PyTorch 介绍与实战:从数据加载到模型训练与测试
大模型开发/技术交流
- LLM
2天前34看过
随着深度学习的迅猛发展,PyTorch 已经成为最受欢迎的深度学习框架之一。其灵活性、易用性和强大的功能使其在研究和工业界获得了广泛的应用。本文将通过一个简单的机器学习流程,详细介绍如何使用 PyTorch 完成数据加载、模型构建、训练和测试等关键步骤,并分享一些在使用 PyTorch 时的实用技巧。
1. PyTorch 简介
PyTorch 是由 Facebook AI 研究团队(FAIR)开发的开源深度学习框架,因其动态计算图和 Pythonic 的 API 设计,广受开发者和研究人员的喜爱。PyTorch 主要特点包括:
-
动态计算图(Dynamic Computational Graph):在运行时即时生成计算图,便于调试和修改模型。
-
易用的 API:提供直观的接口,使得模型的构建和训练非常简便。
-
强大的社区支持:拥有丰富的文档、教程和工具,且社区活跃,常常推出新的功能和优化。
-
与 NumPy 紧密集成:PyTorch 的张量(tensor)和 NumPy 数组具有高度兼容性,使得开发者能轻松进行数据处理。
这些特点使得 PyTorch 在各种机器学习任务中都得到了广泛应用,从简单的神经网络到复杂的生成对抗网络(GAN)和强化学习,PyTorch 都能提供强大的支持。
在 PyTorch 中,构建模型的过程通常包括定义模型结构、训练模型以及评估模型性能几个阶段。接下来,我们将通过一个简单的神经网络示例,展示如何使用 PyTorch 来实现这些基本操作。
2. 数据加载
在机器学习任务中,数据预处理和加载是至关重要的一步。PyTorch 提供了
Dataset 和 DataLoader 类来简化这一过程,支持批量加载数据、并行处理以及数据增强等功能。
2.1 自定义数据集
你可以通过继承
Dataset 类来自定义数据加载类,重写 __len__ 和 __getitem__ 方法。以下是一个简单的示例:
import torchfrom torch.utils.data import Dataset, DataLoaderclass MyDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx], self.labels[idx]# 创建数据集实例data = torch.randn(100, 10) # 100 个样本,每个样本 10 个特征labels = torch.randint(0, 2, (100,)) # 100 个标签dataset = MyDataset(data, labels)# 使用 DataLoader 进行批处理dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
2.2 使用内置数据集
PyTorch 也提供了许多常用的标准数据集(如 MNIST、CIFAR-10 等),可以直接加载。以下是加载 MNIST 数据集的示例:
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])# 加载训练和测试数据集trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)testset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)trainloader = DataLoader(trainset, batch_size=64, shuffle=True)testloader = DataLoader(testset, batch_size=64, shuffle=False)
3. 构造模型
在 PyTorch 中,构建模型通常通过继承
torch.nn.Module 类来实现。模型包含若干层,每一层通常是通过 nn.Module 提供的功能构建的。
在PyTorch中,构建模型的基本框架通常遵循以下步骤:
-
导入必要的模块。
-
定义一个新的类,继承自
torch.nn.Module。 -
在类的构造函数
__init__中初始化模型的层。 -
定义一个前向传播函数
forward,该函数指定了如何通过模型的层来传递输入数据。
以下是一个简单的全连接神经网络模型,适用于 MNIST 图像分类任务:
import torch.nn as nnclass SimpleNN(nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(28 * 28, 128) # 第一层self.fc2 = nn.Linear(128, 64) # 第二层self.fc3 = nn.Linear(64, 10) # 输出层(10 类)def forward(self, x):x = x.view(-1, 28 * 28) # 将每个 28x28 的图像展平为一维向量x = torch.relu(self.fc1(x)) # 使用 ReLU 激活函数x = torch.relu(self.fc2(x))x = self.fc3(x)return x
4. 训练模型
训练是深度学习模型的关键步骤,包括前向传播、计算损失、反向传播和优化步骤。以下是使用 PyTorch 进行模型训练的完整流程:
4.1 定义损失函数和优化器
在训练前,你需要选择一个损失函数(如交叉熵损失)和优化器(如 Adam)。
import torch.optim as optim# 创建模型实例model = SimpleNN()# 定义损失函数和优化器criterion = nn.CrossEntropyLoss() # 适用于分类任务optimizer = optim.Adam(model.parameters(), lr=0.001)
交叉熵损失函数是衡量两个概率分布之间差异的一种方法,常用于分类问题中。它来源于信息论,用于衡量两个概率分布之间的差异。交叉熵损失函数的数学表达式为:
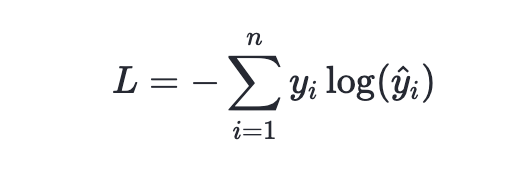
其中,n 是样本数量,y_i 和 y^i\hat{y}_iy^i 分别表示第 i 个样本的真实标签和模型预测输出。
Adam(Adaptive Moment Estimation)是一种自适应学习率的优化算法。它结合了动量(momentum)和自适应学习率的思想,通过对梯度的一阶矩估计和二阶矩估计进行指数加权移动平均来调整学习率。Adam在许多任务中表现优异,通常能够快速且有效地收敛到全局最小值。其关键特性如下:
-
动量(Momentum) :类似于物理中的动量概念,它帮助算法在优化过程中增加稳定性,并减少震荡。
-
自适应学习率:Adam为每个参数维护自己的学习率,这使得算法能够更加灵活地适应参数的更新需求。
-
偏差修正(Bias Correction) :由于算法使用了指数加权移动平均来计算梯度的一阶和二阶矩估计,因此在初始阶段会有偏差。Adam通过偏差修正来调整这一点,使得估计更加准确
4.2 训练循环
训练过程通常分为多个 epoch。每个 epoch 中会通过数据加载器获取批次数据,进行前向传播和反向传播,并更新模型参数。
一个epoch的逻辑为:
-
梯度清零:避免梯度积累,如果不清理梯度会一直累积,那么每次梯度下降的变化量就会比较大。
-
前向传播:通过前向传播得到模型预测值,并且通过预测值计算本次的损失值。
-
反向传播:通过反向传播可以计算本次梯度下降的变化量。
-
参数更新:通过参数更新即可更新模型参数,最终保存模型时一种简单的方法就是保存模型最后的参数。
num_epochs = 10 # 训练 10 个 epochfor epoch in range(num_epochs):model.train() # 设置模型为训练模式running_loss = 0.0for inputs, labels in trainloader:optimizer.zero_grad() # 清空上一步的梯度# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)# 反向传播loss.backward()# 更新参数optimizer.step()running_loss += loss.item()print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(trainloader):.4f}")
5. 测试模型
训练完成后,需要评估模型的性能。PyTorch 提供了
eval() 方法切换到评估模式,并且在测试阶段通常禁用梯度计算,以提高推理效率。
5.1 模型评估
在测试阶段,我们将计算模型在测试集上的准确率。我们使用以下公式来计算模型的准确率:
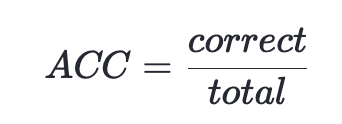
其中,
correct表示预测准确的样本数目,total表示总得样本数目。
model.eval() # 设置模型为评估模式correct = 0total = 0with torch.no_grad(): # 禁用梯度计算for inputs, labels in testloader:outputs = model(inputs)_, predicted = torch.max(outputs, 1) # 获取最大概率的类别total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = 100 * correct / totalprint(f"Test Accuracy: {accuracy:.2f}%")
6. 使用 PyTorch 时的注意事项
6.1 数据类型一致性
确保数据类型的一致性。例如,输入数据和标签的类型应与模型参数的数据类型相匹配,否则会出现错误。
inputs = inputs.float()labels = labels.long()
6.2 内存管理
在训练过程中,尤其是在使用 GPU 时,PyTorch 会自动计算梯度并缓存中间结果。为了避免内存泄漏,使用完每个批次后,应及时清空梯度缓存。
optimizer.zero_grad() # 每个批次后清空梯度
6.3 使用硬件加速
如果你的机器上有可用的 GPU,可以使用
cuda() 方法将模型和数据转移到 GPU 上,从而加速训练。但是需要注意将数据移动到同一设备上。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = model.to(device)inputs, labels = inputs.to(device), labels.to(device)
————————————————
版权声明:本文为稀土掘金博主「JoyRider」的原创文章
原文链接:https://juejin.cn/post/7438811022671151138
如有侵权,请联系千帆社区进行删除
评论
