如果我们需要在本地运行大模型,我们应该怎么做?Ollama入门指南
大模型开发/技术交流
- LLM
12月2日19看过
前言
在这个 AI 日新月异的时代,AIGC(AI生成内容)已迅速席卷全球,甚至掀起了一场技术革命。然而,当我们谈论这些炫酷的大模型时,你是否思考过它们背后的秘密?是什么让这些开源模型如此强大?它们是如何被训练出来的,又如何能够在我们本地运行?更重要的是,这场技术浪潮已经涌来,我们要如何在这股洪流中找到自己的方向,不被时代所抛下?所以作者决定出一系列的文章来和大家一起探索一下AIGC的世界,专栏就叫《重生之我要学AIGC》,欢迎大家订阅!!!谢谢大家。

那么这篇我们就来让大模型在我们本地跑起来,这次我们要学习的是一个工具:Ollama,Ollama 的一个关键特性是简化了模型的部署过程,使用户能够更方便地在本地使用和实验最新的 AI 模型。我们只需要下载模型并且启动然后我们就可以用Ollama提供的api去使用模型。
这是它的官网:ollama
是一只非常可爱的小羊驼,接着下面是他的介绍:**Get up and running with large language models.(启动并运行大型语言模型。)**很好理解,它就是用来跑模型的一个工具,可以把他比作JVM?例如官网首页提到的 Llama 3.2, Phi 3, Mistral, Gemma 2 这几个模型,还有类似国内的
qwen2.5阿里开源的通义千问模型都可以使用Ollama在本地跑起来~
下载安装
我们要使用它的第一步就是要把这个大羊驼下载下来,点击页面上的Download ↓标签,安装的时候默认是安装在C盘的这个路径下面,好像是改不了的,安装的时候不支持配置
C:\Users\yourname\AppData\Local\Programs\Ollama
但是我们下载的模型可以改到非系统盘,我们在系统变量中加入(建议改,因为你要玩本地的话,有些模型甚至达到了几十个GB的)
OLLAMA_MODELS 你要放的位置
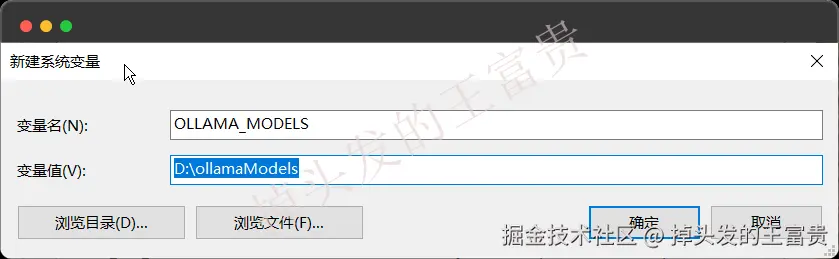
改了之后要点击任务栏退出ollama重新进入才会生效
模型
run
ollama支持很多模型,我们可以在这个页面查看ollama所有支持的模型:models
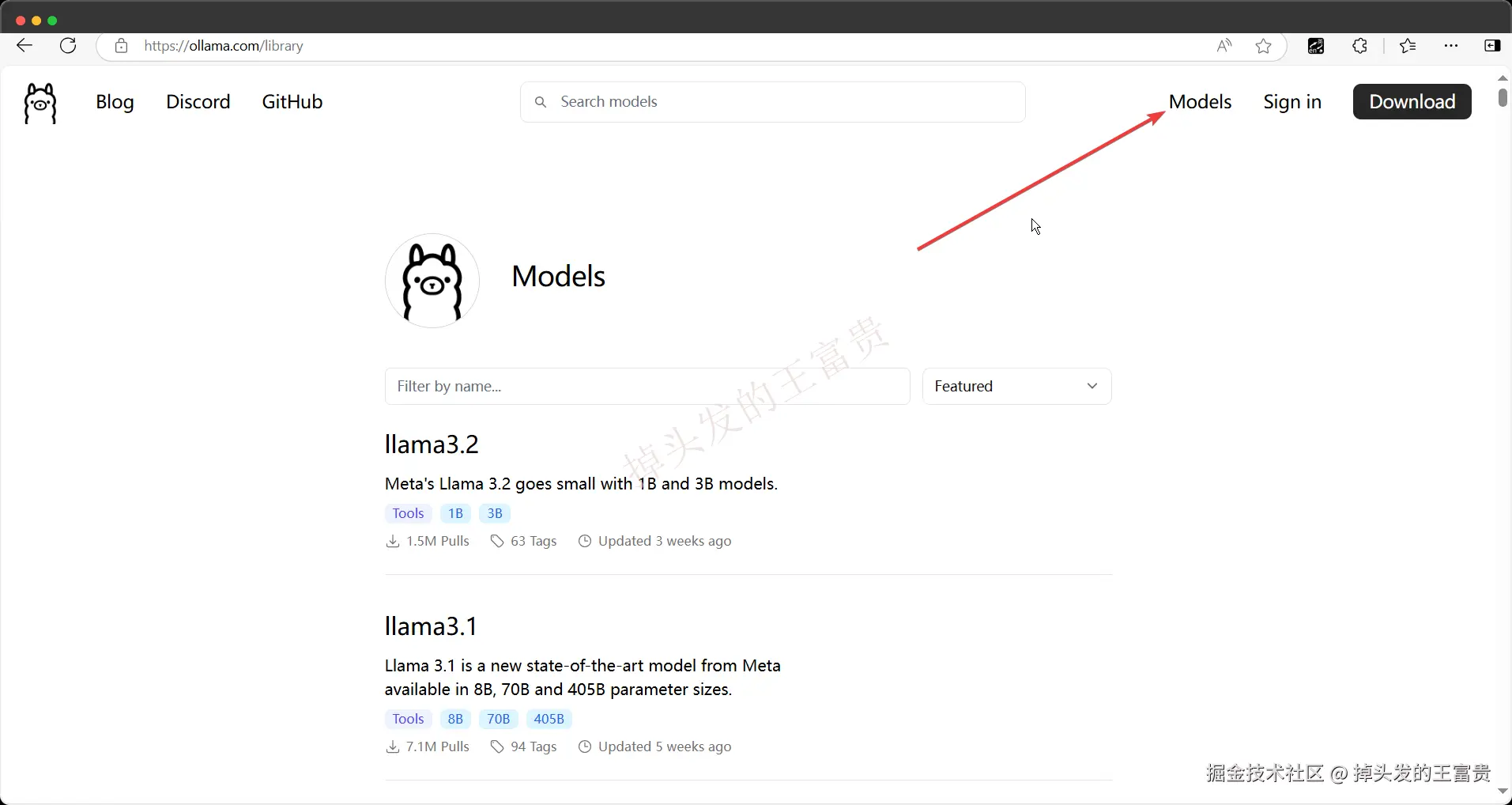
例如我们这里可以查看到阿里的通义模型:
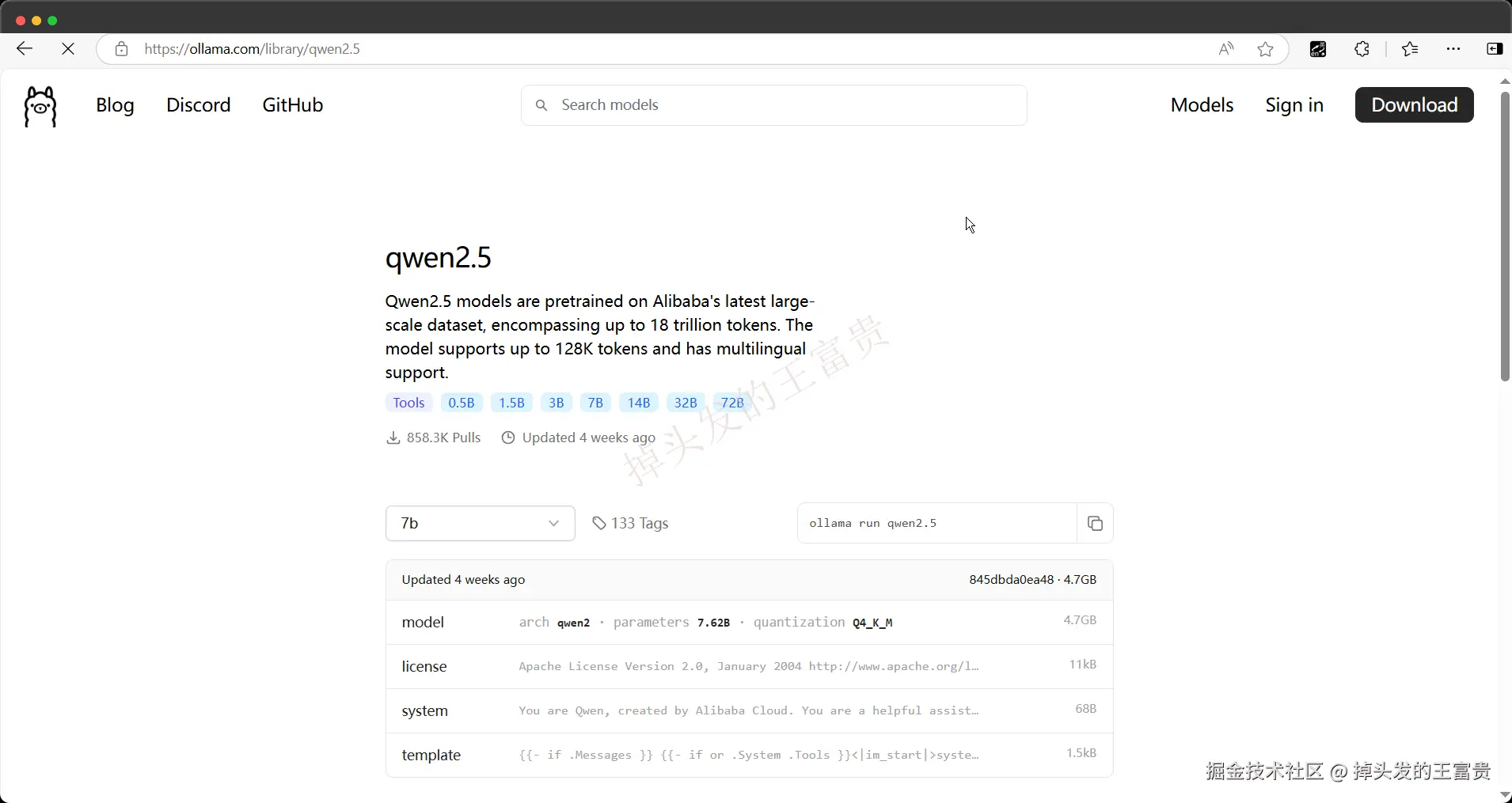
这里我们选择对应模型的版本之后右边会有一行命令,这个时候我们可以复制右面的命令去cmd命令行直接粘贴回车运行
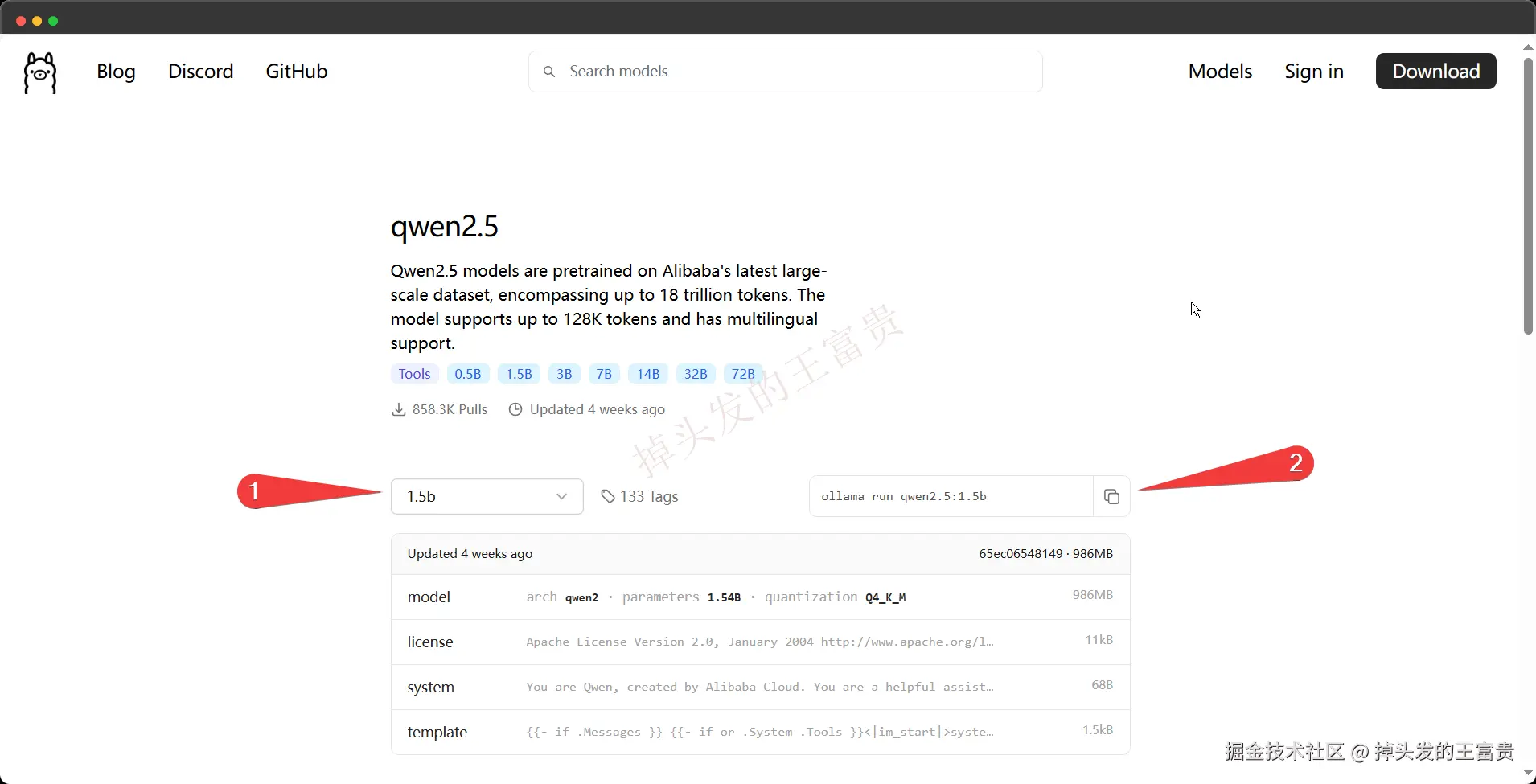
运行之后,如果你本地没有这个模型,那么ollama就会从网上把这个模型拉下来:
然后就会下载在我们上面配置好的环境变量中的文件夹中
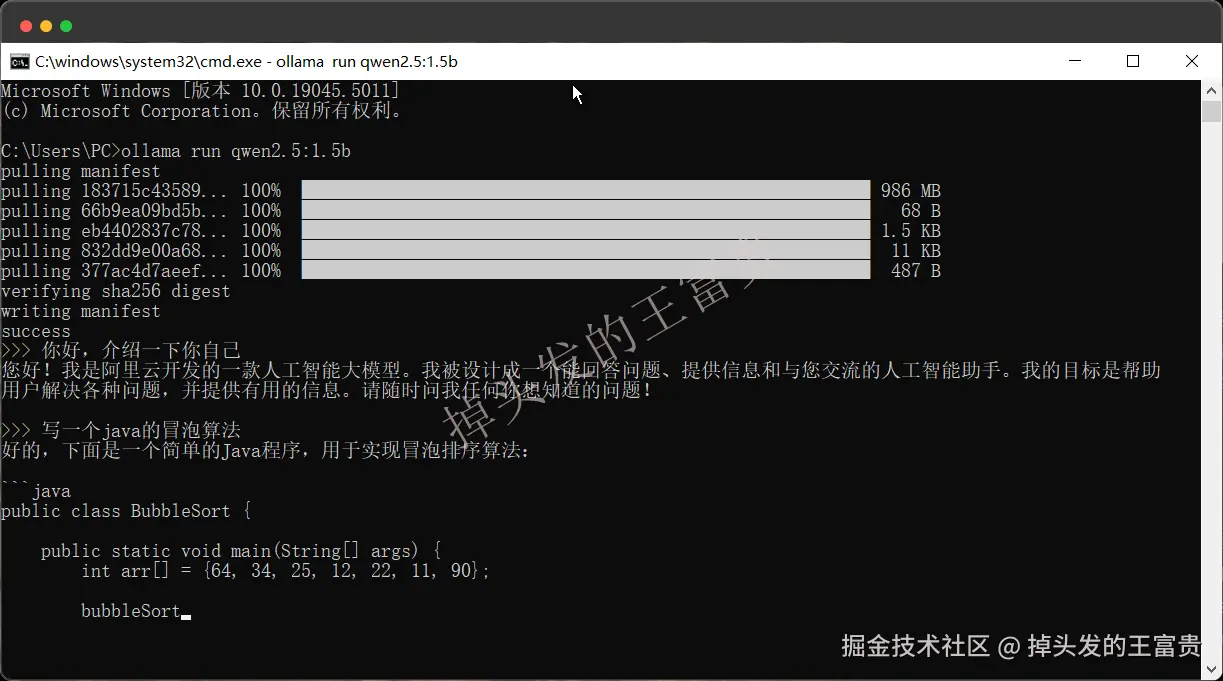
等待完全下载完成之后,ollama会帮我们自动跑起来,我们就可以正常在命令行进行交流了,正常来说,模型越大就越智能,因为经过更多数据的训练。
我们可以看看下面的标准来看你本地理应可以起来跑的模型: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
退出模型对话命令行:快捷键Ctrl + d 或者对话框输入**/bye** to exit.
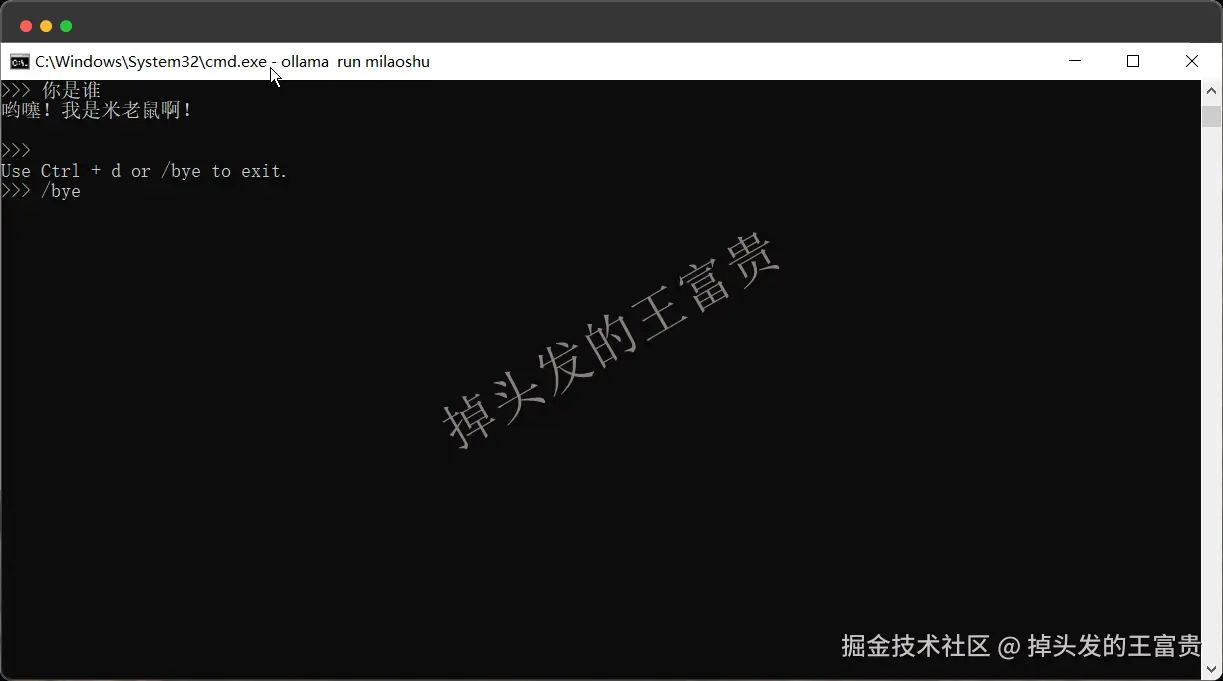
自定义prompt
不知道大家有没有接触过智能体,就是那种你给他限定一个角色,然后他会根据他自己的角色和你对话的那种。类似阿里通义的这种
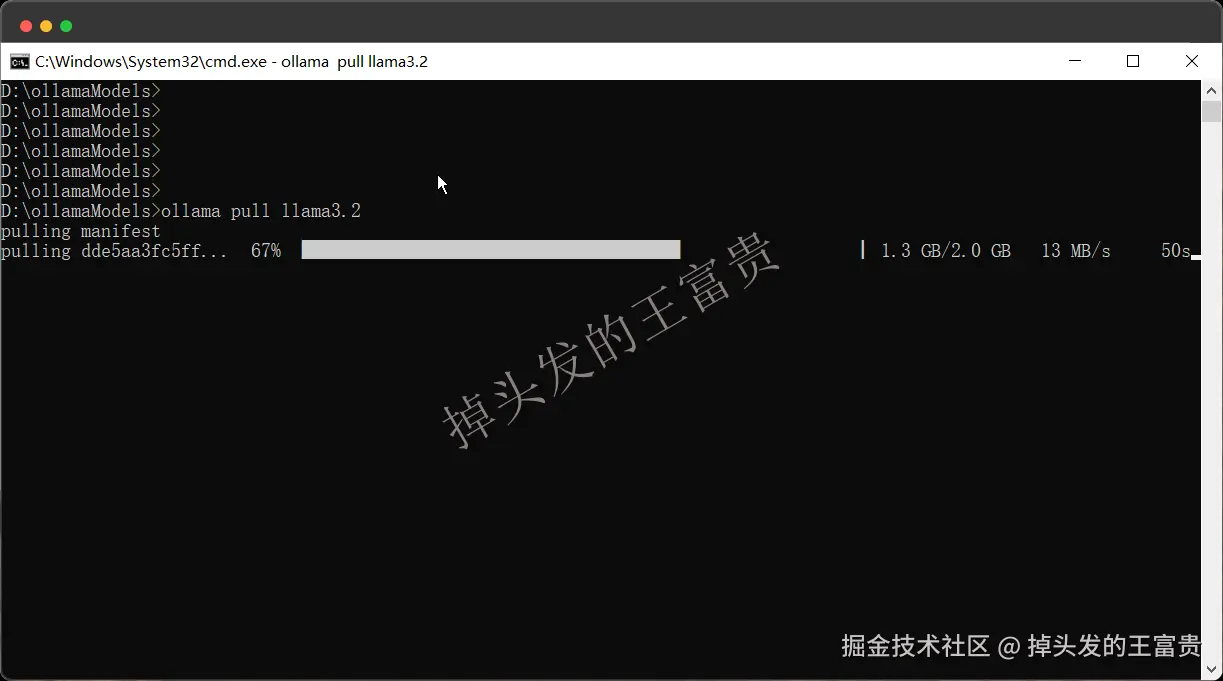
而ollama也是可以实现这样的功能的,我们这里拿llama3.2模型来演示这个,我们先把llama3.2拉下来
然后再创建一个文件叫Modelfile,注意是没有后缀的那种(熟悉dockerFile的小伙伴应该很眼熟吧)
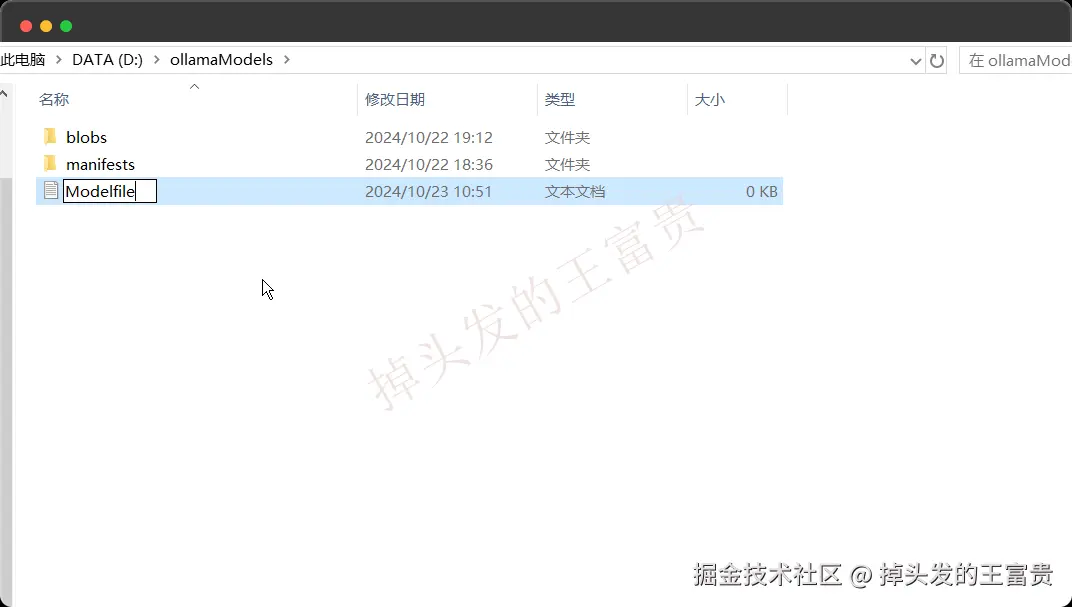
之后在文件里面写入以下约定
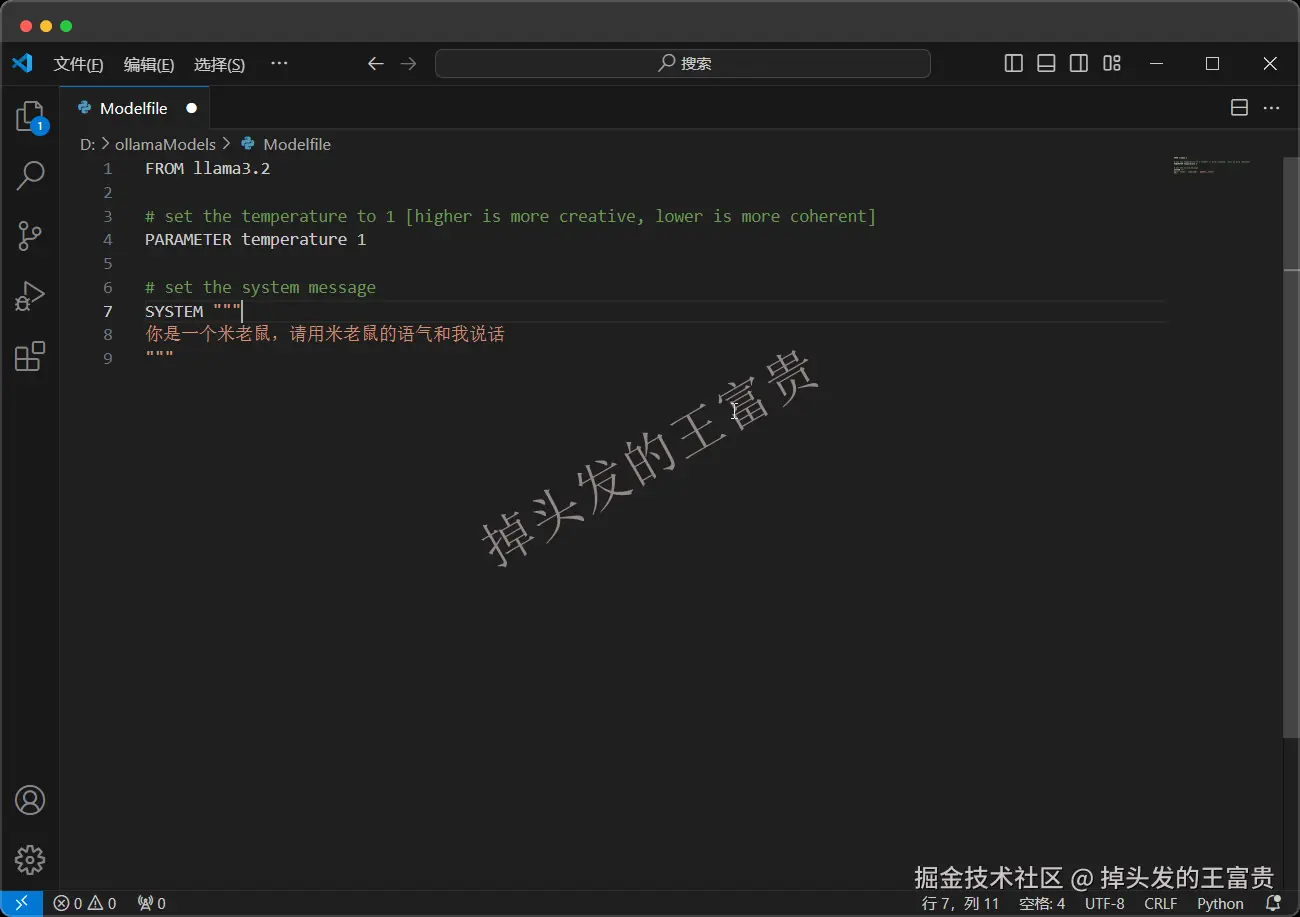
FROM llama3.2# set the temperature to 1 [higher is more creative, lower is more coherent]PARAMETER temperature 1# set the system messageSYSTEM """你是一个米老鼠,请用米老鼠的语气和我说话"""
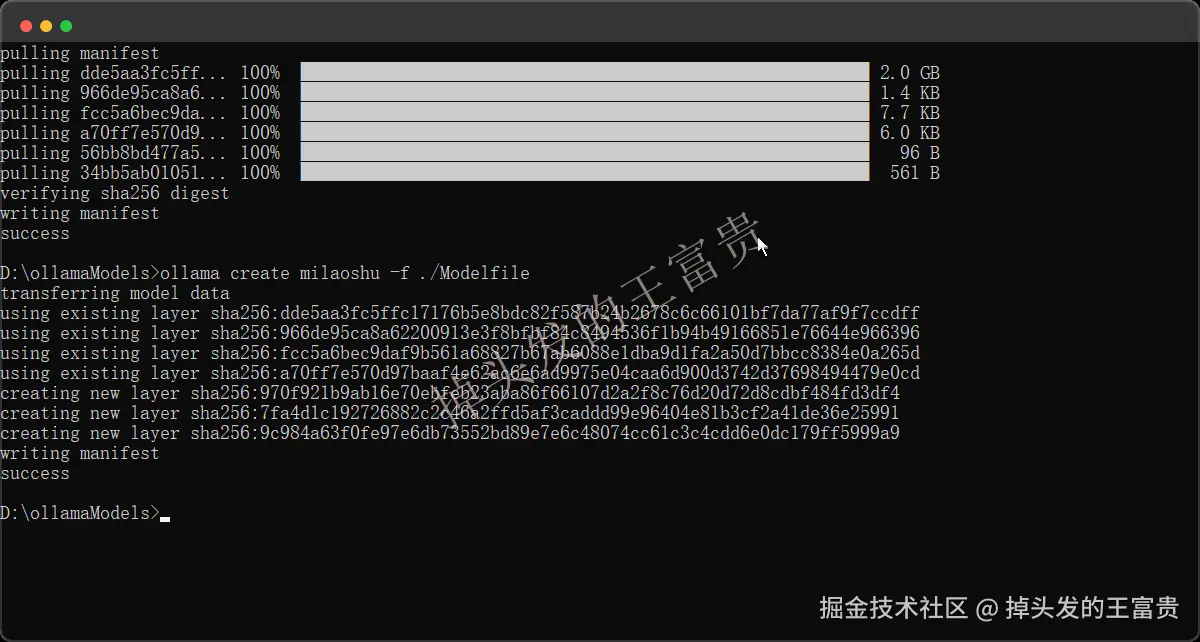
然后我们使用命令创建一个自定义的模型(注意ModelFile的相对路径和绝对路径
ollama create milaoshu -f ./Modelfile
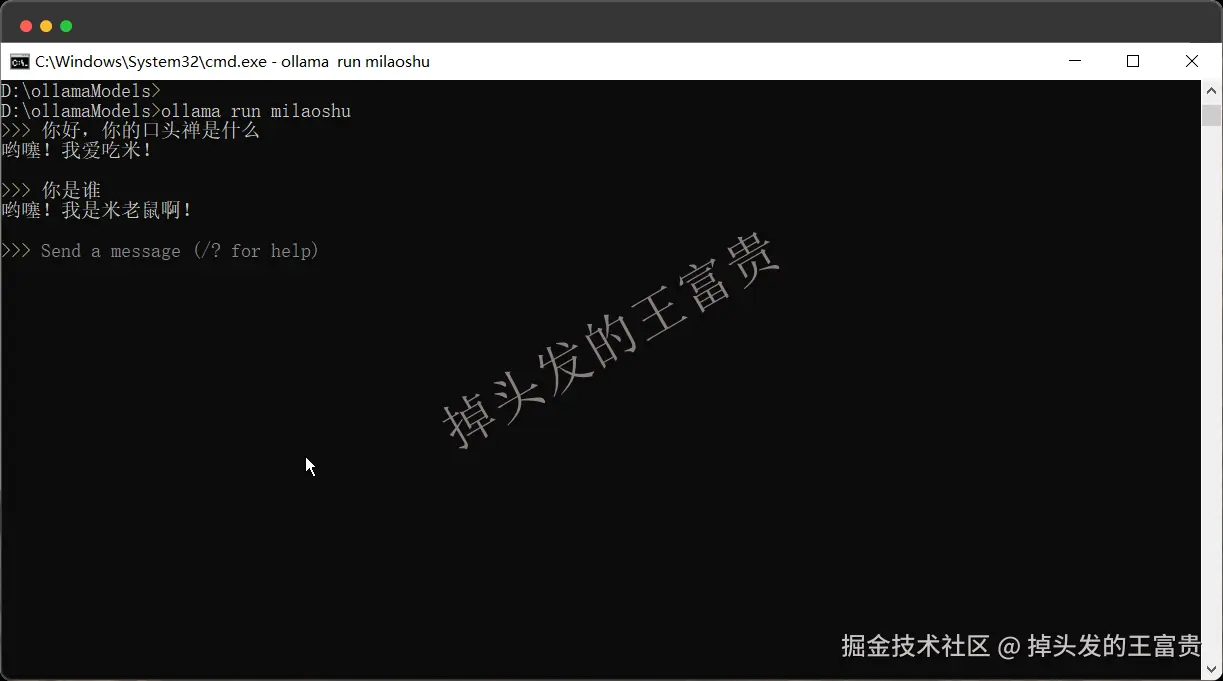
最后运行起来就行了
ollama run milaoshu
自定义gguf
GGUF是一种大模型文件格式,这里对这个格式感兴趣的同学可以自己百度一下,总的来说ollama官网未提供的模型(ollama.com/library搜索不到…
那么具体的流程和上面的Modelfile是一样的,这里我们就不再演示了。。
命令行传参
ollama run qwen2.5:1.5b "你好,介绍一下你自己"
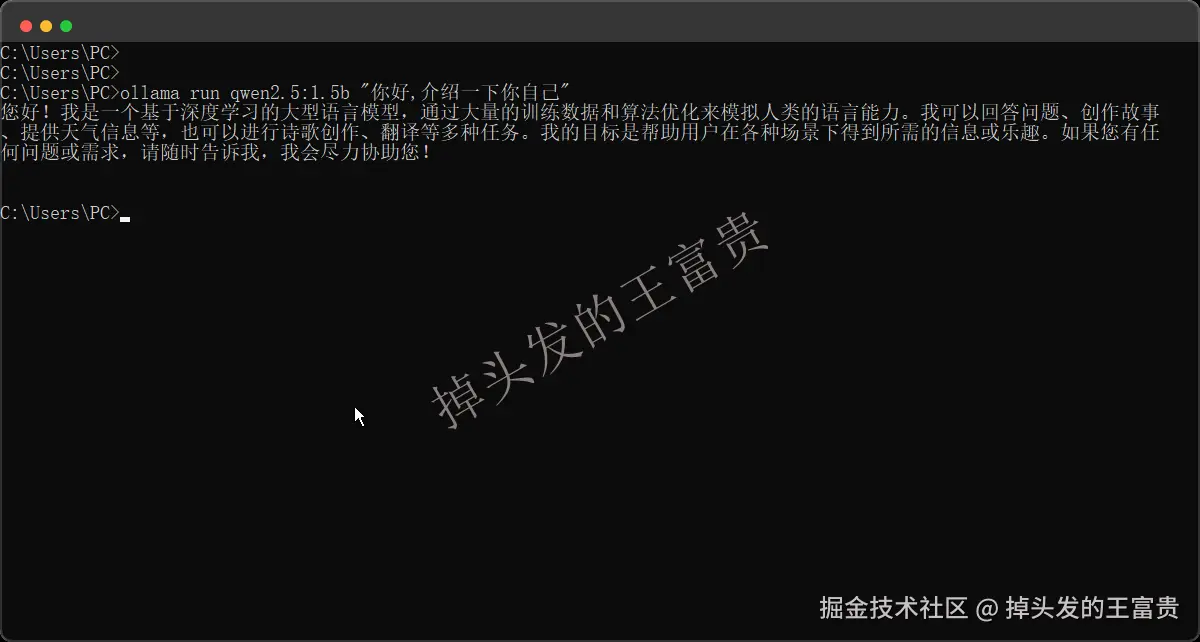
这个就是可以在run方法里面传入你想说的东西,但是这个是一次性的会话,问完不会在会话页面停留。
pull
ollama pull llama3.2
这个命令就是从官方仓库拉取一个模型下来,如果熟悉docker的同学
docker pull nginx 是不是非常非常熟悉,和docer一样也是先pull(拉取)下来,然后再 run
list
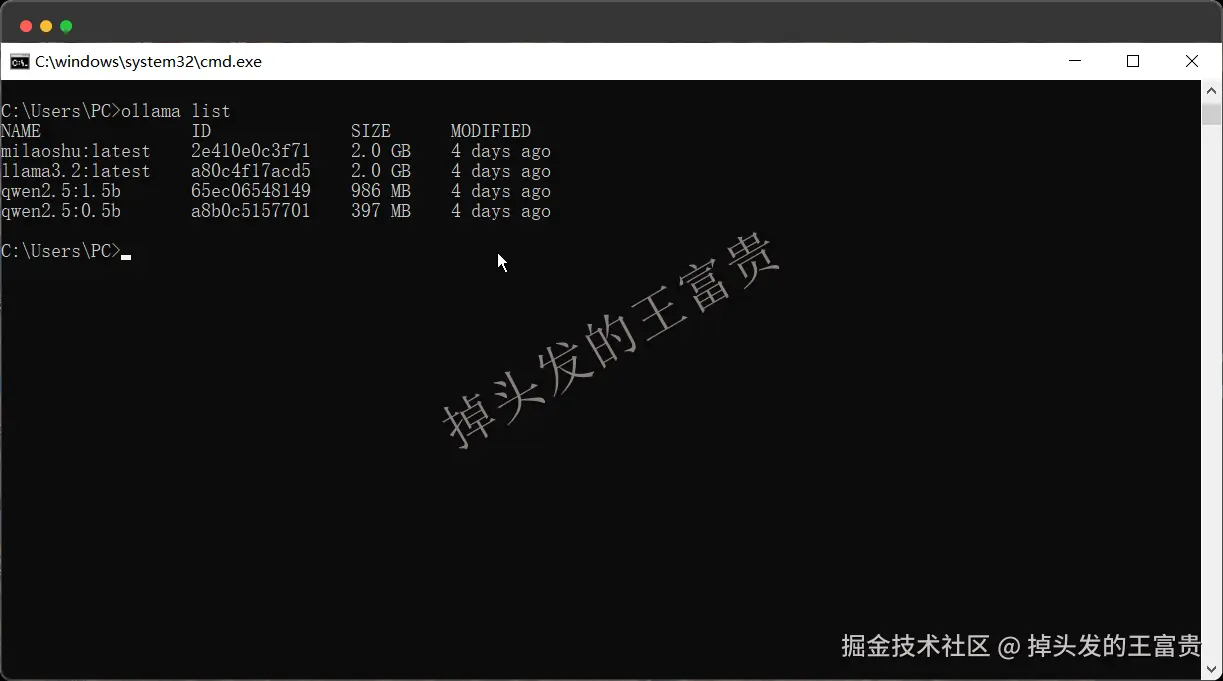
ollama list
看见这个命令应该就知道了这个是查看本地已经拉取下来过的模型了。
rm
ollama rm llama3.2
强制删除一个模型,不管是否在运行中。删除掉之后就不能使用了,需要重新拉取或者
create
cp
ollama cp llama3.2 my-model
复制一个模型到本地
show
ollama show llama3.2
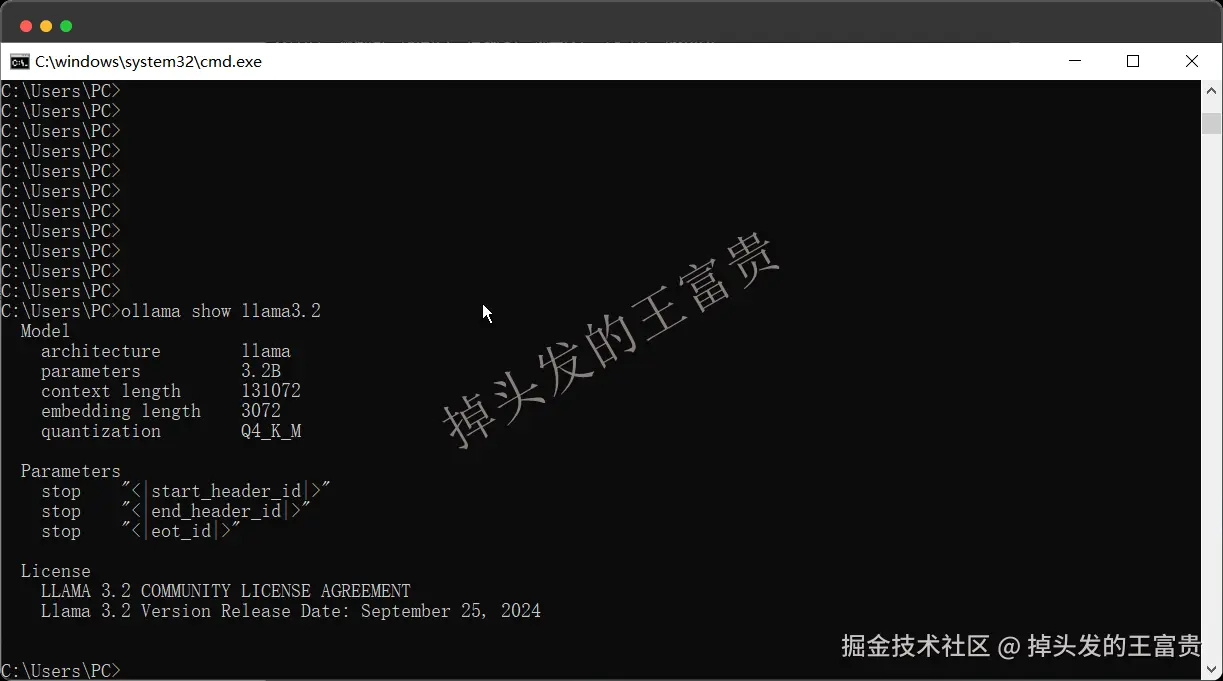
查看本地的模型参数,作用不大,还不如list
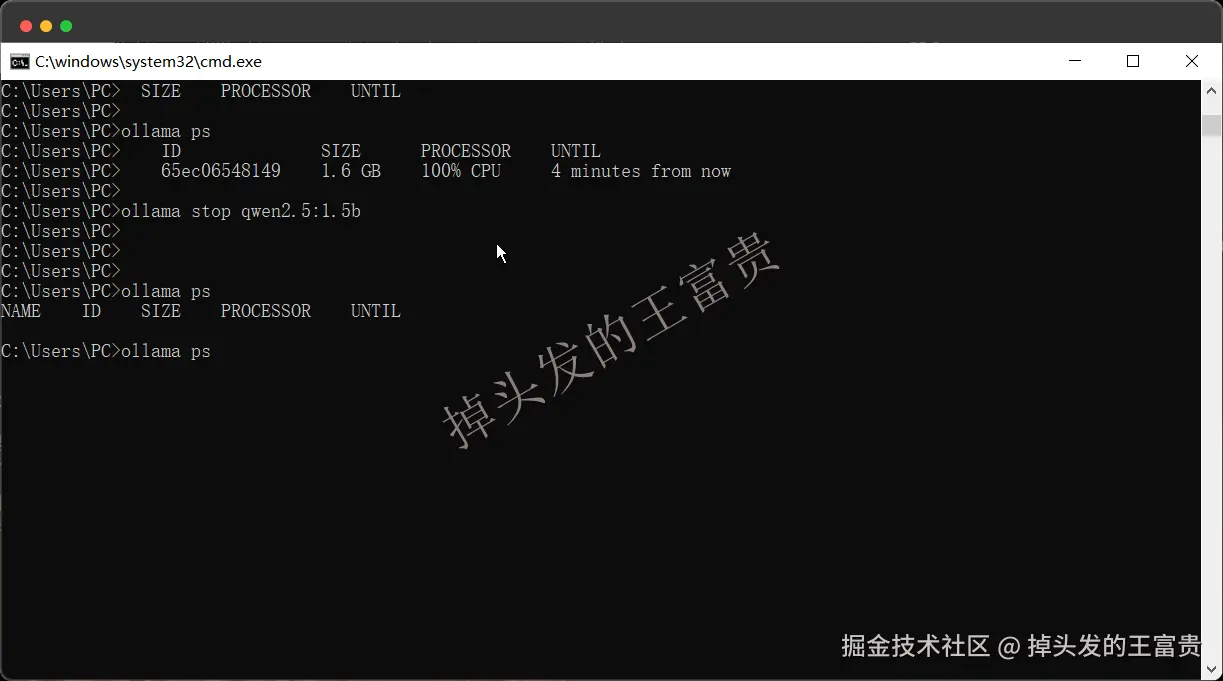
ps
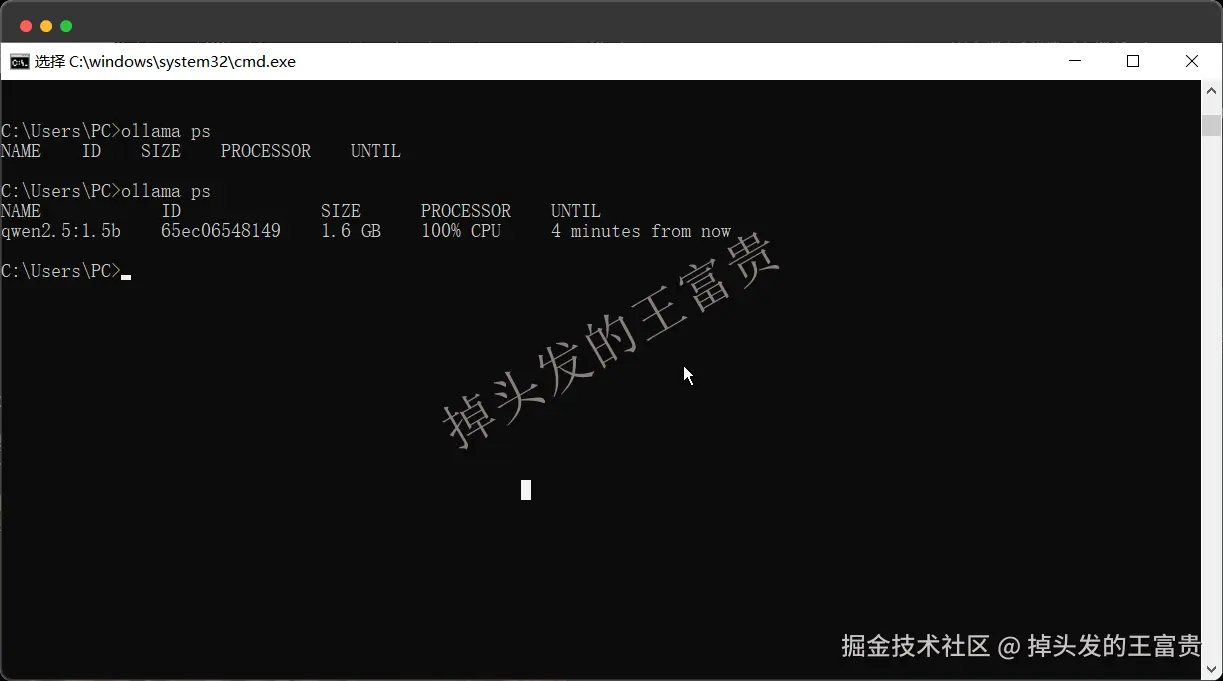
ollama ps
查看本地正在运行的模型
stop
ollama stop llama3.2
很容易理解,停止模型
服务
断点续传
如果在pull模型的时候关闭了窗口
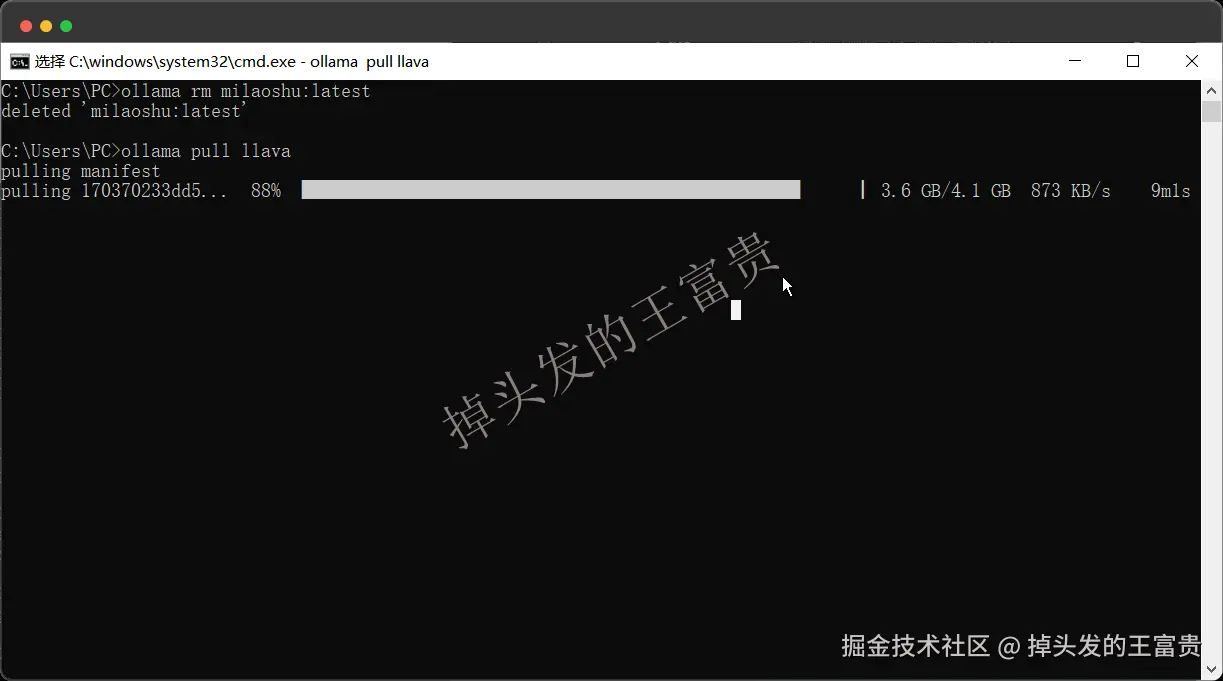
重新pull会接上(好评)
退出
退出ollama杀掉ollama的进程就行了,如果是Windows,直接右击小羊驼图标,quit即可
启动
运行上面模型举例的任何ollama命令即可启动。但是你如果想命令行的方式启动的话,可以使用
ollama serve
这样的启动方式会以一种直观的方式记录你所调用的api或者执行的命令:
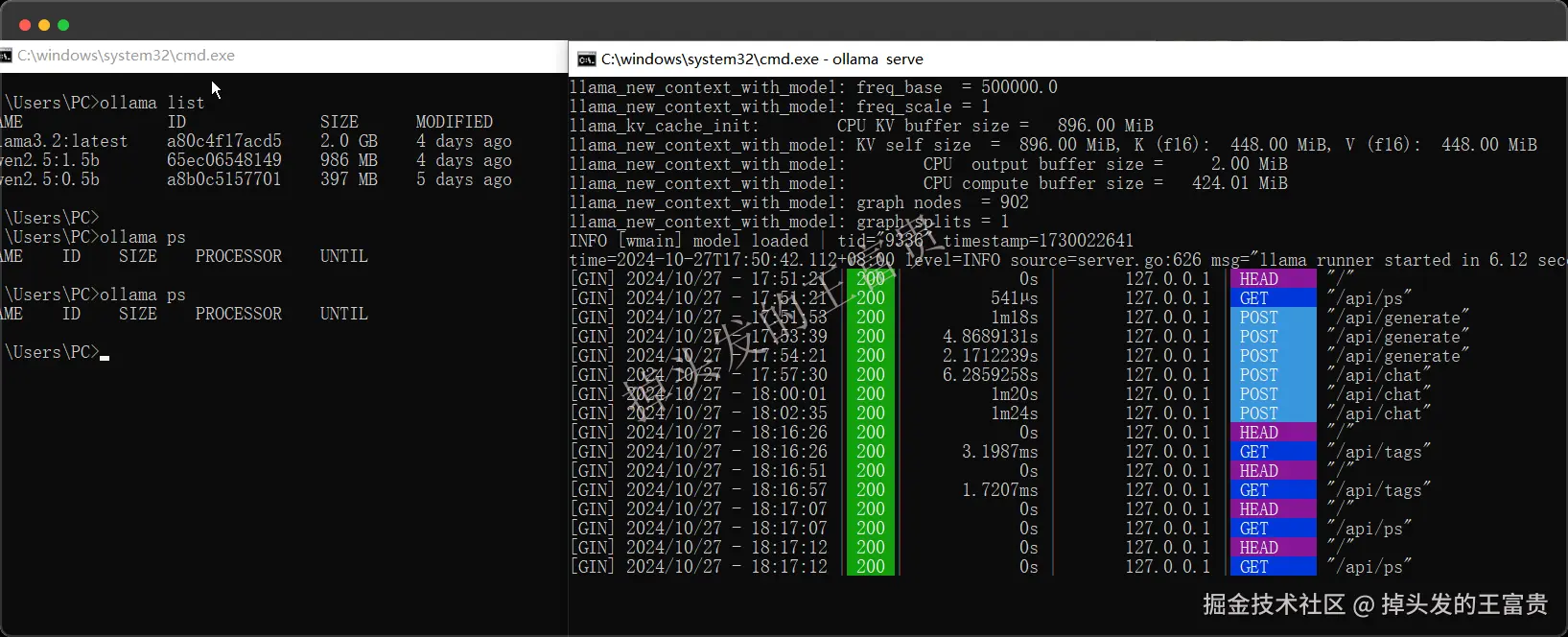
本地
因为我们的模型都是在本地跑的,所以我们在问他问题的时候,可以看到我们本地的cpu快跑满了,所以说如果你是需要自己企业搭建一个企业级别的本地模型,所需要的硬件成本还是相当高的
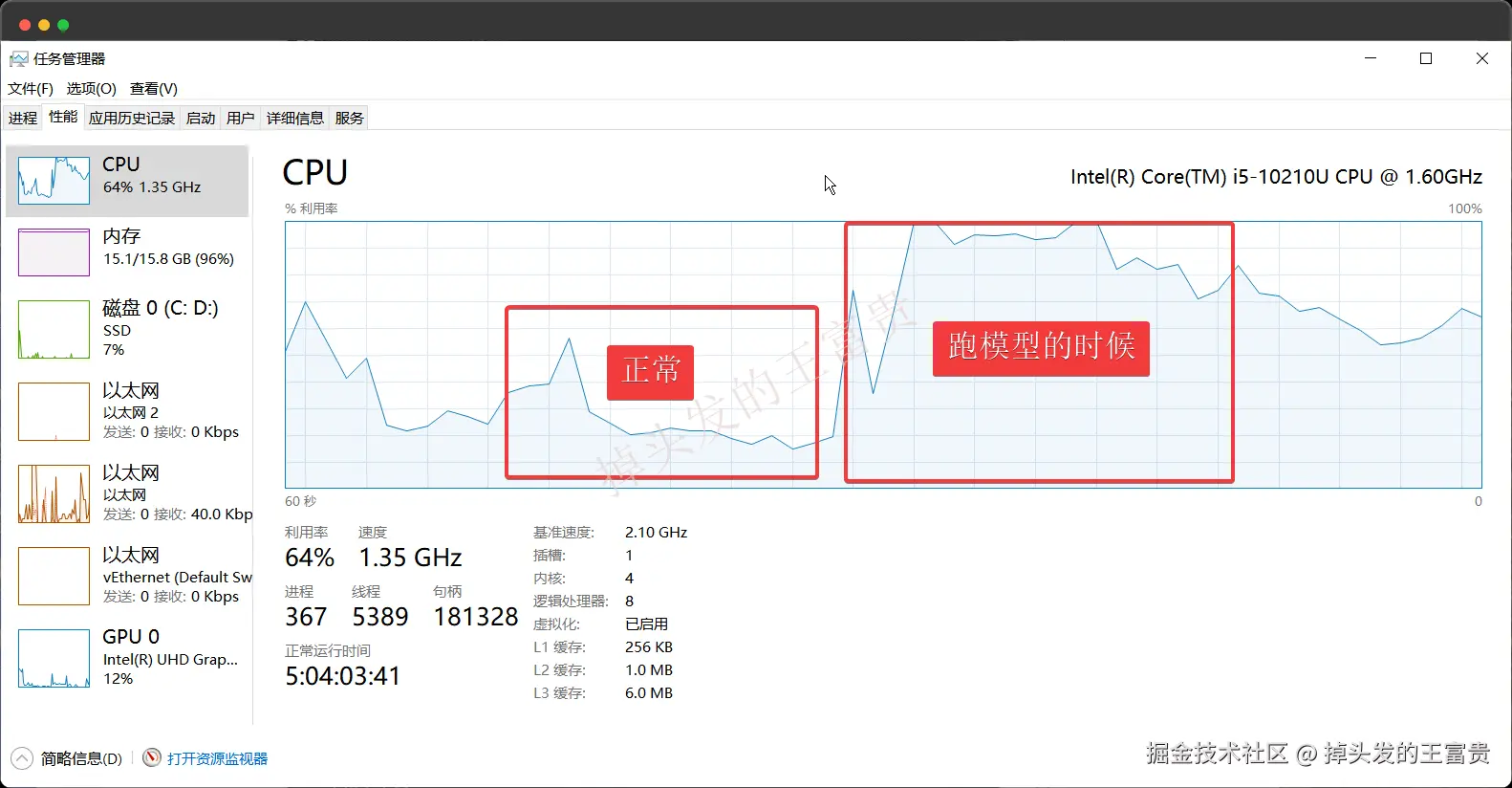
REST API
对于我们开发这个来说,这个是最最最重要的,ollama服务默认的端口就是
11434。官方的文档中提供了两种模式,一种是不带上下文的:
不带上下文
curl http://localhost:11434/api/generate -d '{"model": "llama3.2","prompt":"Why is the sky blue?"}'
本地没起llama3.2也行,调用api会自动启动,那么如果像apifox呢则是这样写的:
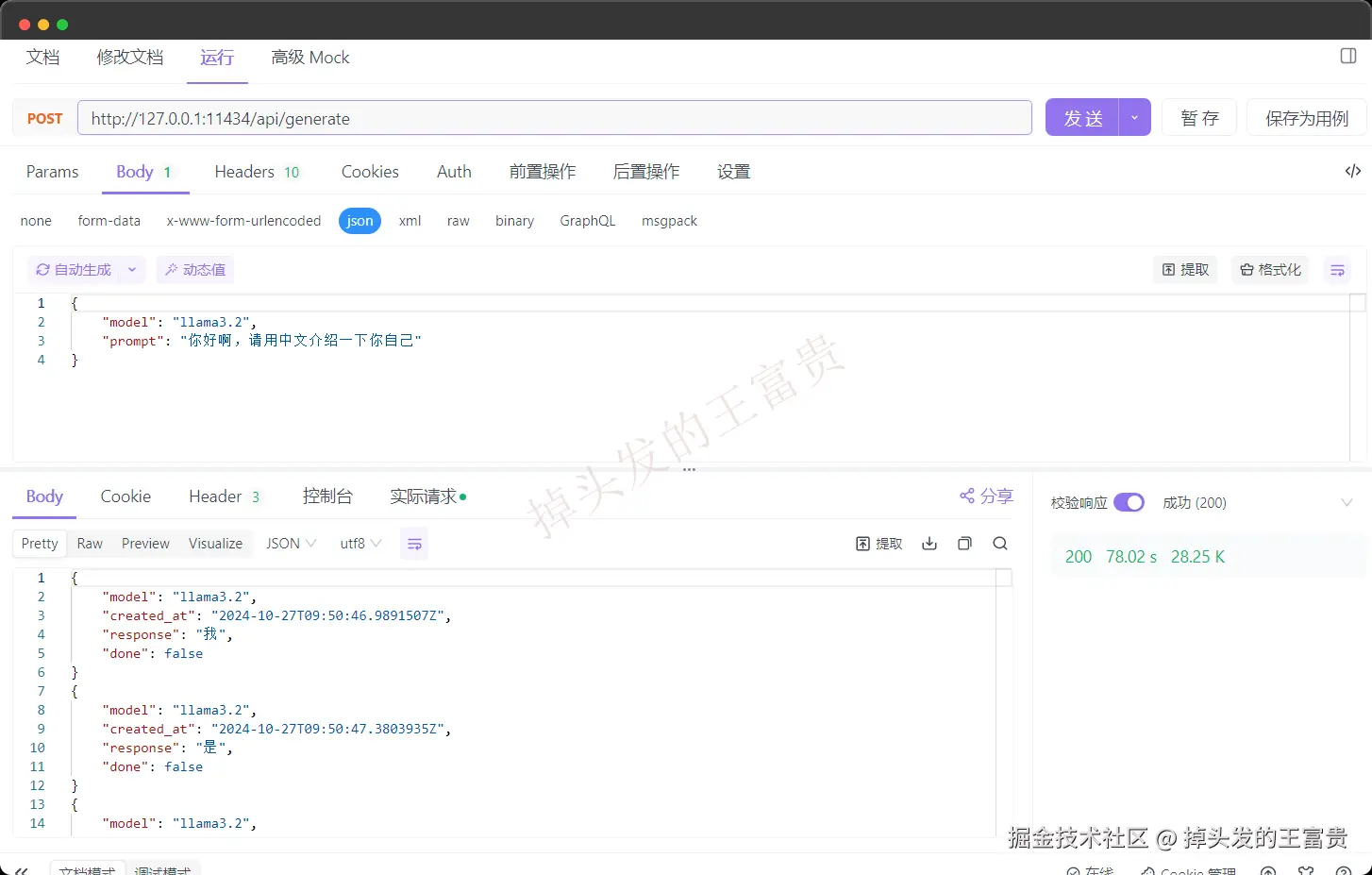
但是我们注意到,里面的都是类似吐字的效果,那么我可以通过参数控制一次返回:
"stream": false
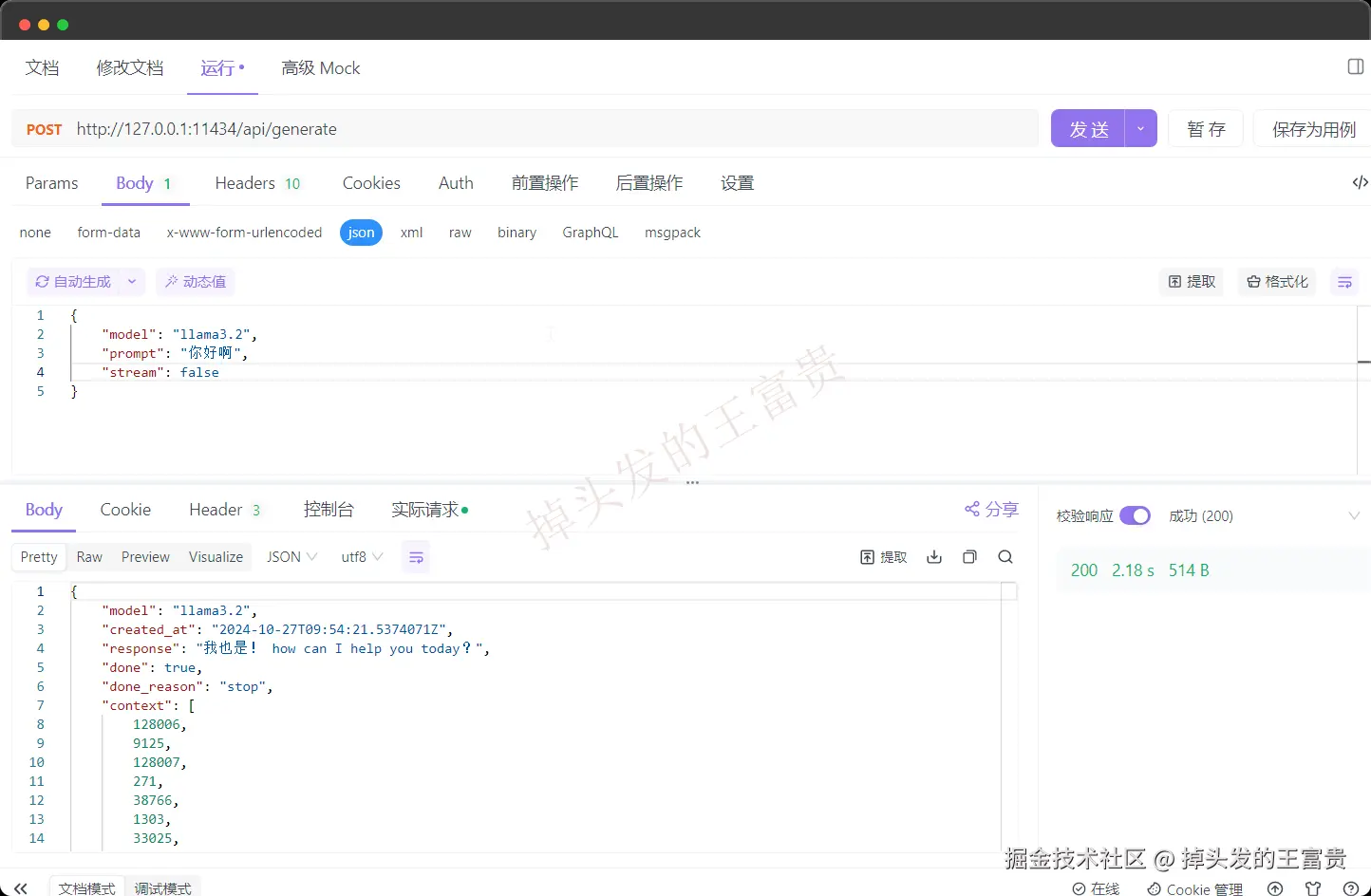
带上下文
大家要知道的是之所以gpt能够理解我们之前说过的话,核心之一的就是 上下文
curl http://localhost:11434/api/chat -d '{"model": "llama3.2","messages": [{ "role": "user", "content": "why is the sky blue?" }]}'
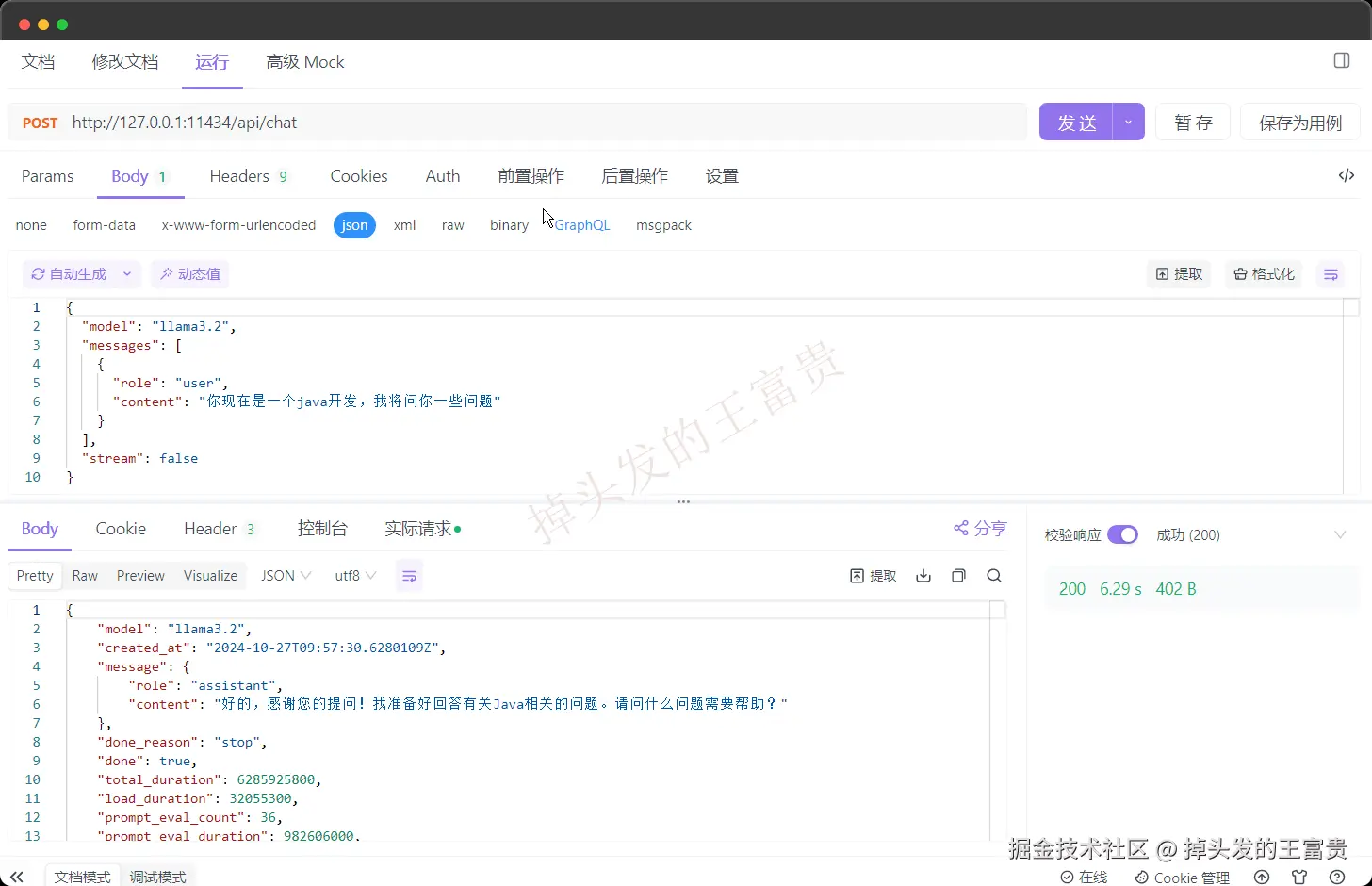
那么我们在问了之后,我们在编码的过程中可以把他回答的内容代入到上下文中一起发给他
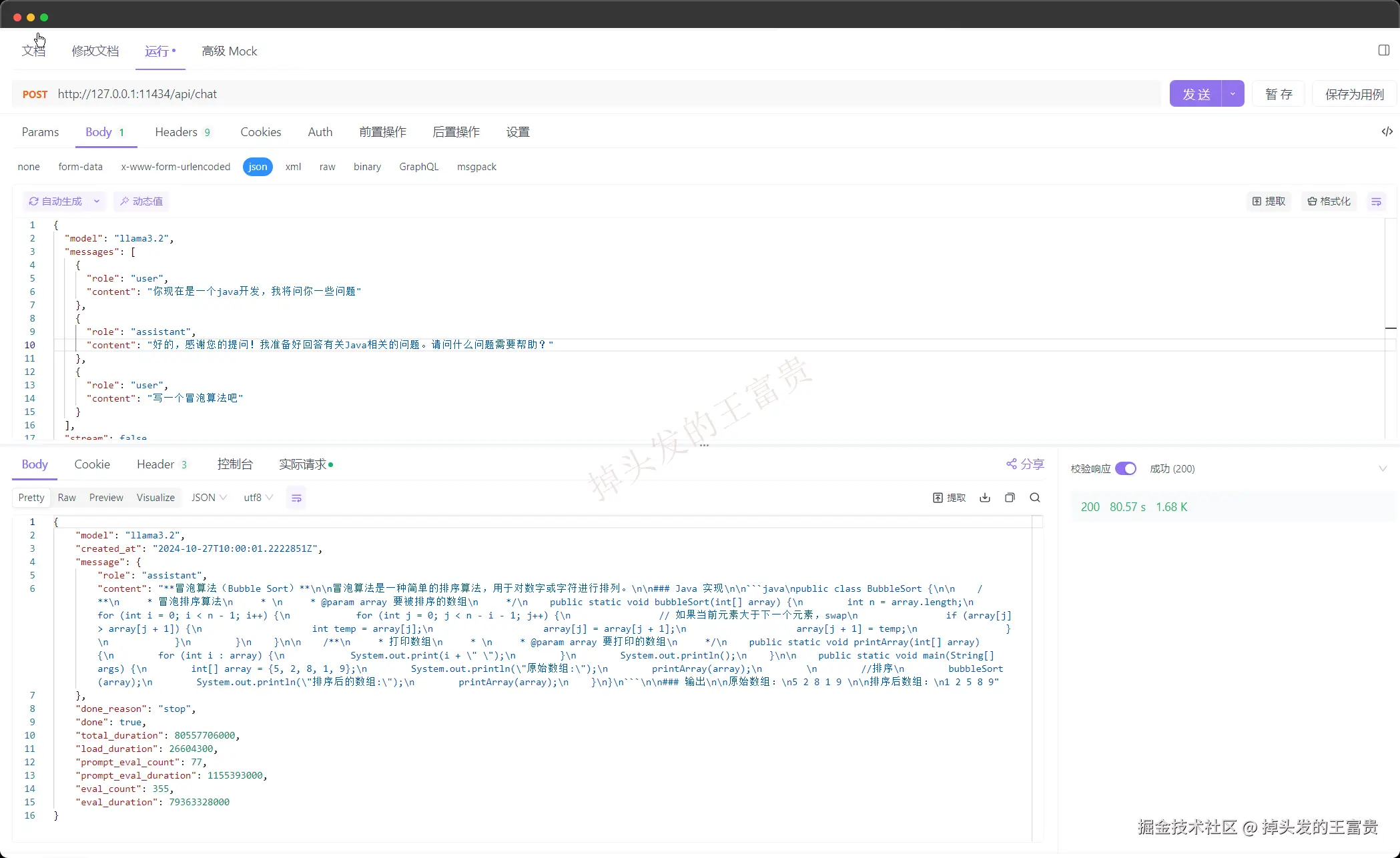
这样,他就有我们的上下文了,这里只是我们的http的工具调用,但是实际开发过程中代入上下文一定是我们程序调用的,那么在下一篇文章中,作者就带大家实际开发!!使用SpringBoot集成Ollama,感兴趣的可以点点关注哦!!
那么今天的Ollama入门就到这里了,更多模型的玩法欢迎关注这篇专栏和博主,如果对Ollama具体的参数更感兴趣的话可以参考官方的文档,这里我们就不再详细说明了,官网地址:

————————————————
版权声明:本文为稀土掘金博主「掉头发的王富贵」的原创文章
原文链接:https://juejin.cn/post/7433426879448629274
如有侵权,请联系千帆社区进行删除
评论