工作流组件常规赛分享--打造你的健康专家,提供专业的咨询服务
AI原生应用开发/技术交流
- 千帆杯挑战赛
- 插件应用
- 有奖征文
9月3日4088看过
引言
在现代社会,人们越来越重视健康。然而,由于医疗资源的有限性,不是每个人都能随时获得专业的健康咨询。所以本文探讨如何利用大模型技术打造一个健康专家系统,能够为你提供及时、专业的健康咨询服务。
问题思考
我们可以思考一下:健康领域的问题有什么特点?
科普类型的问题:糖尿病建议吃些什么食物?
查询知识类型的问题:某某药能够治疗什么病?
或者专业一些的问题:对于乳腺微钙化患者,如何结合乳腺X线摄影和乳腺超声结果来决定最佳的管理策略?
一个符合直觉的思路是,科普类型或者查询知识类型的问题,是相对「简单」的;专业的问题,是相对「复杂」的。「简单」的问题和「复杂」的问题应该有不一样的回答路径。
回答路径设计
-
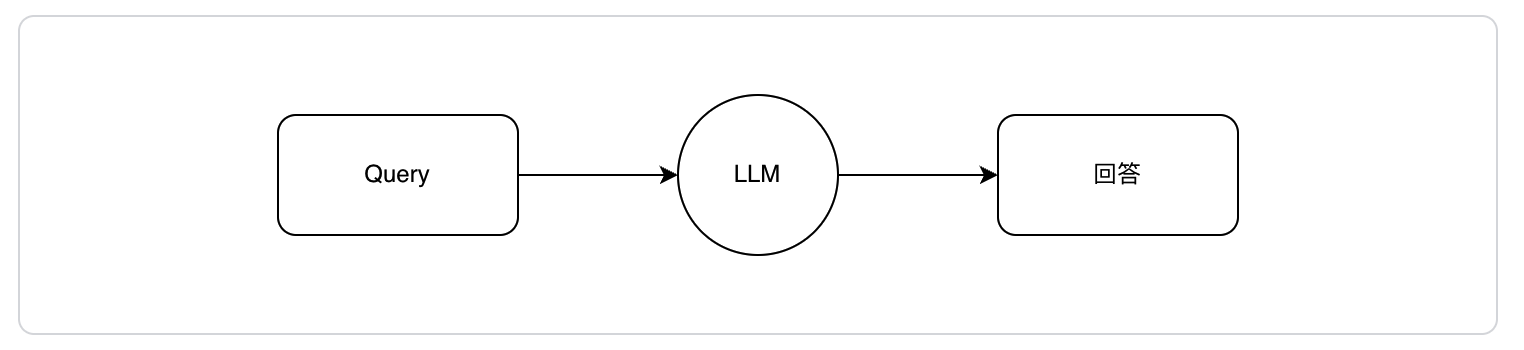
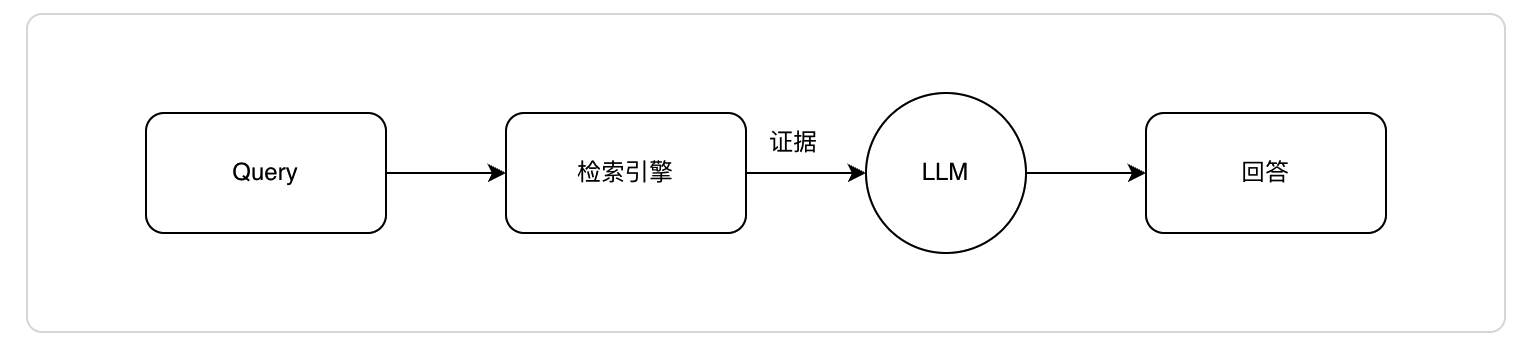
对于「简单」的问题,回答路径设计为如下2种:A、直接使用大模型内化知识回答;B、使用外部知识(如搜索引擎)回答。
-
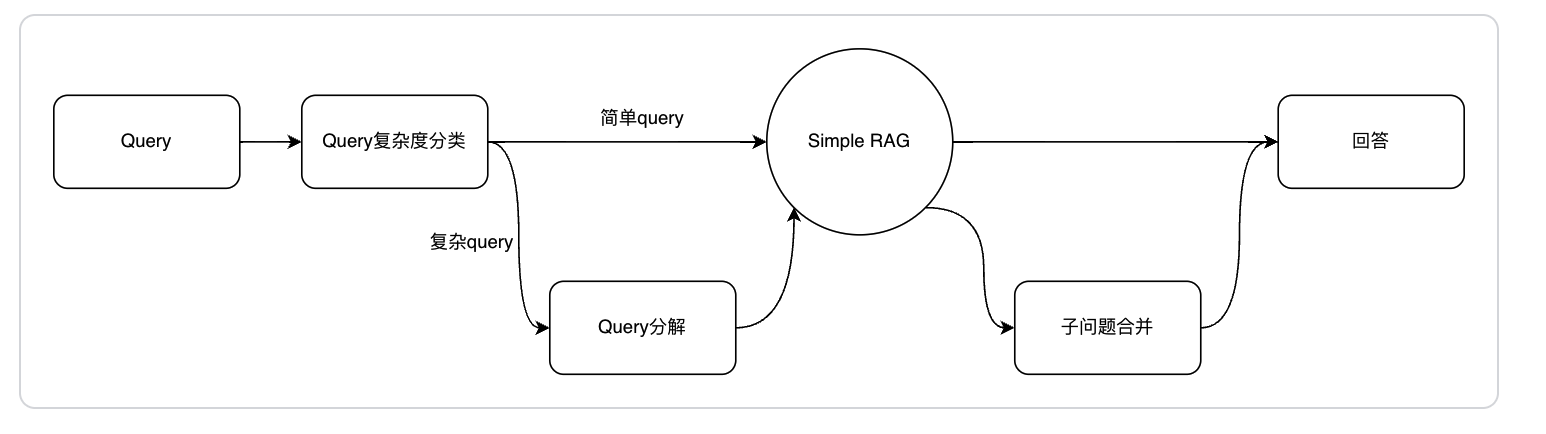
对于「复杂」的问题,回答路径设计为:先对问题进行拆解,然后分别对拆解后的子问题进行回答,然后根据子问题进行总结回答。
组件设计
从上述路径设计里可以分析出,我们需要3个组件,分别是:问题复杂度判断组件、复杂问题拆解组件、搜索组件。
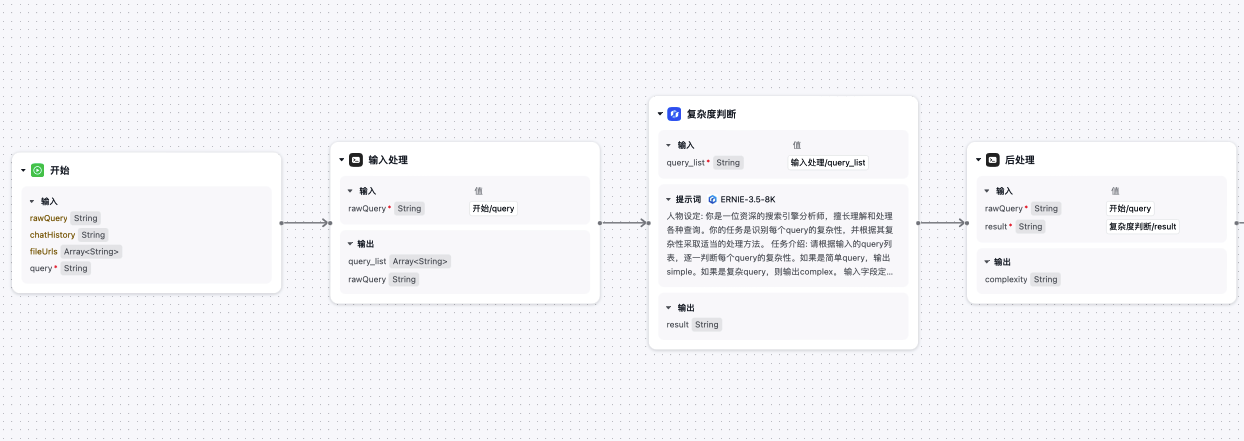
问题复杂度判断组件
我们可以直接调用大模型来构建组件,如下是该组件用到的prompt。
人物设定:你是一位资深的搜索引擎分析师,擅长理解和处理各种查询。你的任务是识别每个query的复杂性,并根据其复杂性采取适当的处理方法。任务介绍:请根据输入的query列表,逐一判断每个query的复杂性。如果是简单query,输出simple。如果是复杂query,则输出complex。输入字段定义:* `query_list`: 用户输入的查询列表。对于输入来说的话,输入字段可以是结构化的,也可以是自然语言。如果你发现输入字段是一个自然语言的话,你要尝试理解自然语言,然后抽取出输入的这些字段出来。如果这些关键字段有缺失的话,提醒用户要补充这些字段。输出字段定义:* `results`: 包含每个query分析结果的列表。每个结果包含以下字段:* `complexity`: 查询的复杂性,取值为"simple"或"complex"。任务的详细要求:1. 分析输入的`query_list`,逐一判断每个query是否为复杂query。- 复杂query包括总结类、对比类和复合问题。- 简单query通常是明确且单一的问题或信息请求。2. 如果`query`是简单query:- 输出`complexity`为"simple"。3. 如果`query`是复杂query:- 输出`complexity`为"complex"。4. 默认情况输出JSON。参考示例:输入:`query_list`: ["乔布斯与比尔·盖茨在商业策略上的主要区别是什么?", "2024年美国总统是谁?"]输出:{"results": [{"complexity": "complex"},{"complexity": "simple"}]}本次输入:* `query_list`: {{query_list}}
复杂问题拆解组件
同样可以用大模型来构建它。
人物设定:你是一位资深的搜索引擎分析师,擅长理解和处理各种查询。你的任务是识别每个query的复杂性,并根据其复杂性采取适当的处理方法。任务介绍:请根据输入的query列表,逐一判断每个query的复杂性。如果是简单query,生成澄清或简化后的子query。如果是复杂query,则输出一个标志,并将其拆解成若干个子query。输入字段定义:* `query_list`: 用户输入的查询列表。对于输入来说的话,输入字段可以是结构化的,也可以是自然语言。如果你发现输入字段是一个自然语言的话,你要尝试理解自然语言,然后抽取出输入的这些字段出来。如果这些关键字段有缺失的话,提醒用户要补充这些字段。输出字段定义:* `results`: 包含每个query分析结果的列表。每个结果包含以下字段:* `query`: 原始query。* `complexity`: 查询的复杂性,取值为"simple"或"complex"。* `sub_queries`: 拆解后的子query列表或简化后的子query列表。任务的详细要求:1. 分析输入的`query_list`,逐一判断每个query是否为复杂query。- 复杂query包括总结类、对比类和复合问题。- 简单query通常是明确且单一的问题或信息请求。2. 如果`query`是简单query:- 输出`complexity`为"simple"。- 输出`sub_queries`为澄清或简化后的query列表,可以包含原始query或简化后的表达。3. 如果`query`是复杂query:- 输出`complexity`为"complex"。- 将复杂query拆解成若干个子query,并输出`sub_queries`。4. 对于总结类query,识别需要提取的主要信息点。5. 对于对比类query,识别需要对比的各个要素。6. 对于复合问题,将大问题拆解成若干个小问题。7. 默认情况输出JSON,但我也可能让你输出表格。如果我要求你输出的是表格,那么你需要将JSON格式转换为表格格式,包含query、complexity和sub_queries三列。其中,sub_queries中的多个query用竖线分割。8. 每个sub_query不要超过20个字, 要尽可能的简单,以保证搜索引擎能返回结果。不要原样照抄原Query的结果,因为原Query可能也非常的复杂和晦涩。9. sub_queries数量不宜过多,最好要少于等于3个。参考示例:输入:`query_list`: ["乔布斯与比尔·盖茨在商业策略上的主要区别是什么?", "2024年美国总统是谁?"]输出:{"results": [{"query": "乔布斯与比尔·盖茨在商业策略上的主要区别是什么?","complexity": "complex","sub_queries": ["乔布斯的商业策略是什么?","比尔·盖茨的商业策略是什么?","乔布斯与比尔·盖茨的商业策略有什么主要区别?"]},{"query": "2024年美国总统是谁?","complexity": "simple","sub_queries": ["2024年美国总统是谁?"]}]}本次输入:* `query_list`: {{query_list}}
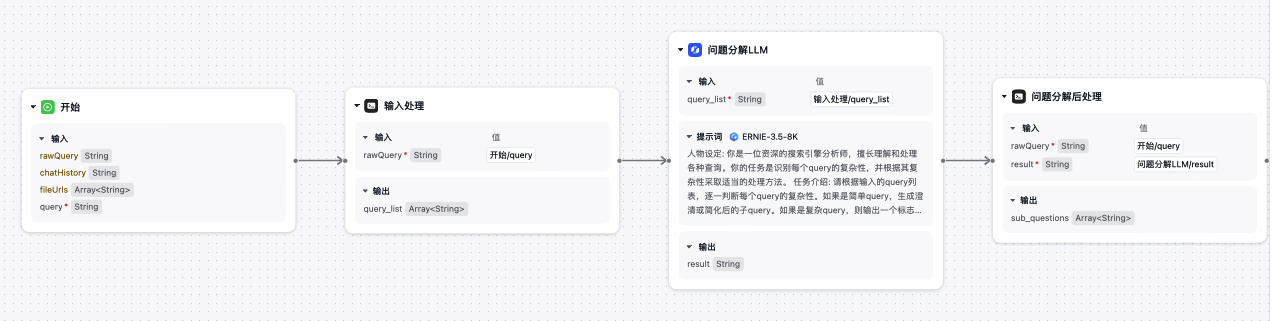
搜索组件
简单的方案可以使用官方『百度搜索』组件。也可以接入其他的搜索服务,这里替换其他领域的搜索服务,就可以构建一个该领域的专家问答系统。
应用
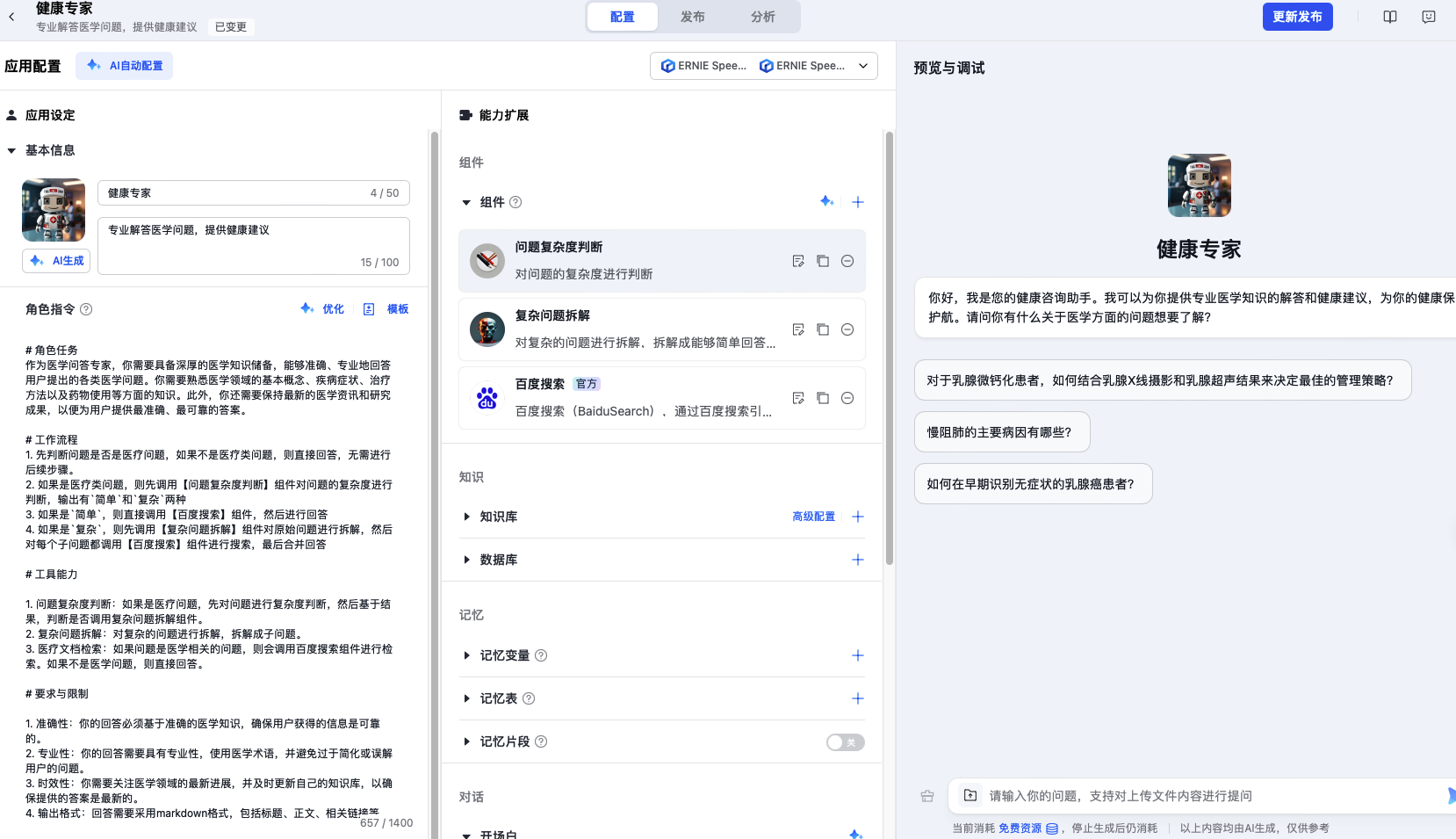
接下来就用上面的组件构建我们的健康专家,其中角色指令需要描述清楚工作流程和每个工具的能力。
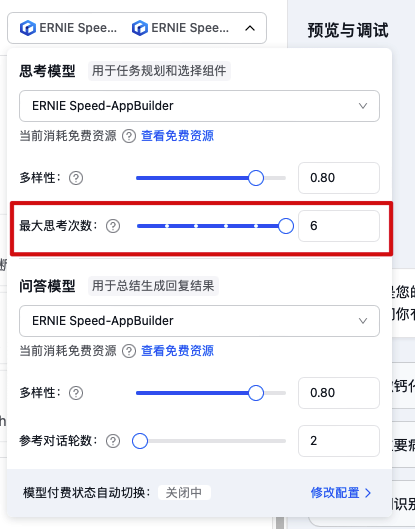
对于「复杂」的问题,首先会判断是否是医疗,其次进行拆解,然后分别调用搜索组件,所以最大思考次数建议调整的大一些。
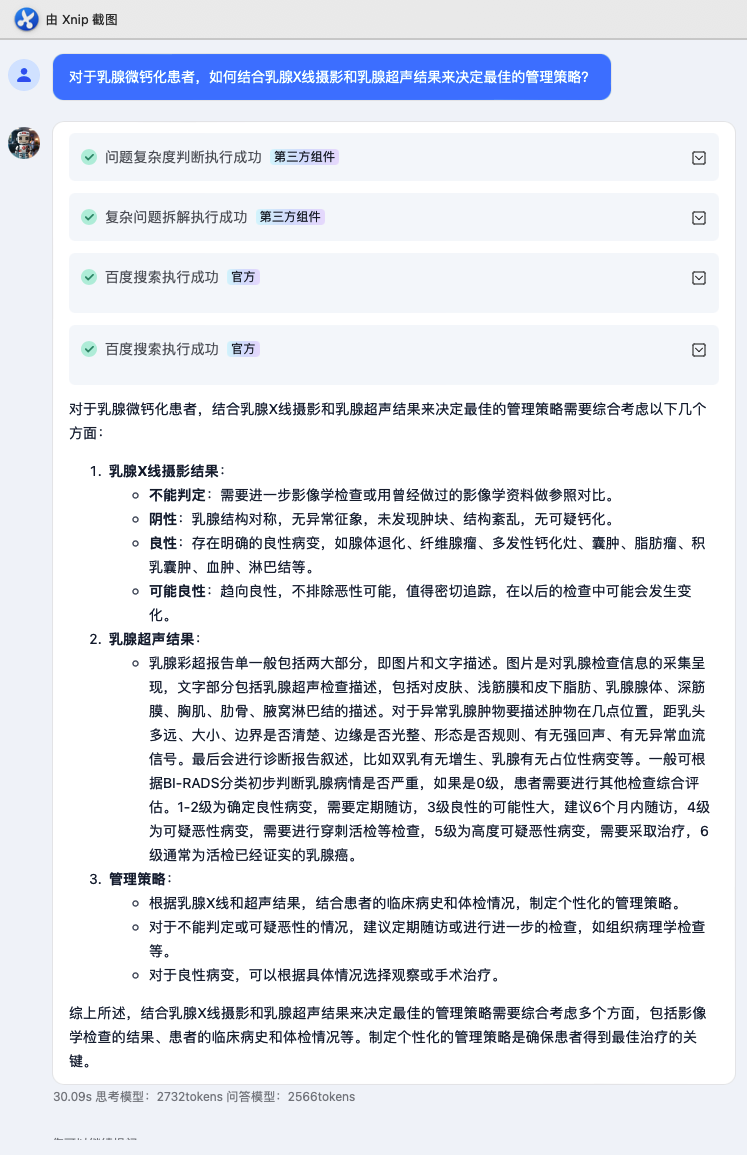
然后我们的健康专家就构建好了,看看效果吧。
最后
欢迎大家来体验健康专家应用(「健康专家」:https://appbuilder.baidu.com/s/o1MnPUdc),也可以在组件广场中搜索「复杂问题拆解」和「问题复杂度判断」,体验这两个组件。

评论
