运行AI聊天:纯浏览器,无后端
大模型开发/技术交流
- LLM
4天前21看过
想象一下,在你的浏览器中运行一个类似chatgpt的人工智能——完全离线。不需要服务器,不需要API调用,只是纯粹的浏览器功能。听起来不可能吗?不了!现代浏览器已经发展成为令人难以置信的强大平台,我很高兴向您展示它们的功能。我们将共同构建一个React.js web应用程序,即使在离线时也可以与之聊天
在没有后端的情况下在浏览器中运行自己的本地模型
这种方法的特别之处在于,我们直接在浏览器中运行LLM模型——不需要后端。这个概念很简单:下载一个模型文件,然后在本地运行推理,就在浏览器中。现代浏览器的功能确实非常出色。
多亏了WebAssembly,我们可以利用强大的C/C工具,比如llama.cpp。
请打鼓🥁…
从头开始建造💪
1. 用Vite创建一个React应用
首先,让我们建立我们的开发环境:
npm create vite@latest
然后初始化你的项目:
cd browser-llm-chatnpm install
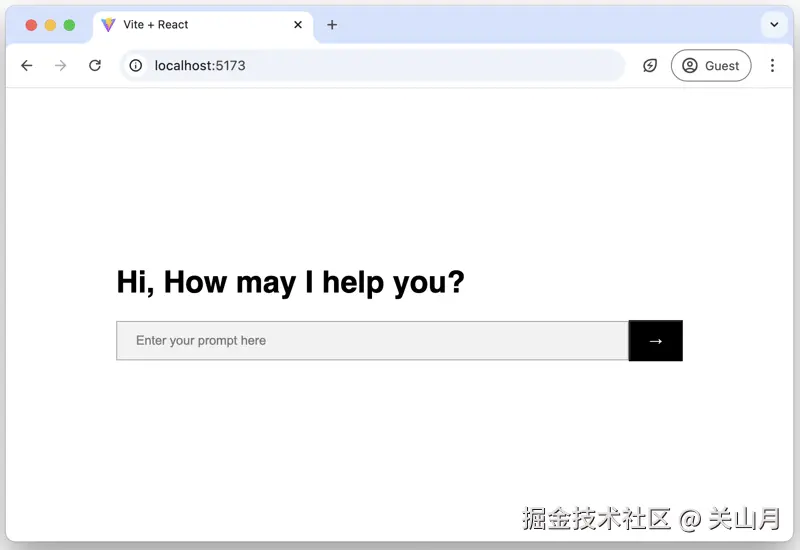
2. 设计基本UI
让我们创建一个干净、实用的界面。将
App.jsx 的内容替换为:
import { useState } from "react";function App() {const [prompt, setPrompt] = useState("");const [output, setOutput] = useState([]);const [isLoading, setIsLoading] = useState(false);const [progress, setProgress] = useState(0);const handlePromptInputChange = (e) => setPrompt(e.target.value);const shouldDisableSubmit = isLoading || prompt.trim().length === 0;const submitPrompt = () => {// We'll implement this next};return (<div><pre>{output.map(({ role, content }) => `${role}: ${content}\n\n`)}</pre>{!output.length && (<div>{isLoading ? <span>Loading {Math.ceil(progress)}%</span> : <h1>Hi, How may I help you?</h1>}</div>)}<div><inputtype="text"value={prompt}onChange={handlePromptInputChange}placeholder="Enter your prompt here"/><button type="button" onClick={submitPrompt} disabled={shouldDisableSubmit}><div>→</div></button></div></div>);}export default App;
index.css 添加一些基本的样式:
body {font-family: sans-serif;display: flex;justify-content: center;}pre {font-family: sans-serif;min-height: 30vh;white-space: pre-wrap;white-space: -moz-pre-wrap;white-space: -pre-wrap;white-space: -o-pre-wrap;}input {padding: 12px 20px;border: 1px solid #aaa;background-color: #f2f2f2;}input, pre {width: 60vw;min-width: 40vw;max-width: 640px;}button {padding: 12px 20px;background-color: #000;color: white;}
3. 集成Wllama
现在是令人兴奋的部分——让我们在应用程序中添加AI功能:
npm install @wllama/wllama @huggingface/jinja
更新
App.jsx 以集成Wllama:
import { useState } from "react";import { Wllama } from "@wllama/wllama/esm/wllama";import wllamaSingleJS from "@wllama/wllama/src/single-thread/wllama.js?url";import wllamaSingle from "@wllama/wllama/src/single-thread/wllama.wasm?url";import { Template } from "@huggingface/jinja";const wllama = new Wllama({"single-thread/wllama.js": wllamaSingleJS,"single-thread/wllama.wasm": wllamaSingle,});/* You can find more models at HuggingFace: https://huggingface.co/models?library=gguf* You can also download a model of your choice and place it in the /public folder, then update the modelUrl like this:* const modelUrl = "/<your-model-file-name>.gguf";*/const modelUrl = "https://huggingface.co/neopolita/smollm-135m-instruct-gguf/resolve/main/smollm-135m-instruct_q8_0.gguf";/* See more about templating here:* https://huggingface.co/docs/transformers/main/en/chat_templating*/const formatChat = async (messages) => {const template = new Template(wllama.getChatTemplate() ?? "");return template.render({messages,bos_token: await wllama.detokenize([wllama.getBOS()]),eos_token: await wllama.detokenize([wllama.getEOS()]),add_generation_prompt: true,});};function App() {// previous state declarations...const submitPrompt = async () => {setIsLoading(true);if (!wllama.isModelLoaded()) {await wllama.loadModelFromUrl(modelUrl, {n_threads: 1,useCache: true,allowOffline: true,progressCallback: (progress) => setProgress((progress.loaded / progress.total) * 100),});}const promptObject = { role: "user", content: prompt.trim() };setOutput([promptObject]);await wllama.createCompletion(await formatChat([promptObject]), {nPredict: 256,sampling: { temp: 0.4, penalty_repeat: 1.3 },onNewToken: (token, piece, text) => {setOutput([promptObject, { role: "assistant", content: text }]);},});setIsLoading(false);};// rest of existing code...}export default App;
Ps: huggingface 可以使用国内镜像下载模型文件 HF-Mirror
恭喜你!👏至此,您已经拥有了一个完全在浏览器中运行的AI聊天界面!
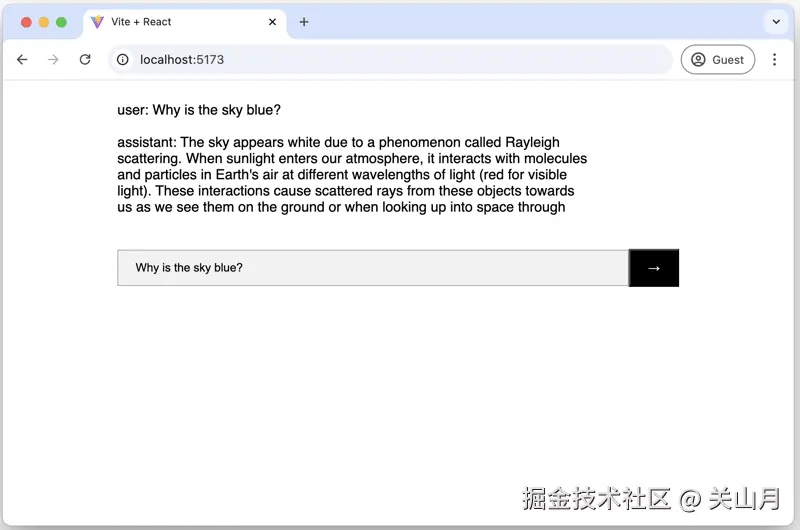
您的web应用程序将:
-
在第一次使用时下载并缓存模型,以便以后完全脱机。
-
在浏览器中使用CPU本地处理提示
-
生成响应时进行流处理
使用
npm run dev 启动它并访问http://localhost:5173/。测试它🎉👏
目前的限制😅
-
目前仅支持cpu(尚未支持WebGPU)
-
模型的文件大小限制为2GB,但有一个解决方案可以拆分它们(请参阅Wllama文档)。
类似的项目😎
————————————————
版权声明:本文为稀土掘金博主「关山月」的原创文章
原文链接:https://juejin.cn/post/7431743236534829106
如有侵权,请联系千帆社区进行删除
评论
