
模型服务升级、全新训练方法上线!千帆ModelBuilder 带着更好用的功能来了
大模型开发/产品动态
- 文心大模型
- LLM
3月13日1927看过
-
模型服务上,此次更新围绕模型部署、调用统计、视频生成等内容展开,使用感受更加便捷简单
-
工具链上,全新RFT训练方法上线,大大节省数据及人力成本。
⬇️还有更多精彩,继续发现⬇️
登录百度智能云千帆ModelBuilder平台同步进行文字和功能的体验效果更佳。
模型服务升级
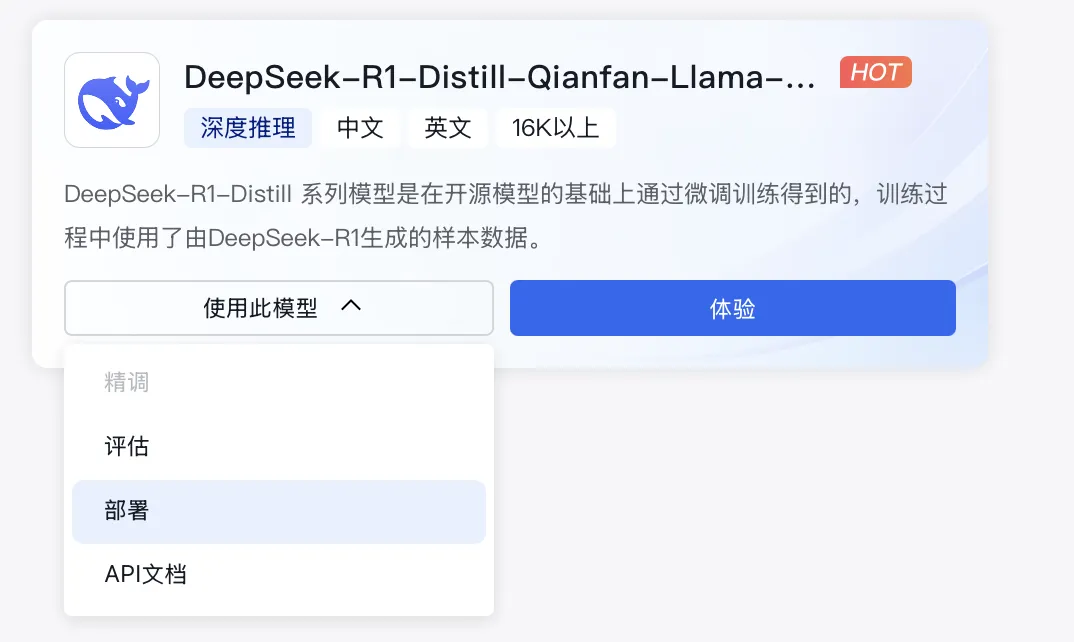
1、DeepSeek-R1-Distill-Qianfan-Llama-70B/8B模型支持一键部署。
2、调用统计详情页面支持查看触发Prompt Cache、 ChatFilePlus的调用量及tokens。
3、MiniMax视频生成系列服务上线,支持申请试用。审批通过后,可通过API的方式调用测试。
3、MiniMax视频生成系列服务上线,支持申请试用。审批通过后,可通过API的方式调用测试。
-
-
文生视频:T2V-01-Director、T2V-01
-
图生视频:S2V-01、I2V-01、I2V-01-live
-
4、新增『推理模型』类型的模型导入并部署,该类模型发布部署以后支持返回reasoning_content
5、自定义模型导入,Prompt拼接规范新增支持『自动拼接』方式,使用导入模型文件当中的tokenizer_config.json进行自动拼接,降低模型导入配置复杂度。
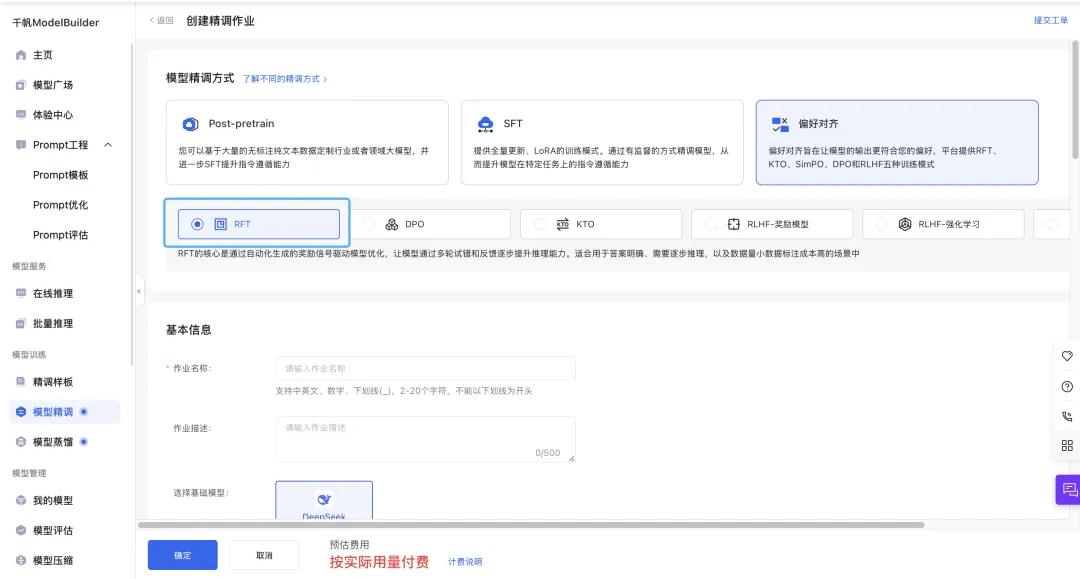
1、新增RFT(Reinforcement Fine-Tuning)训练方法,国内首个上线平台!
新增基于DeepSeek-R1-Distill-Qwen-14B模型进行RFT训练。RFT的核心是通过自动化生成的奖励信号驱动模型优化,让模型通过多轮试错和反馈逐步提升推理能力,适合用于答案明确、需要逐步推理,以及数据量小、偏好数据标注成本高的场景。
2、SFT、DPO新增Qianfan-Sug对话预测模型,该模型能够基于对话上下文精准识别用户意图,并智能推测用户接下来的可能提问,适用于智能客服、电商等场景。
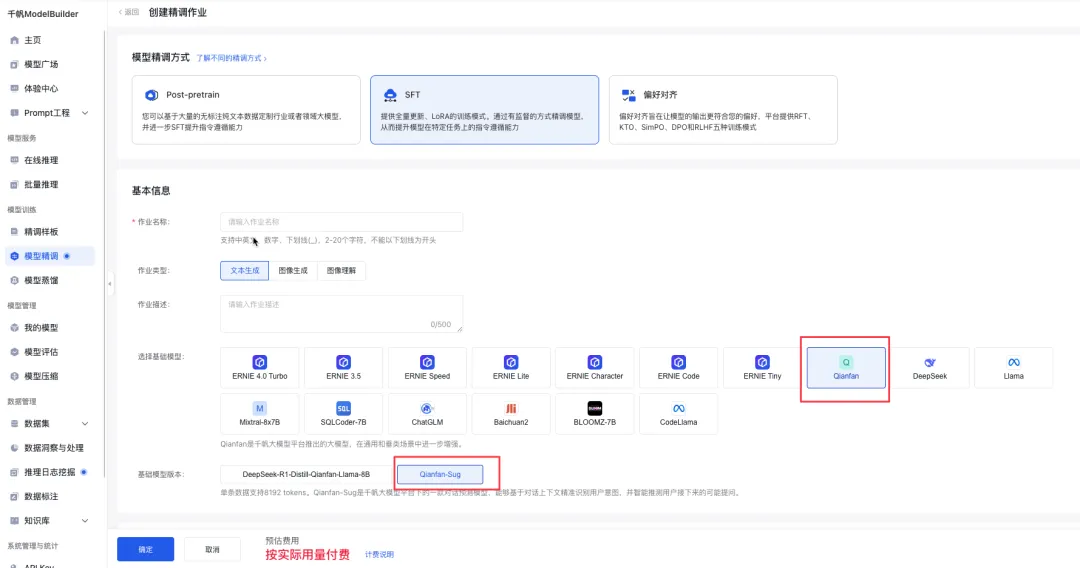
3、SFT新增DeepSeek-R1-Distill-Qianfan-Llama-8B模型,该模型由千帆大模型研发团队基于Llama3-8B模型蒸馏DeepSeek-R1得到,其中蒸馏数据中同步添加了千帆的语料。该模型在math-en、scq5k-en等多个评测集中远远优于同参数量规模模型。
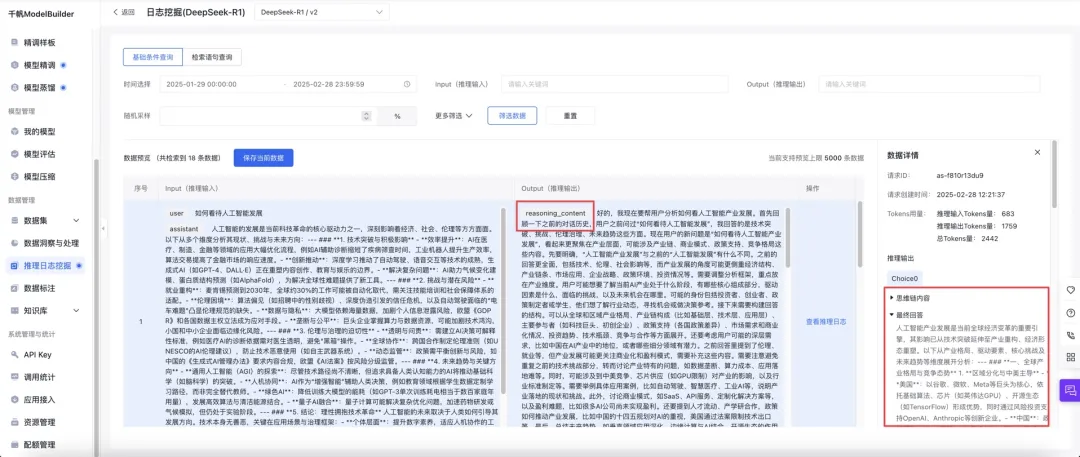
4、推理日志挖掘支持 DeepSeek 服务的思维链字段(Reasoning_Content)回流至平台数据集,从而更便捷地准备带思维链的精调数据,并有效用在深度推理场景的模型蒸馏。
4、推理日志挖掘支持 DeepSeek 服务的思维链字段(Reasoning_Content)回流至平台数据集,从而更便捷地准备带思维链的精调数据,并有效用在深度推理场景的模型蒸馏。
预置服务DeepSeek-R1-Distill-Qwen-14B、DeepSeek-R1-Distill-Qwen-32B支持TPM付费(仅支持预付费),购买TPM配额前,需提前与您的专属客户经理咨询。
评论
