奖牌排行榜数据,所以不能有断层,所以这里就用了整个文件作为切片。
给文件增加一些关键词,增加命中率,比如:排行榜、中国排行榜、各国排行榜等等
给文件增加一些关键词,增加命中率,比如:排行榜、中国排行榜、各国排行榜等等
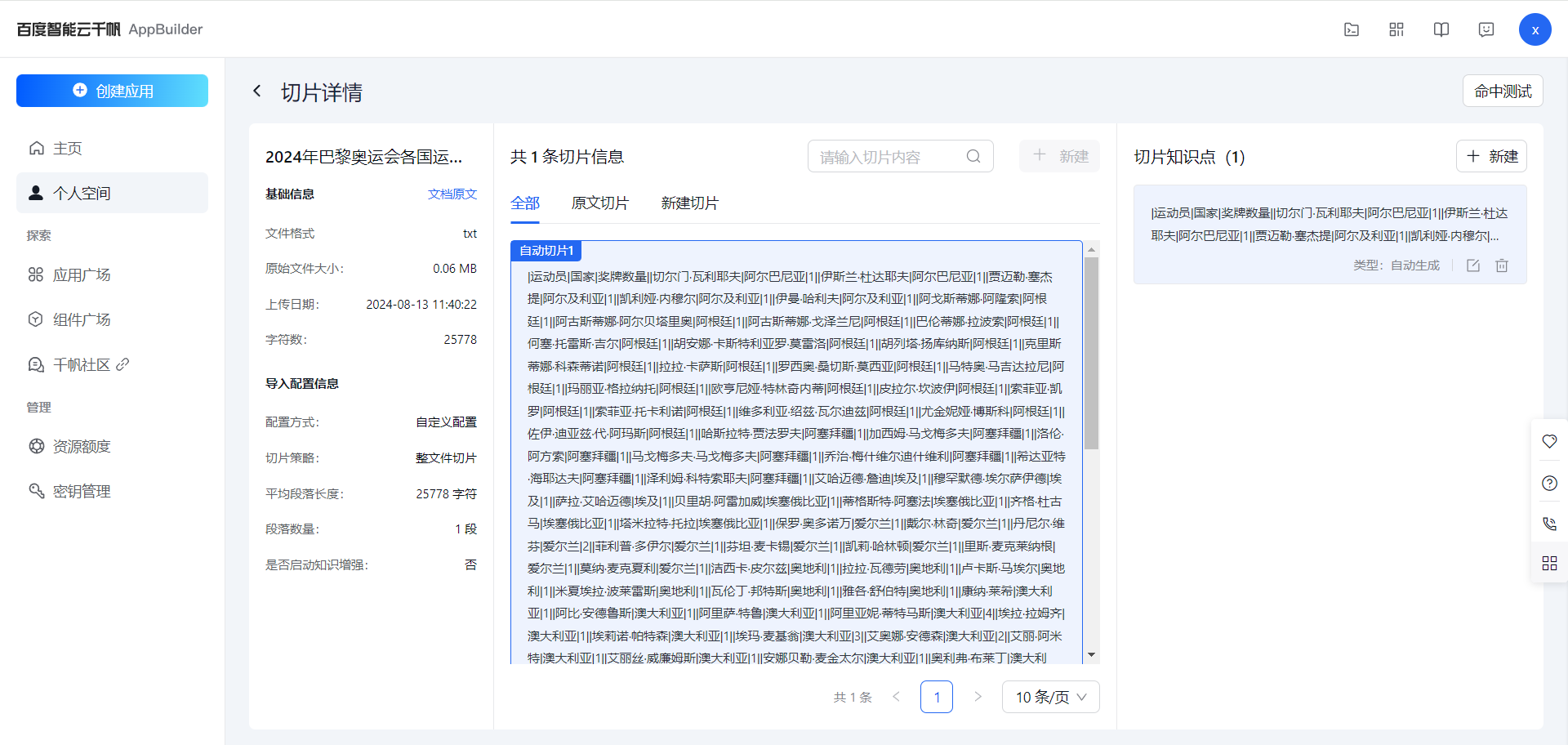
如果整个文件切片内容过长,很有可能是无法召回的,所以,也需要适当进行长度切片。
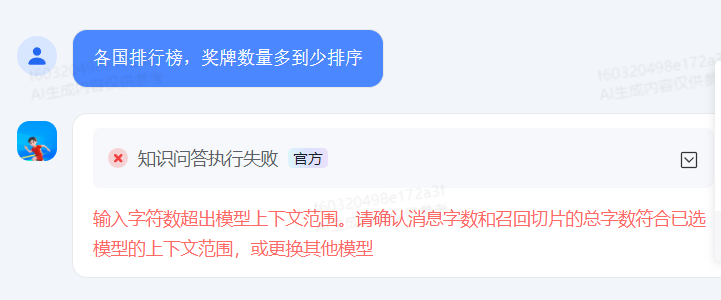
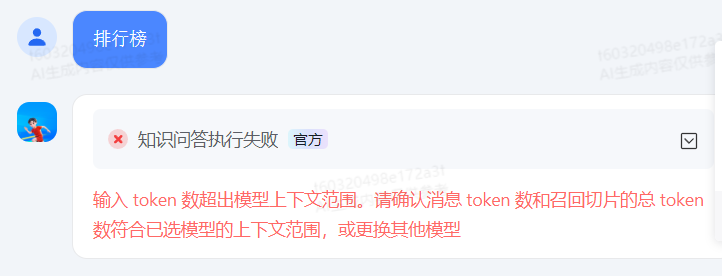
排行榜
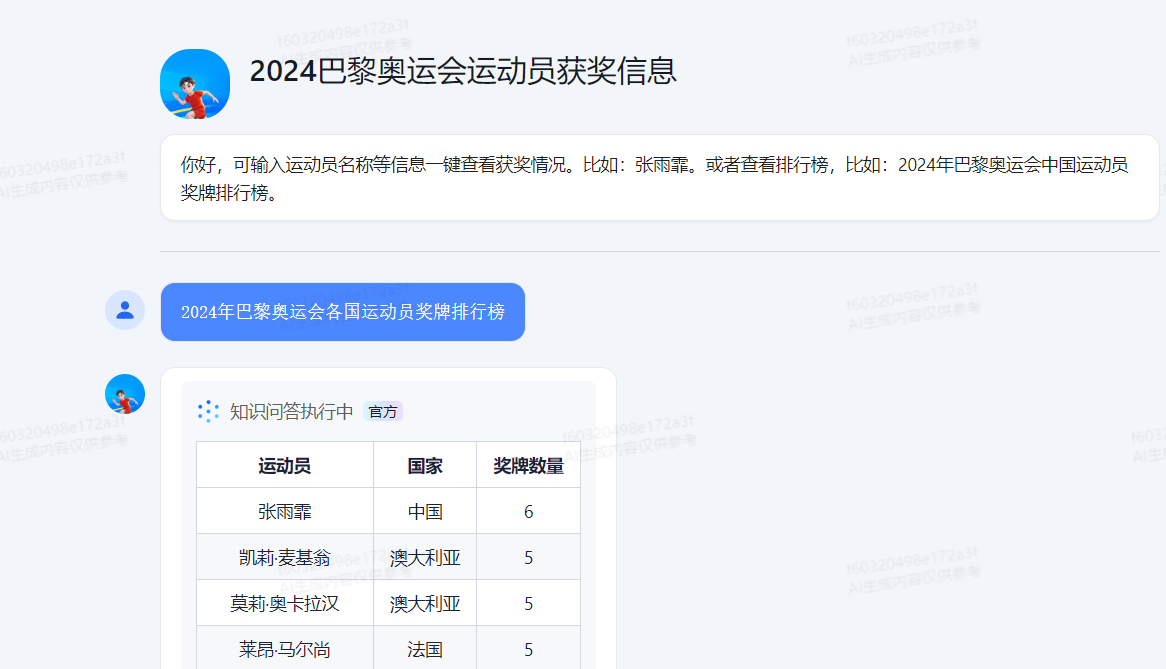
目前只上传了前20名,获得奖牌数量的排行榜。
|运动员|国家|奖牌数量||张雨霏|中国|6||凯莉·麦基翁|澳大利亚|5||莫莉·奥卡拉汉|澳大利亚|5||莱昂·马尔尚|法国|5||丽根·史密斯|美国|5||托丽·赫斯克|美国|5||阿里亚妮·蒂特马斯|澳大利亚|4||丽贝卡·安德拉德|巴西|4||萨默·麦金托什|加拿大|4||格蕾琴·沃尔什|美国|4||凯蒂·莱德基|美国|4||凯特·道格拉斯|美国|4||西蒙娜·拜尔斯|美国|4||冈慎之助|日本|4||杨浚瑄|中国|4||埃玛·麦基翁|澳大利亚|3||凯尔·查默斯|澳大利亚|3||马修·理查德森|澳大利亚|3||梅格·哈里斯|澳大利亚|3||金优镇|韩国|3|
体验地址
我在百度智能云千帆AppBuilder开发了一款AI原生应用,快来使用吧!
「2024巴黎奥运会运动员获奖信息」:https://appbuilder.baidu.com/s/lObZZwY5
手机端体验地址:https://wx.baeapps.com/api/ai_apaas/v1/wx_program/share?share_code=app7kD9trRXfbCLI2Q3WPpU
「2024巴黎奥运会运动员获奖信息」:https://appbuilder.baidu.com/s/lObZZwY5
手机端体验地址:https://wx.baeapps.com/api/ai_apaas/v1/wx_program/share?share_code=app7kD9trRXfbCLI2Q3WPpU
感谢阅读,本篇文章分享就到这里啦!希望这篇文章分享的知识库和组件的经验能够给你一点小灵感。
评论
