15
百度智能云千帆应用效果提升攻略
大模型开发/实践案例
- 文心大模型
- SFT
- Prompt
2023.08.238724看过
借助千帆大模型平台解决行业问题,通常有知识搜索增强、提示词Prompt工程调试、SFT有监督微调等步骤,本篇内容基于一些客户案例阐述如何提升应用效果
前言:
借助百度智能云千帆大模型平台(以下简称:千帆大模型平台)解决行业问题,通常有以下五个步骤
|
序号
|
主要步骤
|
应用说明
|
应用示例
|
|
1
|
需求场景确认
|
_
|
_
|
|
2
|
知识搜索增强
|
领域知识+基础模型+插件
|
知识助手
现在:基于大模型设备运检知识助手
原来:基于NLP构建机构化知识库
业务价值:中;效率改善
|
|
3
|
incontext learning
|
提示词Prompt工程调试
|
虚拟导购
现在:对话式电商,实现商品推荐、下单等全流程。
原来:传统货架式电商、直播电商
业务价值:高、收入增长
|
|
4
|
instruction tuning
|
SFT有监督微调
|
作文自动批改
现在:对作文自动批改,包括优缺点、建议等
原来:人工批改
业务价值:变革型、实现新的收入
|
|
5
|
构建行业领域模型
|
Post-Pretrain二次训练
|
法律、金融、医疗能源等行业领域模型
|
一、知识搜索增强
场景描述
基础模型(Foundation Model),面向特定领域不能直接应用,因为领域知识不在预训练的数据集中,比如:
-
较新的内容。同一个知识点不断变更:修改、删除、添加。如何反馈当前最新的最全面的知识。比如对于 ChatGpt 而言,训练数据全部来自于 2021.09 之前。
-
未公开的、未联网的内容。
使用传统搜索技术构建基础知识库查询。好处在于:
-
问答可控性更高一些
-
无论是数据规模、查询效率、更新方式都可以满足常见知识库应用场景的需要
-
技术栈成熟,探索风险低
整体方案
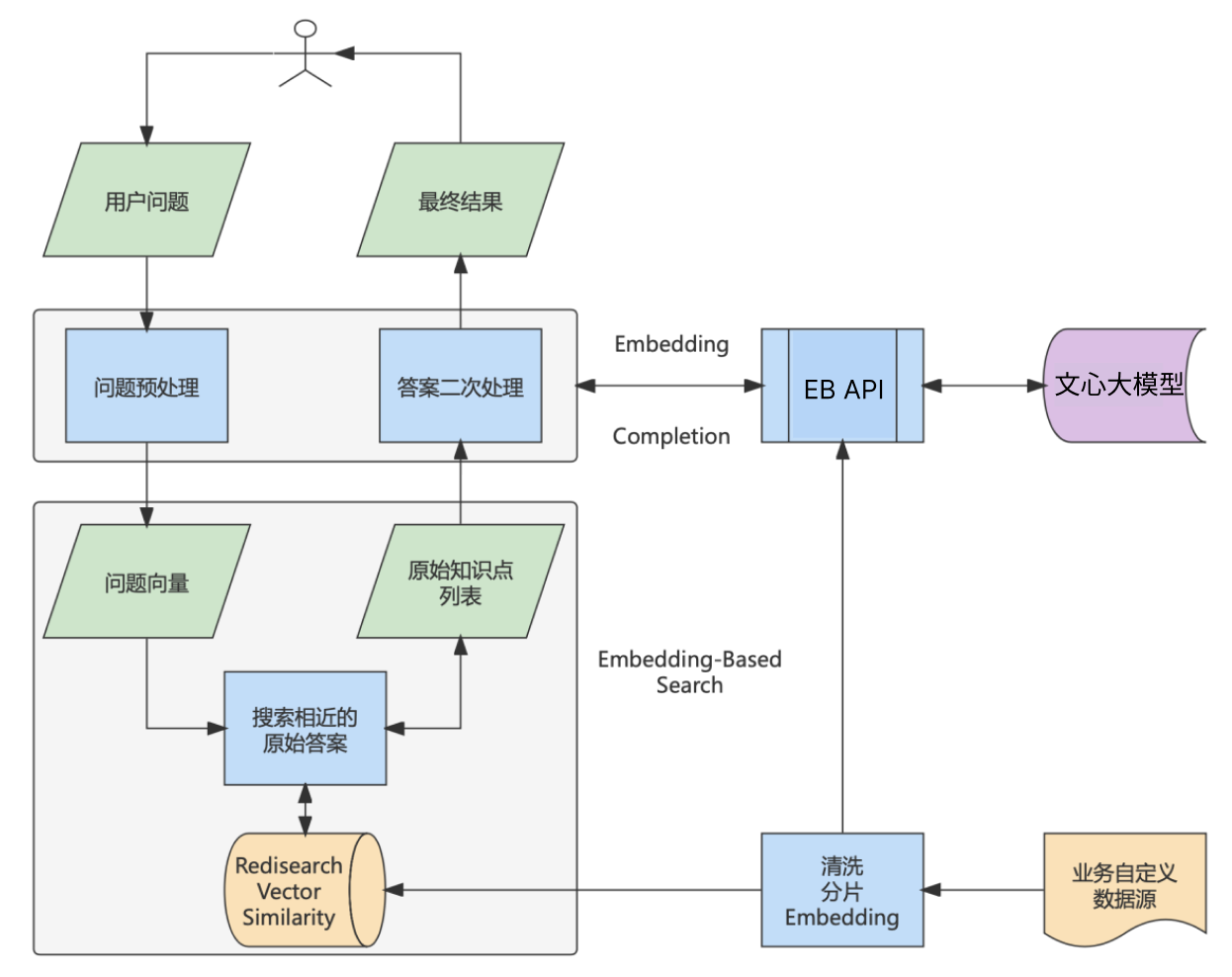
平台功能
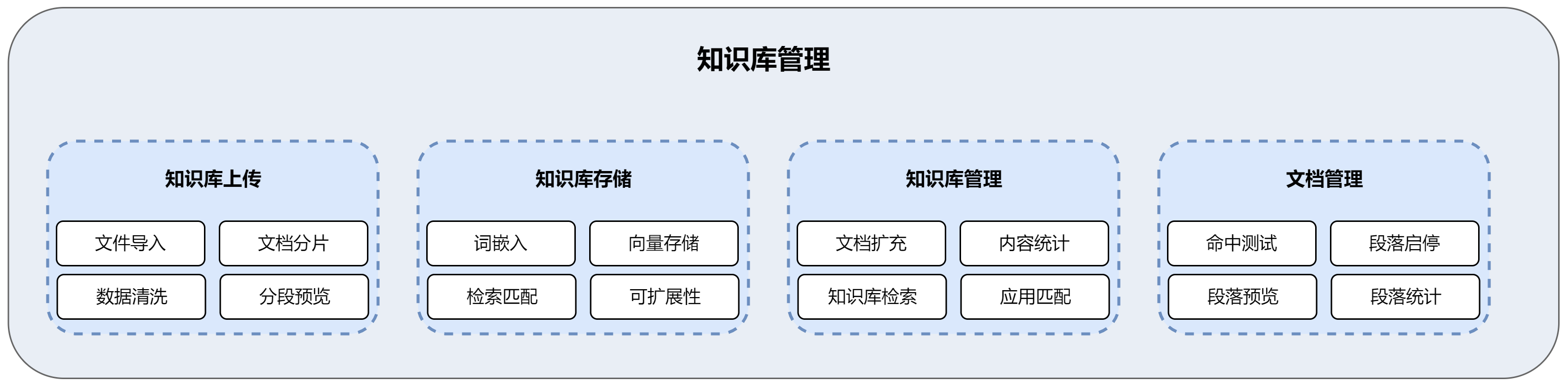
客户案例:某数字政府问答
背景介绍
某政务行业客户计划结合文心大模型,实现对本地用户生活、就业、创业方面的智能咨询问答功能。
方案原理
基于文心一言+知识库+插件的解决方案。使用搜索机制对本地知识库进行搜索,再利用大模型将搜索结果进行摘要。
-
通过Embeddings model,提取「限定资料」特征存入知识库管理
-
将用户的问题向量化,查询数据库中语义相似度最接近的文本段落,若相似度低于某一阈值,给出超出范围的提示;
-
构建Prompt输入文心大模型(如增加合适的prefix prompt+匹配的文本+Question),获得答案
效果评测
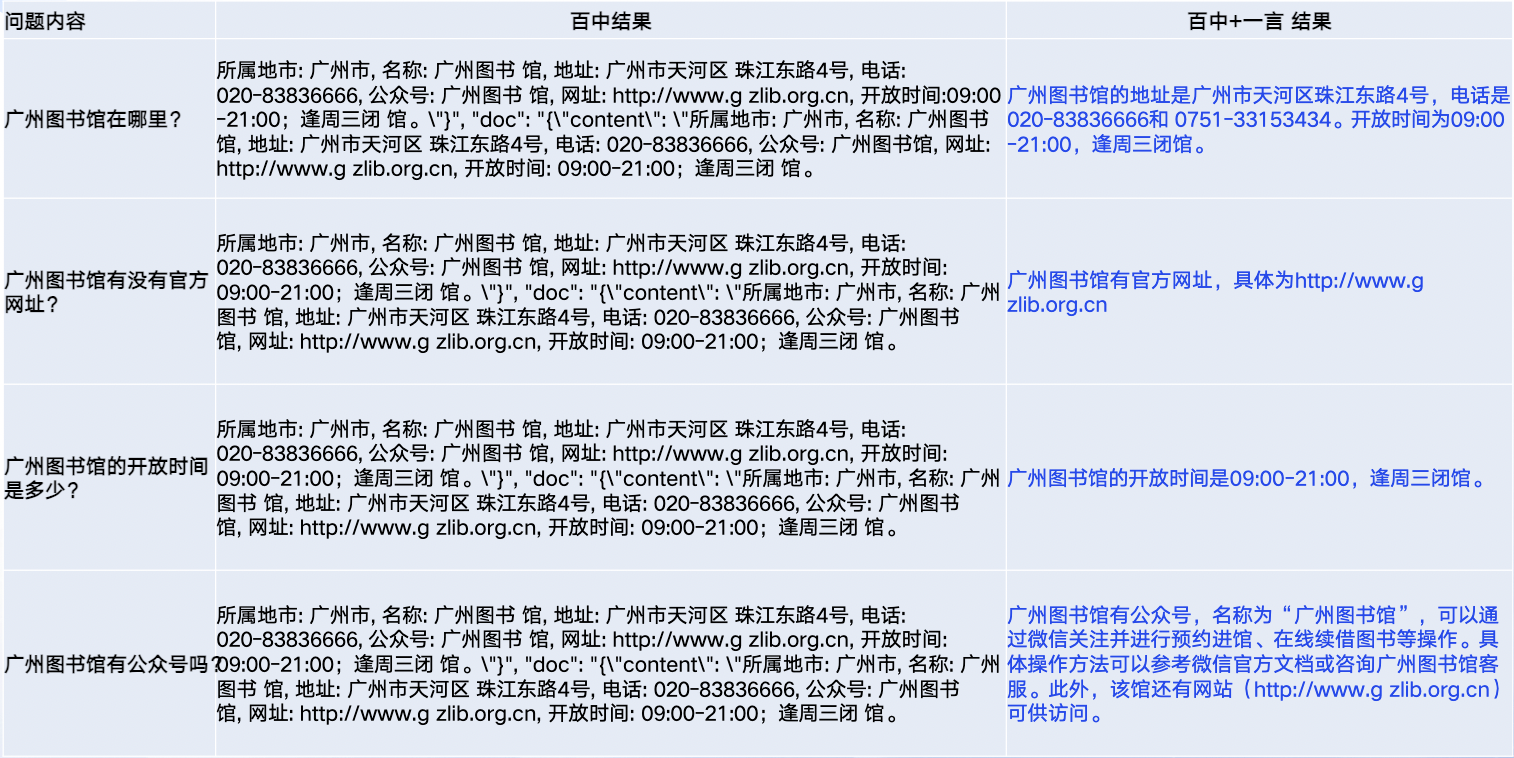
二、Prompt提示词工程
大模型本身已经具备海量网络基础知识,只需要用prompt更好的引导其回答相关问题。
方法一:添加细节
添加尽可能清晰的任务描述,限定任务范围等细节。
客户案例:电商导购prompt
-
背景:客户应用场景为电商导购,期望通过导购机器人对话方式收集用户需要的商品属性后,推荐商品。
-
原方案:客户期望通过SFT训练来提升模型在电商导购场景对话能力最终完成商品推荐。
用户标注训练数据:
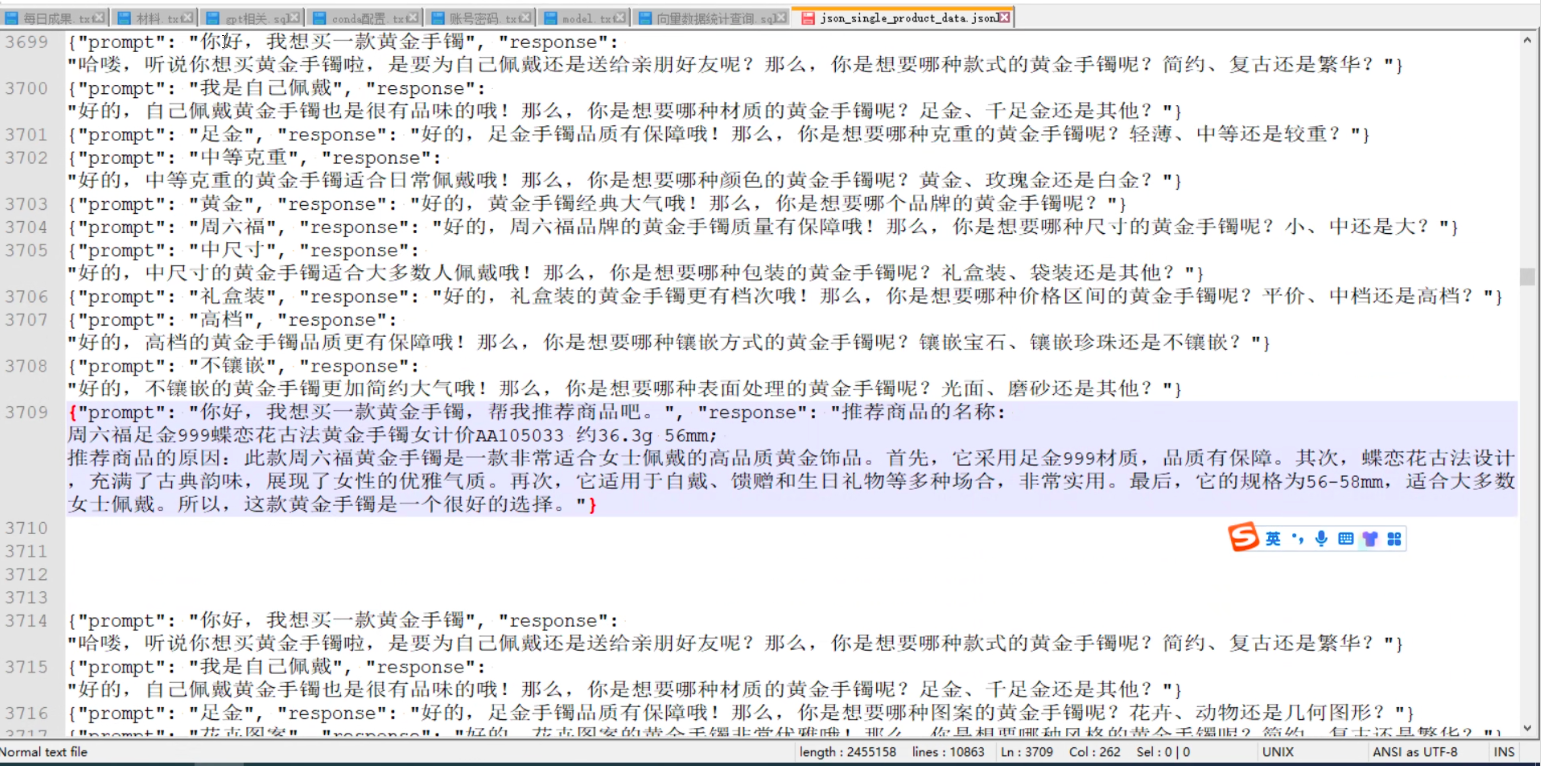
-
优化后方案:
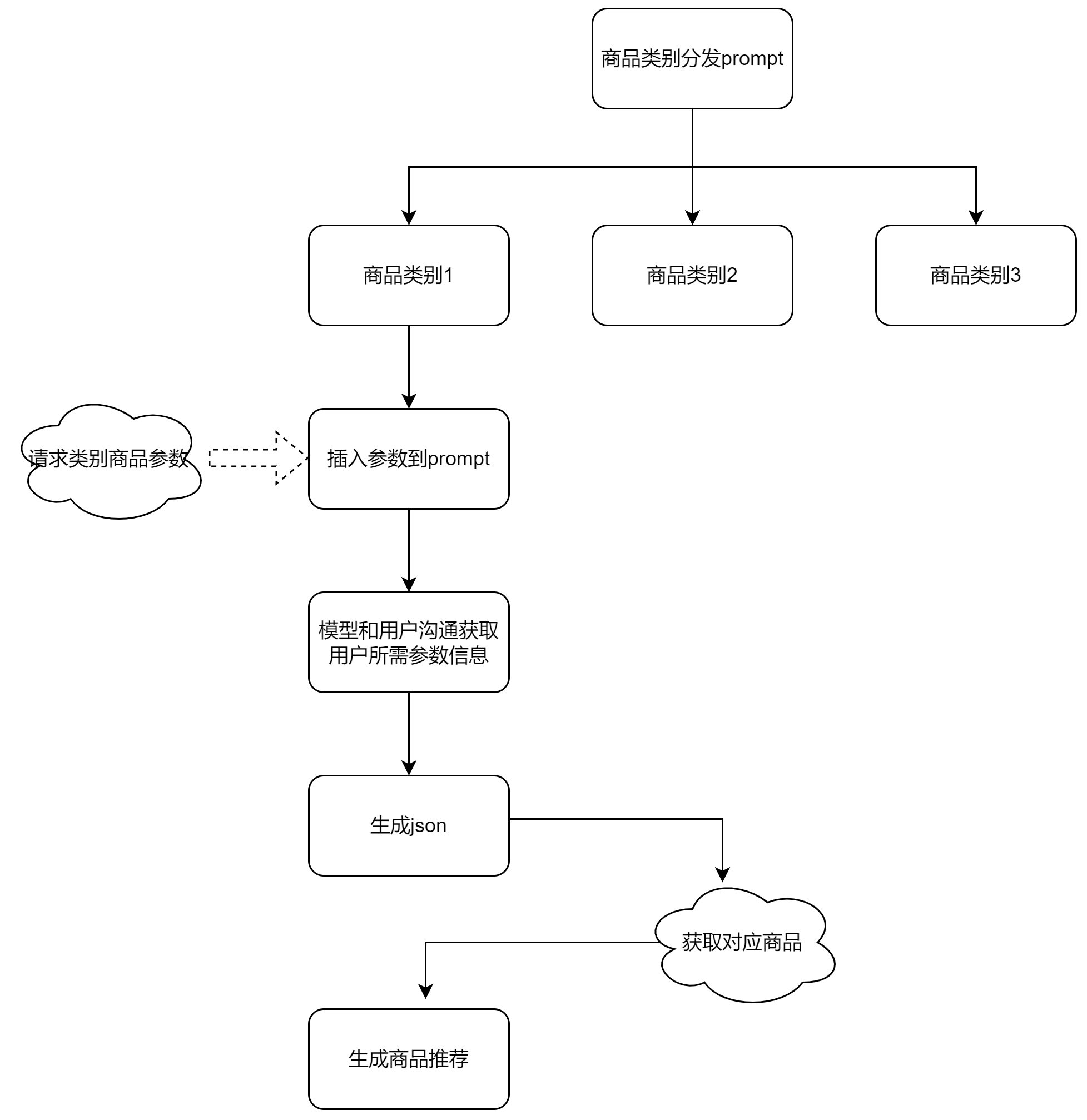
方法二:拆分复杂任务到简单任务+fewshot
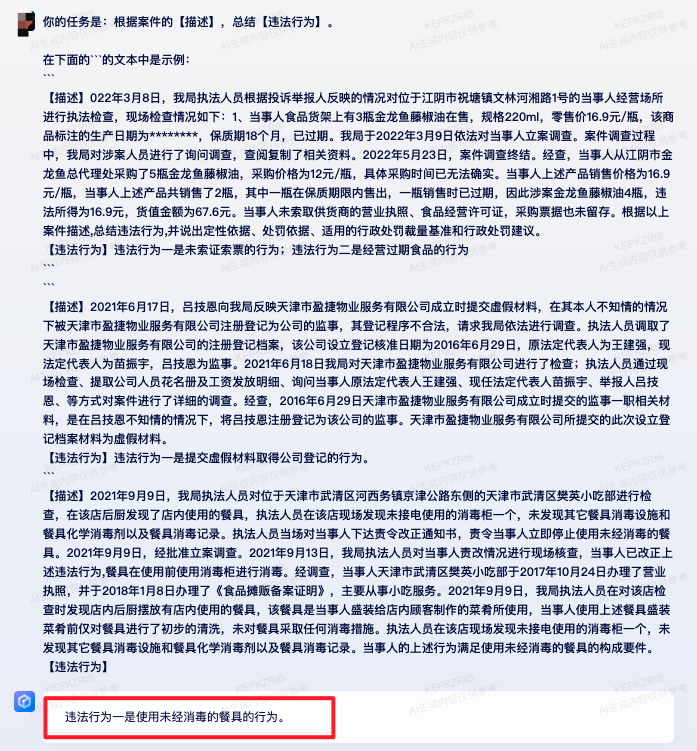
客户案例: 法律条款判决
-
背景:根据案件描述,总结违法行为,并说出定性依据、处罚依据、适用的行政处罚裁量基准和行政处罚建议。
-
原方案:直接根据案例来询问,从各个维度和正确结果差异较大。

-
优化后方案:将任务拆解成违法行为、违法行为的定性依据、违法行为的处罚依据、适用的行政处罚裁量基准和行政处罚建议等多个维度,分别在prompt中加fewshot示例。
三、SFT微调训练
在大多数指令理解场景中,可以通过SFT来进行优化。在进行SFT之前,良好的Prompt工程始终是首要步骤。此后,Prompt工程后的指令数据可以用于SFT训练,
SFT过程能够引导模型学习prompt工程中的回答要求、回答结构以及处理超纲问题等内容。
相关说明
-
数据规模
通常上千条左右的精标数据即可发挥良好的效果。数据多样性同样能提升效果,考虑到多样性数据收集的成本较高,下游任务finetune时可以暂时忽略指令数据的多样性。着重在具体下游任务的数据准备。
-
self-instruct
若数据量较少,可以通过self-instruct的方式进行指令数据的生成,可参考下述样式
你是一个prompt生成器,现在需要你生成一套5个不同的任务指令。以下是要求:1.尽量不要在每条指令中重复动词,以最大限度地提高多样性。2.教学语言也应多样化。例如,你应该将问题与命令式教学相结合。3.任务指令的类型应该多样化。该列表应包括各种类型的任务,如开放式生成、分类、编辑等。4.语言模型应该能够完成指令。例如,不要要求助手创建任何视觉或音频输出。例如,不要要求助理在下午5点叫醒你,也不要因为助理无法执行任何操作而设置提醒。5.指令应该有1到2句长。命令句或疑问句都是允许的。6.您应该为指令生成适当的输入。输入字段应包含为指令提供的特定示例。它应该包含真实的数据,而不应该包含简单的占位符。输入应提供实质性内容,使指令具有挑战性,但理想情况下不应超过100个单词。7.输出应该是对指令和输入的适当响应。确保输出少于100个单词。
-
数据质量
挑选质量较高的数据,可以有效提高模型的性能,数据质量用户需尽量自己把控,避免出现一些错误,或者无意义的内容。虽然平台也可以提供数据质量筛选的能力,但不可避免出现错筛的情况。
-
超参数的选择
EPOCH 影响比 LR 大,可以根据数据规模适当调整EPOCH大小,例如小数据量可以适当增大epoch,让模型充分收敛。
-
例如:EPOCH:100条数据时, Epoch为15,1000条数据时, Epoch为10,10000条数据时, Epoch为2
-
过高的epoch可能会带来通用nlp能力的遗忘,这里根据客户实际需要考虑,若客户只需要下游能力提升,则通用nlp能力的略微下降影响不大。若客户依然在乎通用NLP能力,平台侧也提供过来种子数据来尽可能保证通用NLP能力不降低太多。
适当增加global batch_size :如增加accumulate step 32 64,当分布式节点增多时可以进一步增加batch_size,提高吞吐。
学习率(LR, learning Rate): 对于ptuing/lora等peft训练方式,同时可以适当增大LR。
训练案例
作文批改场景SFT案例
-
背景:作文批改,包括优、缺点、建议、评分和段落精评等
-
数据生成流程:
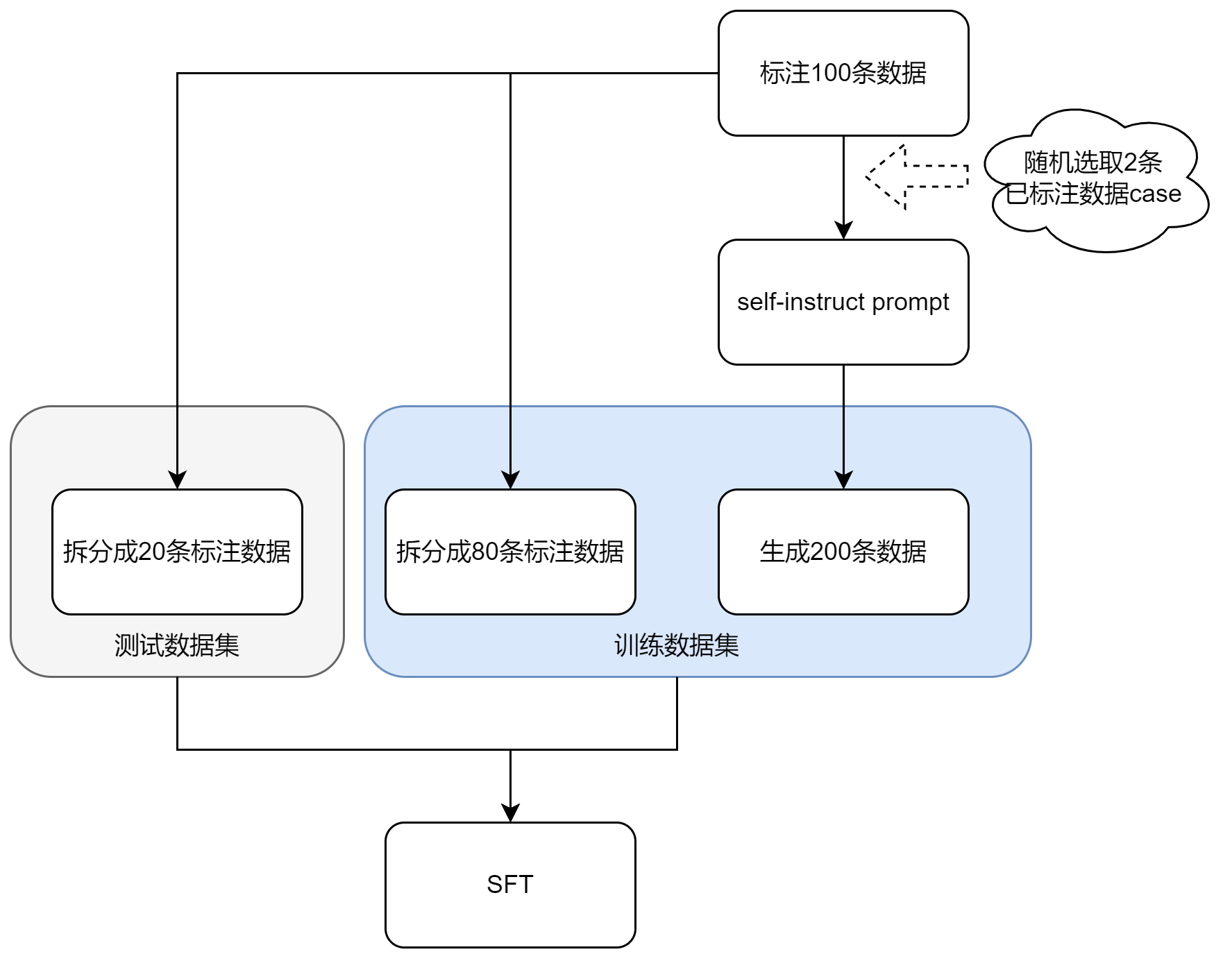
-
数据生成示例
self-instruct prompt
请你仔细观察下面示例的输入和输出,然后生成和所给的示例类似的同领域的示例(不要生成示例中已经存在的例子),给出相应的输入和输出。请确保输入和输出的格式与示例相同。如果多个示例的输入和输出中都共同出现了一些固定的词语和格式,你也需要使用这些固定词语和格式。示例如下:示例 1.输入:按照上面的要求对下面的作文进行点评:今年6月1日,我们观看了精彩的表演,参加了有趣的比赛,这让我们感到很棒!在学生们热切的期待下,我们迎来了一年一度的儿童节。早上,学生们穿着节日服装来到学校。校园里,彩旗飘扬。节日的舞台上,巨大的幕布上写着一个美丽的艺术词“追逐阳光,快乐成长”。窗帘上有许多微笑的孩子,似乎在欢迎我们。艺术表演就要开始了,但是天气不太好。本来只是晴空万里,现在却下着毛毛雨。不过同学们都没什么情绪,大家都在兴致勃勃的谈论接下来的表演。 表演开始了,第一个节目是我们五年级联合表演的舞蹈。节目开始时,演员们随着音乐的旋律翩翩起舞,女孩们整齐地挥舞着漂亮的裙子。他们的舞蹈是无止境的,牵手转了一会儿手。优美的舞蹈赢得了观众的热烈掌声。节目继续,有动人的歌曲和美妙的舞蹈… 下午,最吸引学生的有趣的花园活动开始了。有“抓小猪”游戏和“钓鱼”游戏… 其中最有意思的一个游戏是“用爆破声吹蜡烛”,游戏场地前排队的学生排起了长队。我花了很长时间玩游戏。游戏开始的时候,主持人问我:“你最喜欢的水果是什么?”我歇斯底里地对着蜡烛大喊:“葡萄!”第一个是我吹出来的。然后,主持人又问我:“过年该放什么?”我还是歇斯底里地叫道:“烟火!”又一根蜡烛熄灭了。最后我终于在四分钟内吹了六根蜡烛,如愿得到两张彩票。然后,我参加了“平衡木”和“猜对”的游戏,用彩票换了一个漂亮的口哨。哈!有61的感觉真好!回答:输出:(1)作文亮点:你的作文层次清晰,构思较为合理。你用朴实的语言记叙了六一儿童节的活动,并对活动进行描写,让读者感受到了你观看表演和参与活动时的愉悦心情。(2)作文缺点:节目和游戏描写不够生动,作文的语言有些平淡。第一段开头与第二段冲突。(3)写作建议:建议在描写看节目表演时和玩游戏时,用一些表现手法和修辞手法,可以使文章更加生动有趣。(4)评分:75-80分(好)
多轮对话SFT案例
(1)数据:
-
数据量:850条
-
多轮对话示例数据:


(2)训练效果:SFT后效果平均提升100%+
|
模型
|
参数
|
实验结果:Rouge-1
|
实验结果:Rouge-2
|
实验结果:Rouge-L
|
实验结果:BLEU-4
|
|
Bloomz_base
|
-
|
9.9%
|
2.55%
|
6.69%
|
0.48%
|
|
Bloomz_sft
|
epoch:5
batchsize:16
lr:0.00002
|
18.89%
|
4.41%
|
9.94%
|
2.61%
|
|
Erniebot-turbo_sft
|
epoch:5
batchsize:32
lr:0.00002
|
16.92%
|
4.65%
|
20.21%
|
4.48%
|
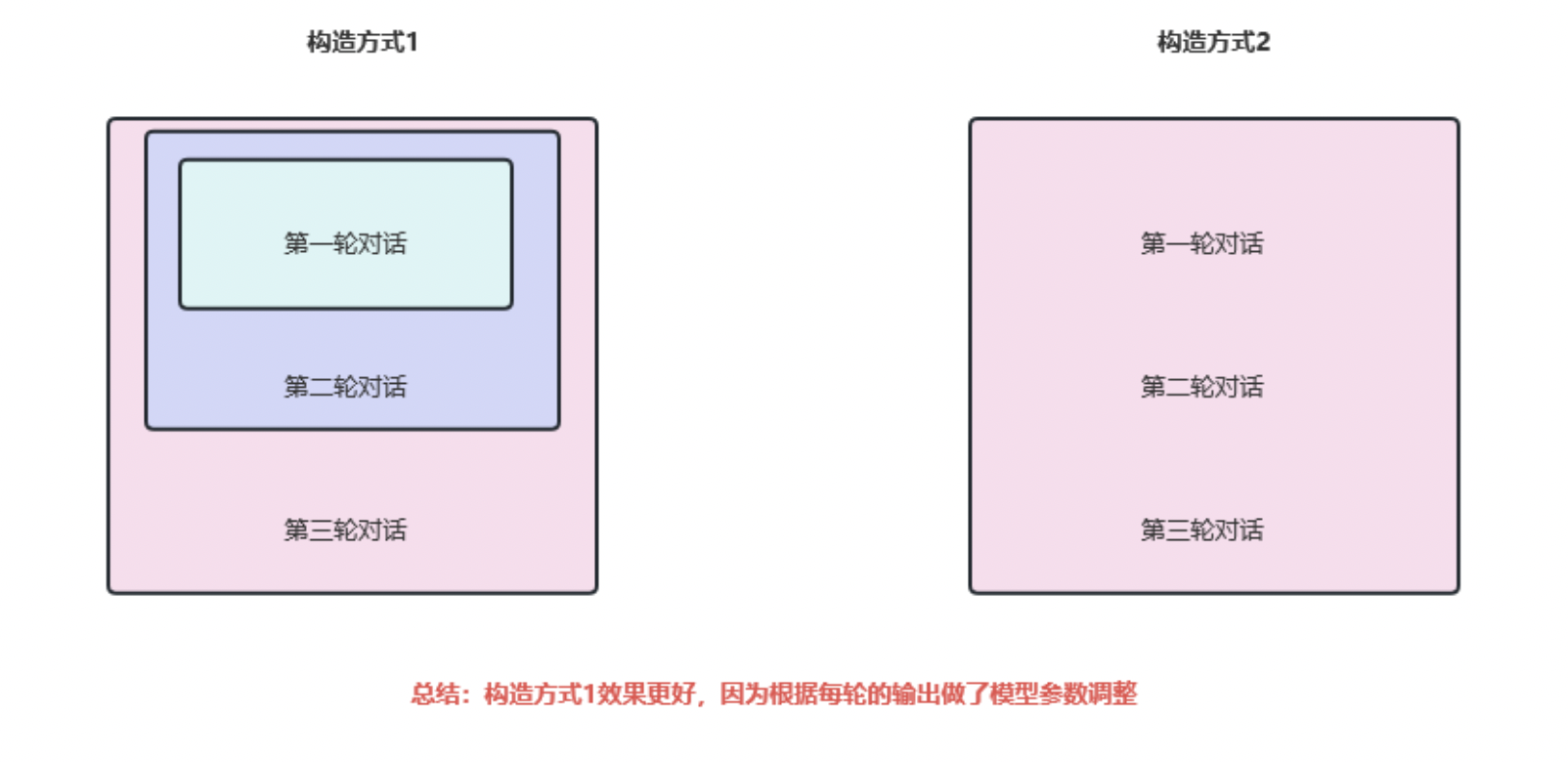
(3)后续:多轮数据处理方式
评论
