解密prompt系列43. LLM Self Critics
大模型开发/技术交流
- LLM
1天前21看过
前一章我们介绍了基于模型自我合成数据迭代,来提升LLM生成更合理的自我推理思考链路。但在模型持续提升的道路上,只提升Generator能力是不够的,需要同步提升Supervisor、Verifier的能力,才能提供有效的监督优化信号。
人类提供的监督信号有几类,包括人工直接生成最优回答(Demonstration), 人工提供偏好对比(Preference),人工给出优化建议(Critique)等几种,论文中曾提及以上几类信号的难易程度
The Evaluation of AI output is typically faster and easier for humans than the demonstration of ideal output
所以RLHF阶段的引入,除了降低模型模仿,提升泛化,增加更高水平的对齐,其实也有一部分原因是人类生成golden answer的上限是比较低的,毕竟不能雇佣一堆各领域专家来给你生成最优回答,所以训练也就从人类标注转移到了人类评估。
而现在当大模型能力提升到一定水平后,不仅是Demonstration,连Prefernce和Critique也会遇到瓶颈。当前阻碍模型智能进一步提升的一个核心问题就是评估水平的上限,而这时就需要模型评估的辅助,尤其是生成式评估能力的加持,下面我们看两篇OpenAI在生成式评估上的论文。
22年:Self-critiquing models for assisting human evaluators
比较早的这篇论文我们主要看下结论,毕竟模型更大更强了,训练范式也在这两年发生了转变。论文的核心就是机器辅助人类进行标注。可能早在22年之前,OpenAI就已经到了大模型在复杂问题上输出结果接近人类标注员的水平,所以才早早开始研究这个方向。
这里标注的任务已经脱离了早期descriminative的NLP任务,例如多项选择,分类等判断模型,而是已经聚焦在了对生成式模型的输出进行广泛评估。并且机器辅助也并非简单的对/错的分类判别,而是分类判别(critiqueable)、生成式评估(critique)、基于评估的条件优化(refinement)的结合体,如下

论文评估用模型辅助人类标注,得到了以下结论
-
生成式评估可以帮助标注员发现更多模型回答问题(人机协同,相比各自单打独斗能发现更多模型回答的问题)
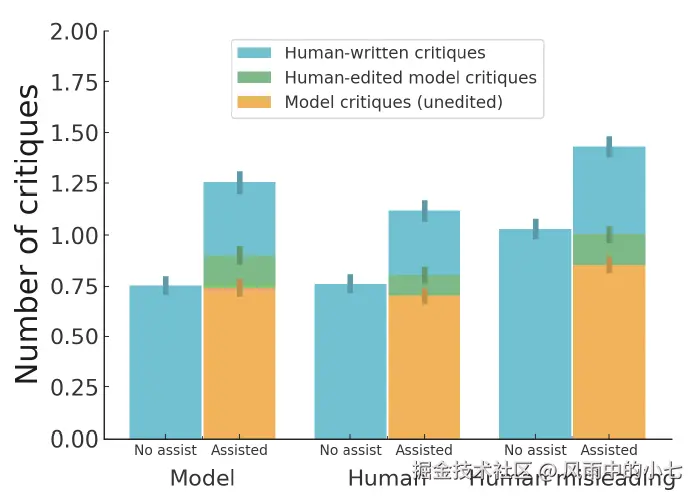
-
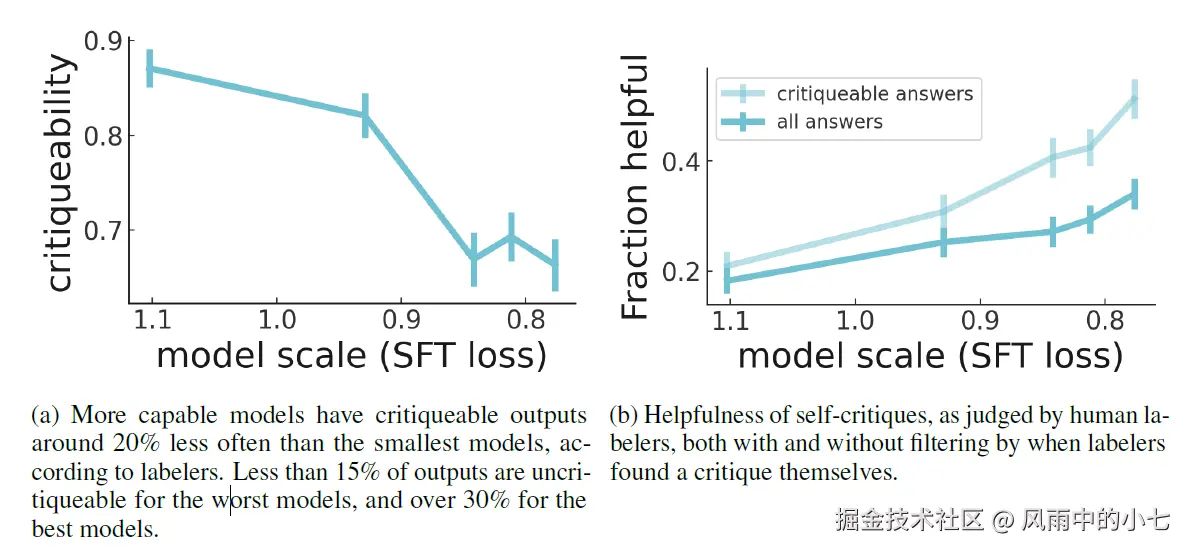
随着模型规模提升,模型的回答会更难被发现问题(critiqueability),但同时模型自我评估的能力也会随之提升(fraction helpful)
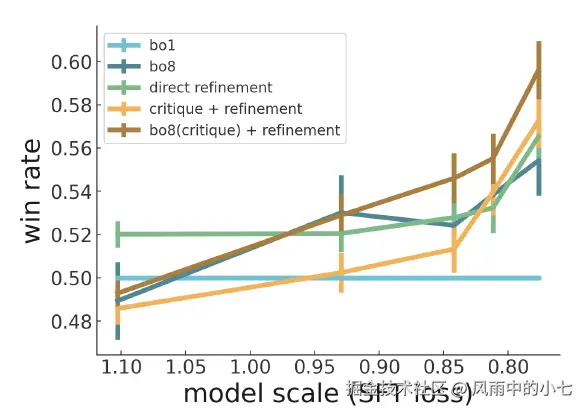
足够大的模型可以通过自己评估自己的回答,来优化答案生成,通过拒绝采样得到更准确的critique,可以进一步提升效果
24年: LLM Critics Help Catch LLM Bugs
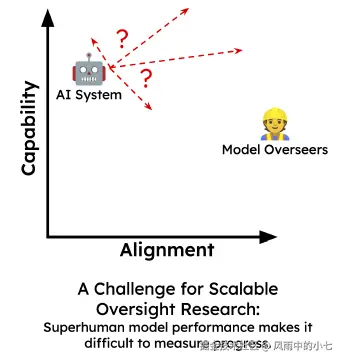
如果说22年初的论文还只是针对在部分人类难以评估的领域,例如生成式摘要上,使用人机协同评估带来的增益。24年的这篇论文就更广泛地讨论Scalable Oversight问题。这是Anthropic也在22年提出的概念,就是当模型能力在多数任务上超越人类时,人类该如何继续为模型提供有效的对齐信号,如下图
论文给出方案就是训练CriticGPT,使用模型生成式评估来辅助人类标注员。并同时给出了在推理时可以平衡问题发现的准召比例的推理方案Force Sampling Beam Search。论文评估在CriticGPT模型的帮助下,人工标注的效果会有显著的提升。下面我们分别讲下训练和推理部分。

数据和训练
论文选择了Coding,这个任务复杂度上限很高,相对容易验证且客观的任务场景。训练的核心在于代码标注RLHF数据集的构建,包括偏好标注标准和数据集组成。什么样的模型标注是好标注?什么样的模型代码样本能让偏好标注的一致性更高,同时数据集足够全面?
先说数据标注标准,论文综合召回和准确给出了4条衡量模型标注优劣的标准
-
召回率:模型的标注评论是否发现了回答中的所有Bug
-
核心召回率(CBI):模型的标注评论是否发现了回答中的核心Bug
-
准确率:模型的标注评论是无中生有,或者鸡蛋里挑骨头
-
综合召回+准确:模型标注评论整体的有用性
人工标注员除了需要对每条模型评论针对以上标准进行打分外,还需要对4条模型标注的整体效果进行对比,最终是使用对比结果来作为RLHF的训练标签,考虑在标注时绝对打分的一致性要远远低于相对打分的一致性。
再说数据构成,整个RLHF的数据集包含两个部分
-
人工在模型回答中注入Bug,再让模型进行评论
-
模型回答自带Bug

人工数据部分就是论文的一个亮点,上图就是人工数据构建的过程,既人工在模型回答中加入Bug(Tampering),给出注入Bug的相关解释。之后模型需要在人工修改过的答案上进行标注评论,同时标注员也会依赖Bug说明,来衡量模型生成的多条标注的效果。
这类构造数据在RLHF数据集中占比更高,原因在于相比自带Bug的天然数据,这类加工数据,不仅Bug更加复杂,同时因为自带golden answer,所以在人工标注阶段能得到更一致,准确率更高的标注结果,在偏好数据的标注过程中,审核一致性是非常重要的。同时在收集数据过程中,论文还使用了多个版本,多个大小的模型,来丰富整个RLHF数据集的分布覆盖度。两类数据的占比分布如下
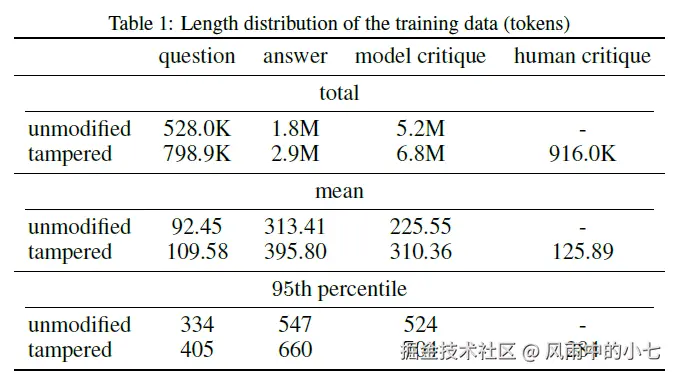
偏好数据收集完,后面就是比较常规的训练Reward模型,再基于reward模型,使用PPO训练CriticGPT。
推理和效果
推理时,论文采用了Reward模型和推理搜索结合的方式,目标是提高模型标注的长度,并降低回答幻觉。其实也很简单就是在单纯reward 打分的基础上,加了一个模型引用源代码段落数的得分。
模型标注的推理格式是引用一段源代码,再分析一下这段代码的问题,所以在打分中加入代码数可以鼓励模型推理对更多的源代码片段进行分析,从而发现更多的Bug,而reward打分则用于控制幻觉,这样既保质也保量。
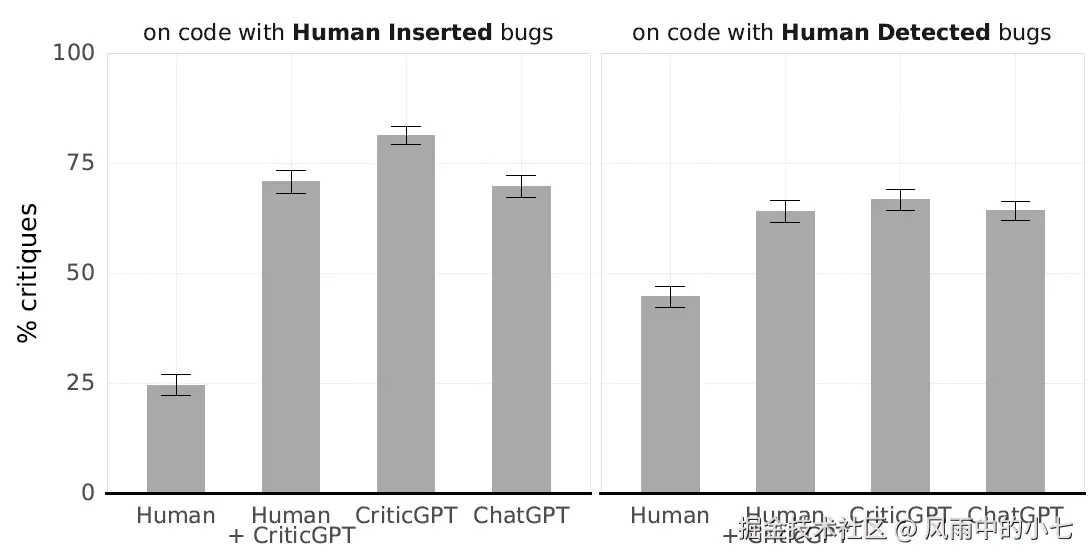
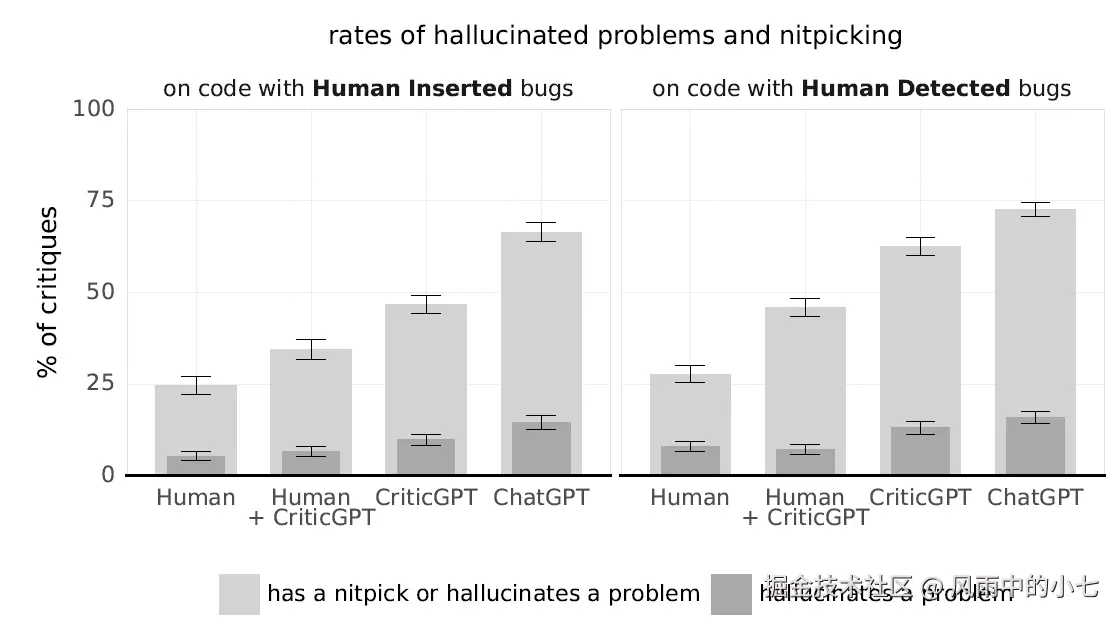
效果上,有模型标注协同,人工标注可以显著发现更多的bug,并且相比单纯使用criticGPT进行机器标注,会有显著更低的幻觉比例。整体上criticGPT配合人工标注是更加balance的模型标注方案。
————————————————
版权声明:本文为稀土掘金博主「风雨中的小七」的原创文章
原文链接:https://juejin.cn/post/7440842636229525556
如有侵权,请联系千帆社区进行删除
评论