TAG与RAG实现评论自动化摘要和标签
大模型开发/技术交流
- LLM
3天前100看过
背景
在数据驱动的今天,企业通过评论、调查和社交媒体互动获得大量客户反馈。虽然这些信息可以产生宝贵的洞察力,但也带来了巨大的挑战:如何从大量信息中提炼出有意义的数据。先进的分析技术正在彻底改变我们了解客户情感的方法。其中最具创新性的是表增强生成(TAG)和检索增强生成(RAG)技术,它们使企业能够利用自然语言处理(NLP)技术同时从成千上万条评论中获得复杂的见解。简化客户反馈分析,从大型数据集中高效提取洞察力,从而加强决策并提高客户参与度。本文深入探讨了 TAG 和 RAG 的工作原理、它们对数据标记和文本到 SQL 生成的影响,以及它们在现实世界中的实际应用。通过提供具体示例,我们说明了这些技术如何增强数据分析和促进知情决策,同时满足经验丰富的数据科学家和该领域新手的需求。
利用 “检索增强生成”(RAG)获得高级数据洞察力
检索-增强生成(RAG)是企业如何提取和解释海量数据的一次变革性飞跃。通过将检索机制与强大的语言模型相结合,RAG 允许用户提出自然语言问题,并从大量数据集(如客户评论或产品反馈)中获得高度相关的实时答案。本节将对 RAG 的核心组件进行分解,每个步骤都有可视化支持,以说明流程是如何运作的。
查询输入和矢量化
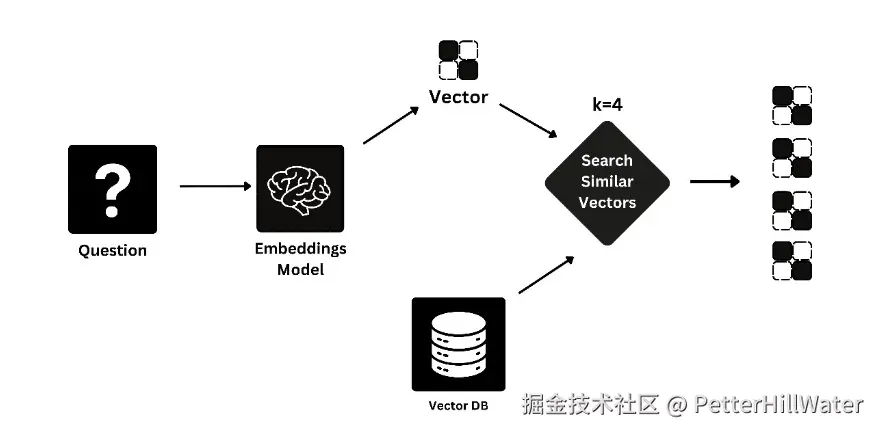
RAG 流程的第一步是查询输入和矢量化。当用户输入 “适合家庭居住的最佳酒店有哪些?”这样的查询时,RAG 会将问题转换成一种称为矢量的数字格式。这个向量代表了问题的含义,并为下一步做准备:检索相关数据。
图片 1:查询输入和矢量化示意图
该图描述了用户输入查询以及随后将查询转换为矢量格式的过程。它强调了问题如何被编码成机器可以处理的数字。
从矢量数据库检索上下文
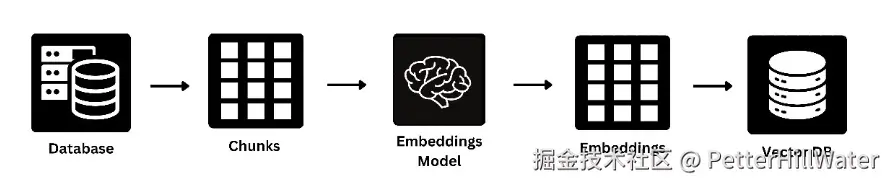
一旦查询被矢量化,RAG 就会在预先存在的矢量数据库中进行搜索,该数据库包含数以百万计的预处理信息(如客户评论、产品描述等)。RAG 系统根据语义相似性识别与查询最相关的数据。例如,如果有人询问适合家庭入住的酒店,RAG 就会提取包含家庭、儿童设施和家庭服务相关术语的评论。图片 2:从矢量数据库检索上下文的图示
本图展示了 RAG 如何从庞大的矢量数据库中检索相关评论或数据。您将看到矢量化查询是如何与系统中存储的相应相关数据点进行匹配的。
自然语言答案生成
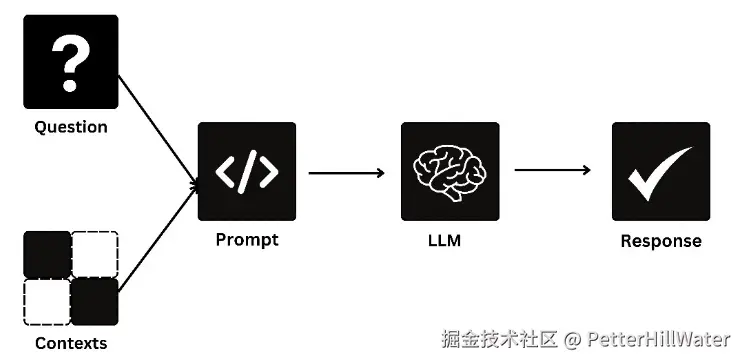
检索相关数据后,RAG 的最后一步是生成自然语言答案。检索到的评论会通过一个语言模型,该模型会将数据合成为连贯、易读的回复。通过检索数据提供的上下文,用户的查询将得到自然语言的回答。图片 3:自然语言答案生成示意图
该图说明了如何将检索到的数据转化为可读的自然语言回复。它展示了 RAG 如何从其掌握的大量数据中合成有意义的答案,使非技术用户也能访问复杂的数据集。
了解 TAG 及其作用
TAG 通过系统化的三步流程在语言模型和数据库之间建立结构化连接,从而增强了传统的文本到 SQL 方法:数据相关性和查询合成: TAG 识别相关数据以解决用户查询,生成与底层数据库结构相一致的优化 SQL 查询。
数据库执行: 针对数据集执行生成的 SQL 查询,有效过滤和检索相关见解。
自然语言答案生成: TAG 将处理过的数据转化为连贯、上下文丰富的回答,简化用户的解释。
数据标签的重要性
数据标签对于信息的组织和分类至关重要,尤其是在包含非结构化文本的数据集中。这一过程可以让系统识别模式和上下文,从而大大提高 TAG 的有效性。通过利用数据标签对海量信息(尤其是来自非结构化文本源的信息)进行系统分类,工程团队可以分配有意义的标签来训练系统识别模式和理解上下文,从而改进搜索和推荐系统等功能。
例如,当用户在搜索引擎中输入查询时,数据标签能让系统通过解读用户输入背后的意图,提供最相关的结果。同样,在社交媒体和电子商务平台中,标签数据可根据用户偏好对内容进行分类,从而实现个性化体验。因此,数据标注是技术提供商提供更智能、更高效服务的基础。
数据标签的主要优势
提高准确性: 标记数据有助于机器学习模型更好地理解用户意图,从而生成更精确的 SQL 查询。
增强查询相关性: 清晰的标识符使系统能够对结果进行优先排序,从而提高相关性。
促进用户理解: 标签提供上下文,帮助用户更轻松地解释数据。
旅游点评中的数据标签示例
家庭友好型:标识酒店是否为家庭提供便利设施,如儿童俱乐部和保姆服务。
宠物友好型: 标注可容纳宠物的酒店,提供宠物床和狗公园等相关服务。
豪华:标示提供优质服务和独家设施的高端酒店。
物有所值: 突出提供优质服务的经济型酒店。
描述性标签使企业能够简化检索流程,确保用户及时获得相关信息。
通过旅游点评数据利用 TAG
考虑一个包含评论者 ID、酒店 ID、评论者姓名、评论文本、摘要和总体评分等字段的旅游评论数据集。这些结构化数据构成了根据不同用户需求生成可操作洞察的基础。
步骤
步骤 1:数据导入和准备
流程的第一步是导入能捕捉客户感受的数据集,包括总体评分和反馈。这一初始阶段通常包括数据清理:
删除重复数据: 根据评论者 ID 和酒店 ID 识别并删除重复评论,以确保唯一性。
纠错: 检测并纠正错误,如拼写错误或评分标准不一致(如使用 1-5 分制与 0-10 分制)。
处理缺失值: 评估有用投票和 reviewText 等字段是否存在缺失条目,并决定适当的估算或删除策略。预处理:
文本规范化: 通过将文本转换为小写字母、删除特殊字符并确保格式一致,使文本标准化。
标记化: 将评论文本分解为单个标记(单词或短语),以便于分析。
删除停滞词: 过滤掉对分析没有意义的常用词。
词母化/词干化: 将单词还原为基本形式,以统一变体。
NLP 技术:
情感分析: 为评论分配情感分数,以评估整体客户满意度。
关键词提取: 使用 TF-IDF 或主题建模(如 LDA)等技术识别评论中的关键主题。可扩展性和性能
处理更大的数据集:
分布式计算: TAG 可利用 Apache Spark 或 Dask 等框架在多个节点上处理数据,从而提高处理大型数据集的能力。
数据库优化: 对经常查询的字段建立索引,以提高搜索性能。
权衡利弊:
速度与准确性: 优化性能可以加快查询执行,但可能会影响从复杂分析中获得的深入见解。
资源利用率: 可扩展性的提高往往需要更多的计算资源,从而影响成本。平衡成本与性能至关重要。步骤 2:查询合成
这一阶段采用文本到 SQL 方法,将自然语言查询转换为可执行的 SQL 语句。自然语言处理 (NLP):
意图分析: 分析用户的查询,以确定其基本意图(例如,寻求家庭友好型酒店的信息)。
实体识别: 识别查询中的关键实体,重点关注与酒店特色相关的关键字。
查询映射: TAG 将用户的意图映射到相关的数据库表格和字段。例如,如果用户查询家庭友好型酒店,TAG 就会识别与家庭设施相关的关键字。
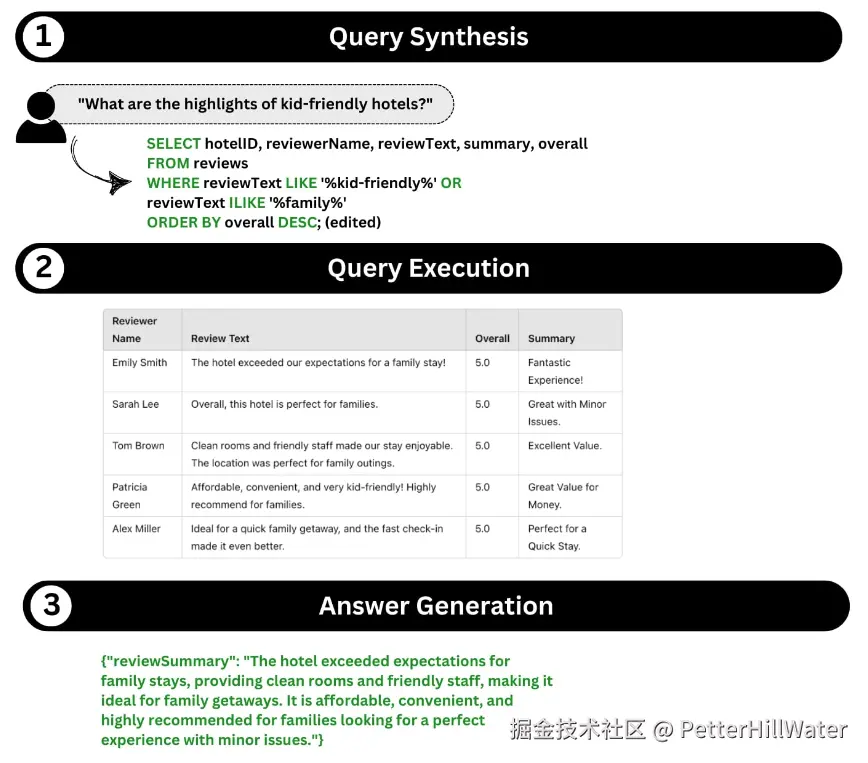
SQL 生成: 根据映射,TAG 构建 SQL 查询。对于用户查询 “适合儿童的酒店有哪些亮点?”,生成的 SQL 可能是
SELECT hotelID, reviewerName, reviewText, summary, overallFROM reviewsWHERE reviewText LIKE '%kid-friendly%' OR reviewText ILIKE '%family%'ORDER BY overall DESC;
此 SQL 语句按评分排序,检索提及家庭友好功能的酒店,使企业能够从旅游评论数据中获得有价值的见解。
查询示例
为了说明 TAG 如何处理有关酒店功能的各种查询,请参考以下示例:问题 适合儿童的酒店有哪些亮点?
问题:哪些酒店最适合养狗人士?哪些酒店最适合养狗人士?执行查询
合成查询后,执行查询会产生有价值的结果。下面是执行 SQL 查询后的输出数据示例:
| Reviewer Name | Review Text | Overall | Summary || Emily Smith | The hotel exceeded our expectations for a family stay! | 5.0 | Fantastic Experience! || Sarah Lee | Overall, this hotel is perfect for families. | 5.0 | Great with Minor Issues. || Tom Brown | Clean rooms and friendly staff made our stay enjoyable. The location was perfect for family outings. | 5.0 | Excellent Value. || Patricia Green | Affordable, convenient, and very kid-friendly! Highly recommend for families. | 5.0 | Great Value for Money. || Alex Miller | Ideal for a quick family getaway, and the fast check-in made it even better. | 5.0 | Perfect for a Quick Stay. |
自然语言生成答案
在检索相关数据后,TAG 采用 RAG 生成简明摘要。以下是这一过程的工作原理:
在检索相关数据后,TAG 采用 RAG 生成简明摘要。以下是这一过程的工作原理:
from langchain import OpenAI, PromptTemplate, LLMChainimport sqlite3# Establish connection to the SQLite databasedef connect_to_database(db_name):"""Connect to the SQLite database."""return sqlite3.connect(db_name)# Function to execute SQL queries and return resultsdef execute_sql(query, connection):"""Execute the SQL query and return fetched results."""cursor = connection.cursor()cursor.execute(query)return cursor.fetchall()# Define your prompt for SQL query synthesisquery_prompt = PromptTemplate(input_variables=["user_query"],template="Generate an SQL query based on the following request: {user_query}")# Initialize the language modelllm = OpenAI(model="gpt-3.5-turbo")# Create a chain for generating SQL queriesquery_chain = LLMChain(llm=llm, prompt=query_prompt)# Define your prompt for generating natural language answersanswer_prompt = PromptTemplate(input_variables=["results"],template="Based on the following results, summarize the highlights: {results}")# Create a chain for generating summariesanswer_chain = LLMChain(llm=llm, prompt=answer_prompt)# Function to simulate data labeling (for demonstration purposes)def label_data(reviews):"""Label data based on specific keywords in reviews."""labeled_data = []for review in reviews:if "family" in review[1].lower():label = "Family-Friendly"elif "dog" in review[1].lower():label = "Pet-Friendly"elif "luxury" in review[1].lower():label = "Luxury"else:label = "General"labeled_data.append((review[0], review[1], label))return labeled_data# Main process functiondef process_user_query(user_query):"""Process the user query to generate insights from travel reviews."""# Connect to the databaseconnection = connect_to_database("travel_reviews.db")# Step 1: Generate SQL query from user inputsql_query = query_chain.run(user_query)print(f"Generated SQL Query: {sql_query}\n")# Step 2: Execute SQL query and get resultsresults = execute_sql(sql_query, connection)print(f"SQL Query Results:\n{results}\n")# Step 3: Label the datalabeled_results = label_data(results)print(f"Labeled Results:\n{labeled_results}\n")# Step 4: Generate a summary using RAGfinal_summary = answer_chain.run(labeled_results)print(f"Final Summary:\n{final_summary}\n")# Format the output as unstructured dataformatted_output = "\n".join([f"Reviewer: {review[0]}, Review: {review[1]}, Label: {review[2]}" for review in labeled_results])print("Unstructured Output:\n")print(formatted_output)# Close the database connectionconnection.close()# Example user queryuser_query = "What are the highlights of kid-friendly hotels?"process_user_query(user_query)
输出示例
{"reviewSummary": "The hotel exceeded expectations for family stays, providing clean rooms and friendly staff, making it ideal for family getaways. It is affordable, convenient, and highly recommended for families looking for a perfect experience with minor issues.", "Label":"Kid-Friendly"}
这种方法利用 RAG 综合了单篇综述的细微差别,提供了清晰的概述,而不仅仅是结果的汇总。
使用 TAG 的改进
TAG 解决了传统的局限性,大大增强了查询过程:增强查询合成: TAG 综合考虑了整个数据库结构的优化查询,支持更广泛的自然语言查询。
高效的数据库执行: TAG 可在大型数据集上快速执行查询,便于快速检索重要见解,以做出具有时效性的决策。
改进自然语言生成: 通过利用先进的语言模型,TAG 可生成连贯的、与上下文相关的响应,从而简化用户的解释。与现有方法相比的优势
用户友好型交互: 用户可以用自然语言提出问题,无需 SQL 知识。
快速洞察: 快速执行查询可最大限度地减少访问相关数据所需的时间。
语境理解: 增强的摘要生成功能提高了数据的可访问性和对决策者的实用性。提升结果的重新排序策略
为确保高质量的检索结果,有效的重新排名策略可以优化结果。下面介绍几种策略:基于分数的重新排序: 利用分数(如有用性、评级)对回复进行优先排序,为可靠的审阅者分配更高的权重,以提高质量。
语义相似性: 利用嵌入来衡量语义相似性,并根据与用户查询上下文的相关性对结果进行重新排序。
上下文重排: 分析查询上下文(例如,家庭友好型),并根据评论中出现的特定关键词重新排序,以提供最相关的见解。
结论
TAG 和 RAG 走在客户反馈分析变革的前沿,使企业能够利用评论和调查中蕴含的丰富洞察力。通过自动进行数据标注、查询合成和自然语言生成,企业可以获得可操作的见解,从而加强决策过程。随着这些技术的发展,从个性化客户体验到有针对性的营销策略,潜在的应用领域非常广泛。采用 TAG 和 RAG 不仅能简化对大型数据集的分析,还能使企业在瞬息万变的市场环境中保持竞争力。
————————————————
版权声明:本文为稀土掘金博主「PetterHillWater」的原创文章
原文链接:https://juejin.cn/post/7432610923935678500
如有侵权,请联系千帆社区进行删除
评论