大模型训练显存需求分析指南:从SFT到RLHF的实践之路
大模型开发/技术交流
- LLM
11月6日219看过
引言
随着大模型技术的快速发展,越来越多的研究者和开发者开始尝试自己训练或微调大模型。然而,大模型训练最大的门槛之一就是算力资源,特别是GPU显存的需求。本文将从实践角度出发,详细分析大模型训练中的显存需求,帮助读者更好地规划自己的训练资源。
显存需求概览
在大模型训练过程中,显存主要被以下几个部分占用:
-
模型权重
-
优化器状态
-
梯度
-
激活值
-
临时缓冲区
不同的训练阶段(如SFT、RLHF)对显存的需求也有所不同。
SFT阶段的显存分析
理论计算
以LLaMA-7B模型为例,让我们来分析SFT阶段的显存需求:
-
模型权重:7B参数 × 2字节(FP16) = 14GB
-
Adam优化器状态:7B参数 × 8字节 = 56GB
-
梯度:7B参数 × 2字节 = 14GB
-
激活值:依赖于序列长度和batch size
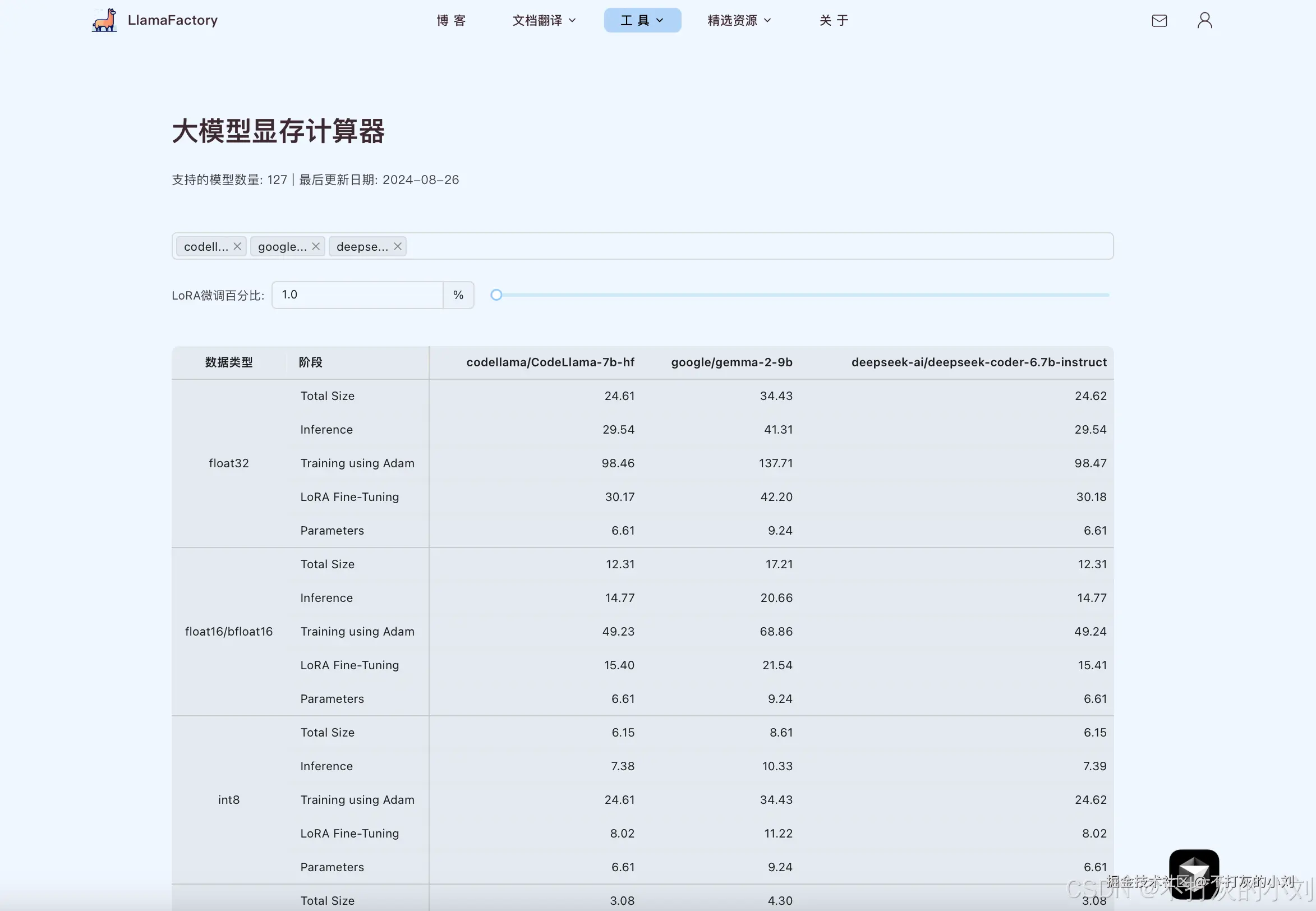
以上是LLaMA-7B大致的估算,可以参考llamfactory的显存计算助手查看更多模型的现存占用详情,例如:
实际优化策略
-
使用LoRA/QLoRA技术
-
-
仅训练少量参数,大幅降低显存需求
-
示例配置:python
-
lora_config = {"r": 8,"lora_alpha": 32,"target_modules": ["q_proj", "v_proj"]}
2.梯度检查点(Gradient Checkpointing)
-
以计算时间换取显存空间
-
实现方式:python
model.gradient_checkpointing_enable()
3.混合精度训练
-
使用FP16或BF16进行训练
-
配置示例:python
training_args = TrainingArguments(fp16=True,bf16=False)
RLHF的额外显存考虑
虽然目前工具还没有直接支持RLHF的显存分析,但我们可以从理论角度进行探讨。RLHF训练相比SFT,额外需要考虑:
-
奖励模型的显存开销
-
策略模型和参考模型的双重开销
-
PPO算法特有的buffer显存占用
RLHF显存优化建议
-
使用更小的奖励模型
-
适当减少PPO batch size
-
考虑使用CPU进行部分计算
实用工具推荐
-
-
用于快速估算训练所需显存
-
支持不同模型规模和训练参数的模拟
-
-
监控工具
实践经验分享
-
选择合适的批次大小
-
-
从小批次开始,逐步增加
-
监控显存使用情况
-
-
优化数据加载
dataloader = DataLoader(dataset,batch_size=4,pin_memory=True,num_workers=4)
3.及时释放不需要的显存
torch.cuda.empty_cache()
总结与展望
大模型训练的显存管理是一个持续优化的过程。通过合理的技术选择和优化策略,我们可以在有限的硬件资源下实现高效的模型训练。随着技术的发展,相信未来会有更多的显存优化方案出现,让大模型训练变得更加普及和高效。
参考资源
附录:常见问题解答
Q1: 如何估算自己的训练任务需要多少显存?
A1: 可以使用显存计算器工具进行初步估算,建议预留30%的余量。Q2: 遇到显存不足怎么办?
A2: 可以尝试以下方案:
-
使用LoRA等参数高效微调方法
-
启用梯度检查点
-
减小batch size
-
使用多GPU训练
Q3: 为什么实际显存使用常常超出理论计算值?
A3: 除了模型本身,框架、优化器、缓存等都会占用额外显存。建议在理论值基础上预留足够余量。
————————————————
版权声明:本文为稀土掘金博主「不打灰的小刘」的原创文章
原文链接:https://juejin.cn/post/7420980084360380416
如有侵权,请联系千帆社区进行删除
评论