您应该了解的三大LLM框架
大模型开发/技术交流
- LLM
11月13日65看过
LLM 领域出现了很多库和框架。对于开发人员来说,要跟踪并为您的 LLM 项目选择最合适的库和框架是一件非常困难的事情。在本文中,我们将深入探讨整个生产 LLM 工作流程,重点介绍并评估这些技术:
-
Unsloth.ai(用于微调)
-
AdalFlow(用于预生产和优化)
-
vLLM(用于模型服务)
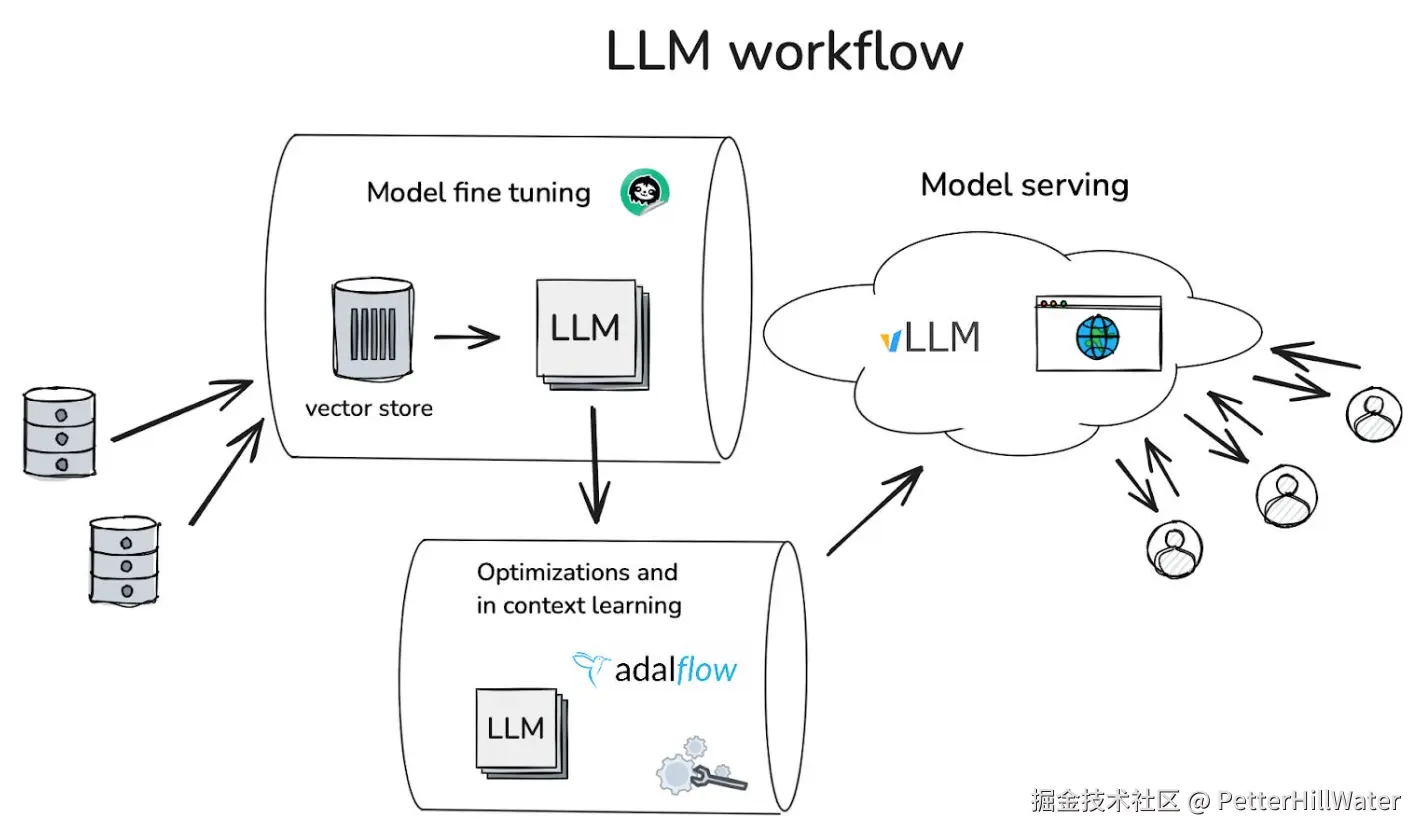
标准的 LLM 工作流程
第一步:微调
Hugging Face 是对专有数据进行微调的首选起点,我们选择了 Unsloth.ai,因为它对较大模型的性能进行了优化,尽管与 FastAI 等替代方案相比,Unsloth.ai 较新,风险稍高。
第二步:优化和预生产
虽然 LangChain和 LlamaIndex在概念验证方面很受欢迎,但我们发现了一个更轻量级的框架--Adalflow。与 DsPy 和 TexGrad 等并非基于生产级架构构建的工具相比,它有效地将预生产工作、优化和上下文学习结合在一起,并具有出色的调试能力。
第三步:模型服务
一. 用于模型微调的 Unsloth.ai
LLM 需要大量 GPU,而且时间非常紧迫。这是不可避免的!训练甚至微调某些模型可能需要几个月的时间,这就成为一个巨大的可访问性问题。Unsloth 在模型训练方法上具有创新性。他们采取了以下措施来尽量减少内存使用:
-
Unsloth 不使用默认的 autograd 实现梯度计算。他们在训练 LoRA 适配器的注意机制中手动计算梯度。
-
他们还用 OpenAI 的 Triton 语言重写了内核
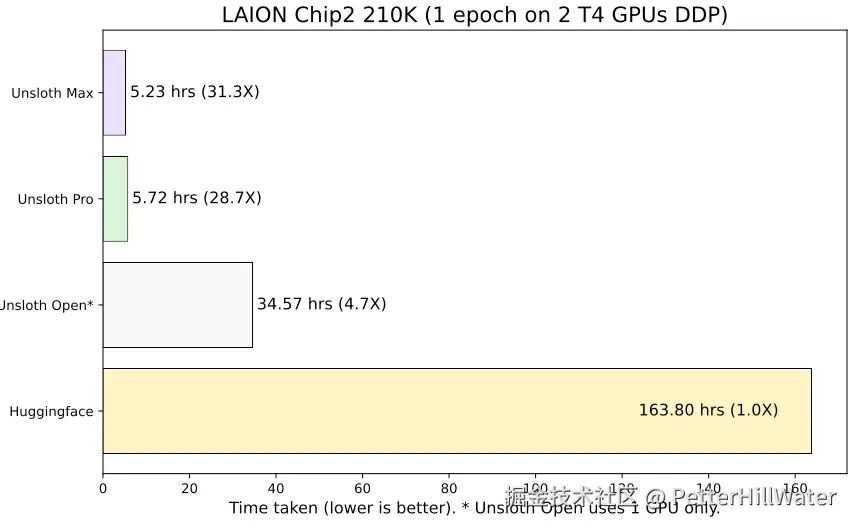
通过所有这些优化,微调 LLM 的速度提高了 30 倍,所需的内存减少了 90%!这一切都不需要新的额外硬件,而且无论您拥有哪种 GPU 设置,都可以使用这些技术。
以下是其网站上的性能对比图:
图形处理器支持
Unsloth AI 提供广泛的 GPU 支持,涵盖英伟达(从 T4 到 H100)、AMD 和英特尔硬件,因此无论您是使用云基础设施还是本地机器,都可以使用 Unsloth AI。该平台减少了 90% 的内存,可以灵活地使用不同的模型和批量大小进行实验,从而更容易找到特定用例的最佳模型配置,而无需进行昂贵的硬件升级。
闪存注意实施
为了进一步提高训练效率,Unsloth AI 通过使用 xFormers 和 Tri Dao 的实现,将 Flash Attention 纳入其中。Flash Attention 是一种针对变压器模型的优化注意力机制,可显著降低训练过程中的计算开销和内存使用量。通过利用这一先进技术,Unsloth AI 加快了训练过程并提高了可扩展性,从而可以更高效地处理大型数据集和复杂模型。
二. 用于模型服务的 vLLM
众所周知,LLM 训练需要大量 GPU;但鲜为人知的是,LLM 服务也需要大量资源。对于一个 “仅 ”有 13B 参数的模型来说,单个 A100 GPU 每秒只能处理约 1 个请求。
为了更有效地管理虚拟内存,vLLM 建立了分页关注(Paged Attention)
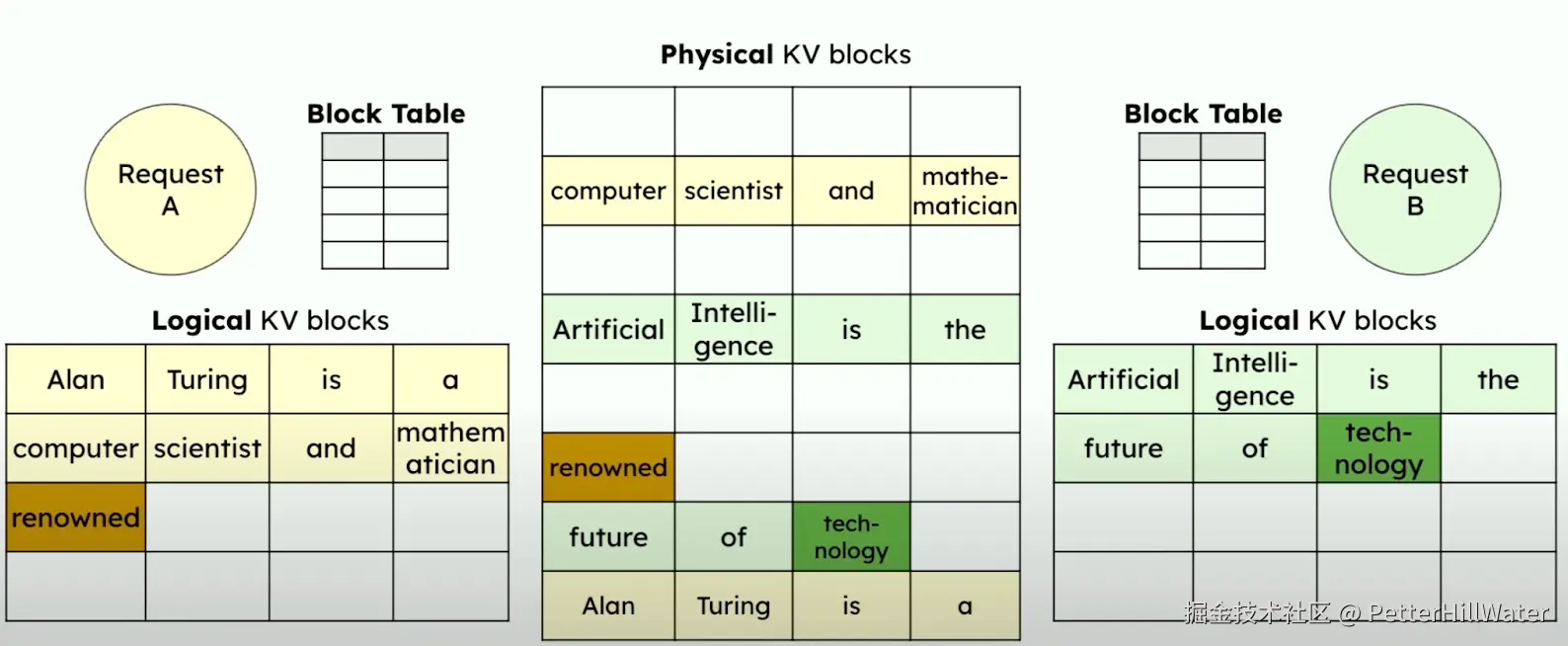
Paged Attention方法可视化示例
大多数转换器实现都跳过了键值(KV)缓存,但通过在不同请求之间有效共享内存,可以大大节省空间,这一点在他们的研究论文中已经得到了证明。vLLM 还使用了自动前缀缓存(APC)。APC 对现有查询进行缓存,因此如果查询共享相同的前缀,新查询将跳过共享部分的计算,从而提高计算效率。
实用的 vLLM 功能
高吞吐量
vLLM 通过减少内存浪费(4% 对传统的 60-80%)、高效的请求批处理和推测解码(通过预测下一个最有可能的令牌来提高令牌生成速度),实现了比 HuggingFace Transformers 高 24 倍的吞吐量。
vLLM 还支持各种模型优化技术,包括 INT4/INT8/FP8 量化和 LoRA 微调,以缩小模型尺寸并加快推理速度。
部署灵活性
vLLM 提供全面的部署选项,包括在线和离线推理、兼容 OpenAI 的 API 以及对各种硬件(包括 Nvidia、AMD、Intel 和 AWS Neuron 加速器)的支持。
三.用于预生产和上下文学习优化的 AdalFlow
LLM 的兴起造成了社区分裂,研究人员为基准测试编写了难以生产的零抽象代码,而工程师则依赖于 LangChain 和 LlamaIndex 等过于抽象的框架,事实证明,这些框架难以定制,而且黑箱操作。
AdalFlow 从 PyTorch 中汲取灵感,让工程师和研究人员无需从头开始构建框架,就能研究重要的问题,同时提供 API 的灵活性和可观测性。
AdalFlow 可以通过自动提示词优化
因此,想象一下您的 LLM 任务中的所有这些功能,同时还具有出色的调试、轻量级设计、恰到好处的抽象平衡,以及在零次和少量学习情况下使用的能力。这就是 Adalflow 目前提供的功能!下面是一个自动优化的提示词示例:

AdalFlow 提示词 优化前与优化后
Adalflow 功能
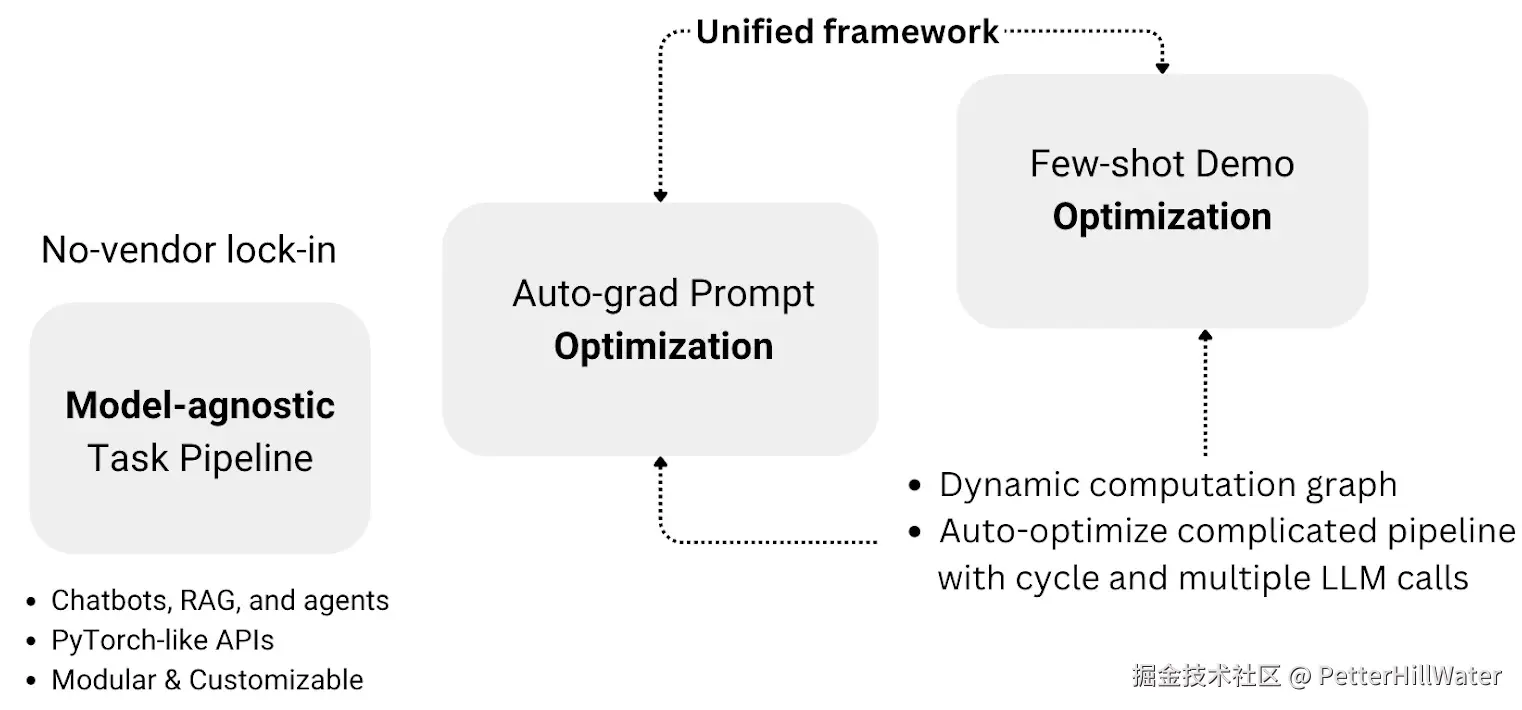
Adalflow 工作流概述、无供应商锁定以及统一框架中的优化
模型无关、高效令牌
Adalflow 支持所有主要 LLM 提供商(Mistral、OpenAI、Groq、Anthropic、Cohere),消除了供应商锁定,同时优化令牌使用,最大限度地降低 API 成本,最大限度地提高提示性能。
统一的优化框架
Adalflow 强大的自动优化系统可通过简单的参数到生成器管道实现全面的提示优化(包括指令和少量示例),推进 DsPy、Text-grad 和 OPRO的研究,同时在统一框架内保持完整的调试、可视化和培训功能。
模块化代码架构(调试和培训)
核心架构
Adalflow 的架构基于两个基本类:用于 LLM 交互的 DataClass 和用于管道管理的 Component,它们共同提供了标准化接口、统一的可视化、自动跟踪和全面的状态管理功能。
标准化接口
组件类通过同步调用(call)、异步调用(acall)和初始化的标准化方法,确保所有组件的一致性。
统一的可视化
通过 repr 方法简化了管道结构可视化,并可通过 extra_repr 进行扩展,以获得更多特定组件的细节。
自动跟踪
系统会递归监控并整合所有子组件和参数,从而创建一个用于构建和优化任务管道的综合框架。
状态管理
通过 state_dict 和 load_state_dict方法实现了稳健的状态处理,而 to_dict 则实现了跨各种数据类型的所有组件属性序列化。
总结
Unsloth.ai、AdalFlow和vLLM分别在微调、预生产和优化以及模型服务方面展现了卓越的性能和灵活性。这些框架为开发人员提供了高效、易于使用和可扩展的工具,以支持整个LLM工作流程。选择合适的框架将有助于提高LLM项目的效率和准确性,同时降低开发和维护成本。
————————————————
版权声明:本文为稀土掘金博主「PetterHillWater」的原创文章
原文链接:https://juejin.cn/post/7431859835622604815
如有侵权,请联系千帆社区进行删除
评论