提示学习(Prompt-learning)
大模型开发/技术交流
- Prompt
2023.10.259364看过
前言
NLP四大范式
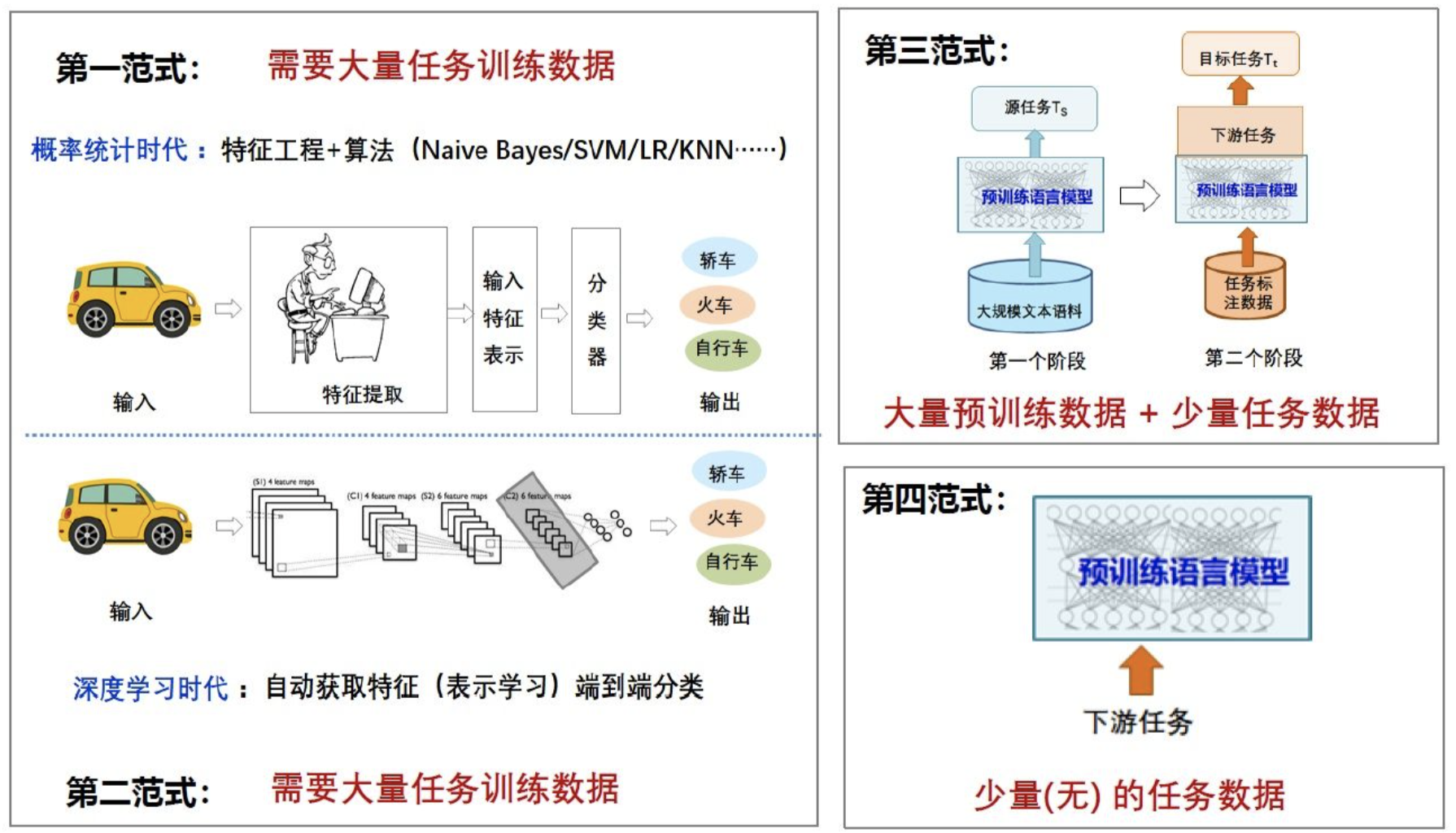
第一范式:非神经网络时代的完全监督学习(特征工程)
该阶段需要大量任务相关的训练数据,通过特征工程和算法,比较有代表的算法是朴素贝叶斯Naïve Bayes、支持向量机SVM、逻辑回归LR等;
第二范式:基于神经网络的完全监督学习(架构工程)
该阶段也需要大量任务相关的训练数据,通过深度学习方法,自动获取特征(表示学习)进行端到端分类学习;
第三范式:预训练,精调范式(目标工程)
第三范式指的是先在大的无监督数据集上进行预训练,学习到一些通用的语法和语义特征,然后利用预训练好的模型在下游任务的特定数据集上进行fine-tuning,使模型更适应下游任务。GPT、Bert等模型都属于第三范式,其特点是不需要大量的有监督下游任务数据,模型主要在大型无监督数据上训练,只需要少量下游任务数据来微调少量网络层即可。
第四范式:预训练,提示,预测范式(Prompt工程)
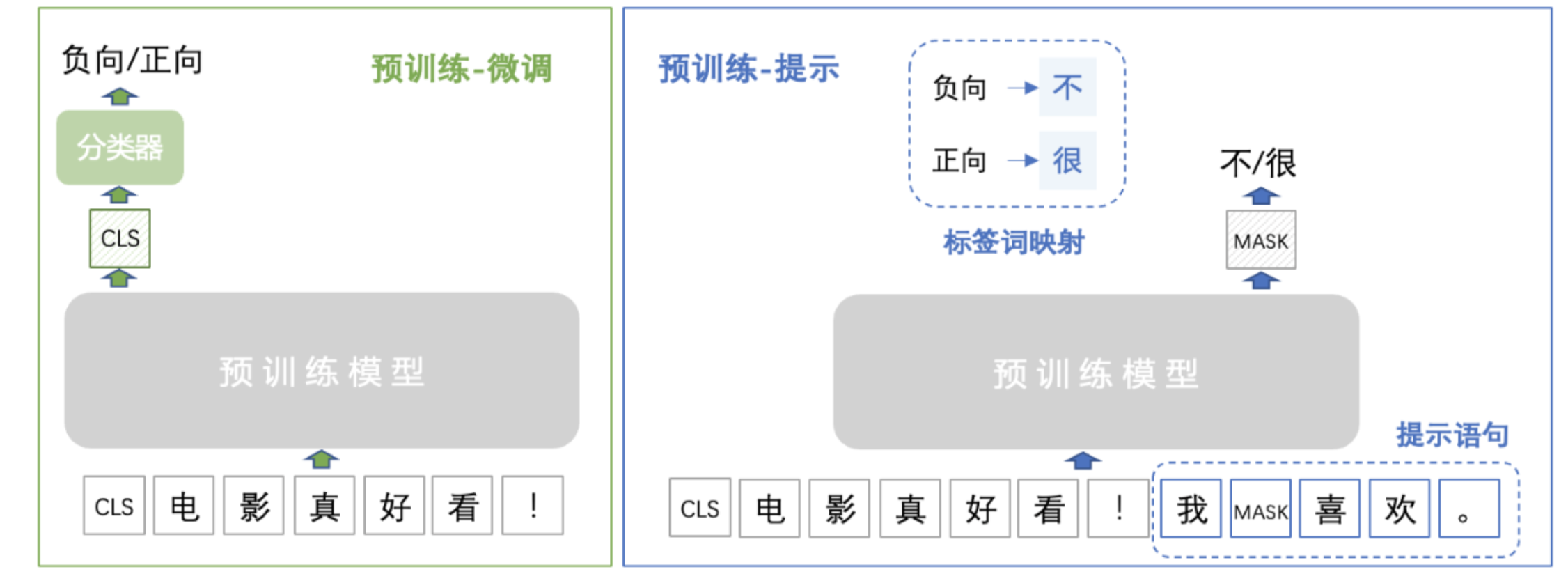
第四范式指的是将下游任务的建模方式重新定义,通过合适的prompt来实现直接在预训练模型上解决下游任务,这种模式需要极少量(甚至不需要)下游任务数据,使得小样本、零样本学习成为可能。
问题与缺陷
1. 零样本/少样本学习能力差
2. 模型专用性导致成本高昂的大规模预训练模型,无法通用到不同任务。
预训练模型中存在大量知识;预训练模型本身就具有少样本学习能力,希望能有一个范式可以利用预训练模型学到的知识且能做到部分通用性,fine-tuning的部分减少
方法及原理
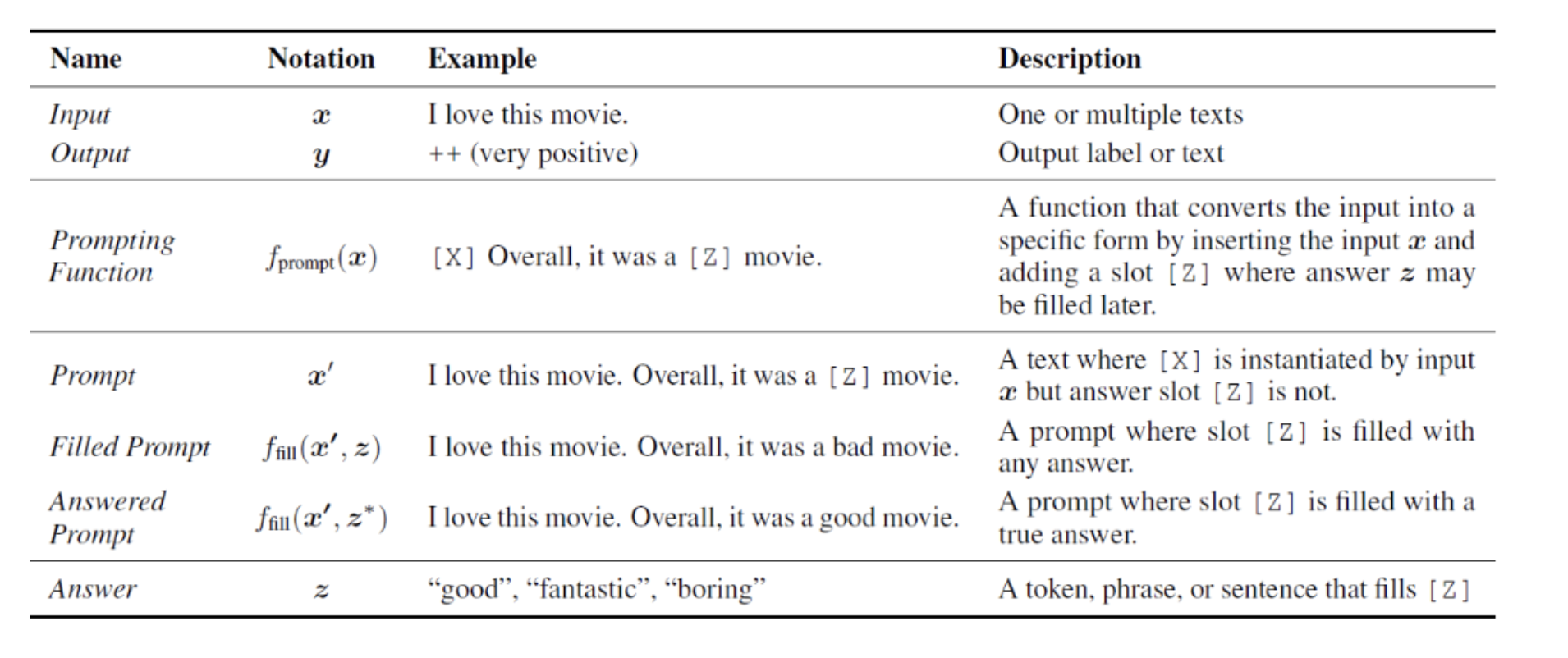
对于输入的文本,有函数将输入文本x转换成prompt形式的
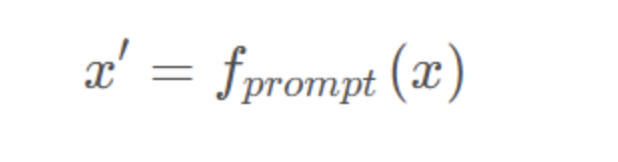
该函数通常会进行两步操作:
【1】使用一个模板,模板通常为一段自然语言的句子,并且该句子包含两个空位置:用于填输入的文本的位置[X],用于生成答案文本Z的位置[Z]
【2】把输入x填到[X]的位置
Prompt Learning 的本质
包括三个步骤:
-
设计预训练语言模型的任务
-
设计输入模板样式(Prompt Engineering)
-
设计label 样式 及模型的输出映射到label 的方式(Answer Engineering)
预训练语言模型
from transformers import BertConfigfrom transformers import BertModelfrom transformers import BertTokenizer

from transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained("bert-base-cased")tokenizer("Using a Transformer network is simple")# 输出'''{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}'''
如何定义模板
模板(Template)的功能是在原有输入文本上增加提示语句,从而将原任务转化为 MLM 任务,可以分为离散型和连续型两种。模板由不同字段构成,可任意组合。每个字段中的关键字定义了数据文本或者提示文本,即 input_ids,属性可定义该字段是否可截断,以及对应的 position_ids,token_type_ids 等。
什么是MLM 任务?
MLM(Masked Language Model),指的是BERT模型的一种预训练方式(在 BERT 模型中,被遮蔽的部分由两种符号组成:80% 的部分会被替换成特殊标记 [MASK],10% 的部分会被替换成其他随机的单词,而剩下的 10% 部分则不做任何处理)

人工设计模板
Prompt 的模板最开始是人工设计的,人工设计一般基于人类的自然语言知识,力求得到语义流畅且高效的「模板」。人工设计模板的优点是直观,但缺点是需要很多实验、经验以及语言专业知识。
自动学习模板
自动学习的模板又可以分为离散(Discrete Prompts)和连续(Continuous Prompts)两大类
离散型模板(hard-prompt)
离散型模板 是直接将提示语句与原始输入文本拼接起来,二者的词向量矩阵共享,均为预训练模型学到的词向量矩阵。
sample = {
"text_a": "心里有些生畏,又不知畏惧什么", "text_b": "心里特别开心", "labels": "矛盾"
}
“心里有些生畏,又不知畏惧什么”和“心里特别开心”之间的逻辑关系是[MASK]
硬模板方法
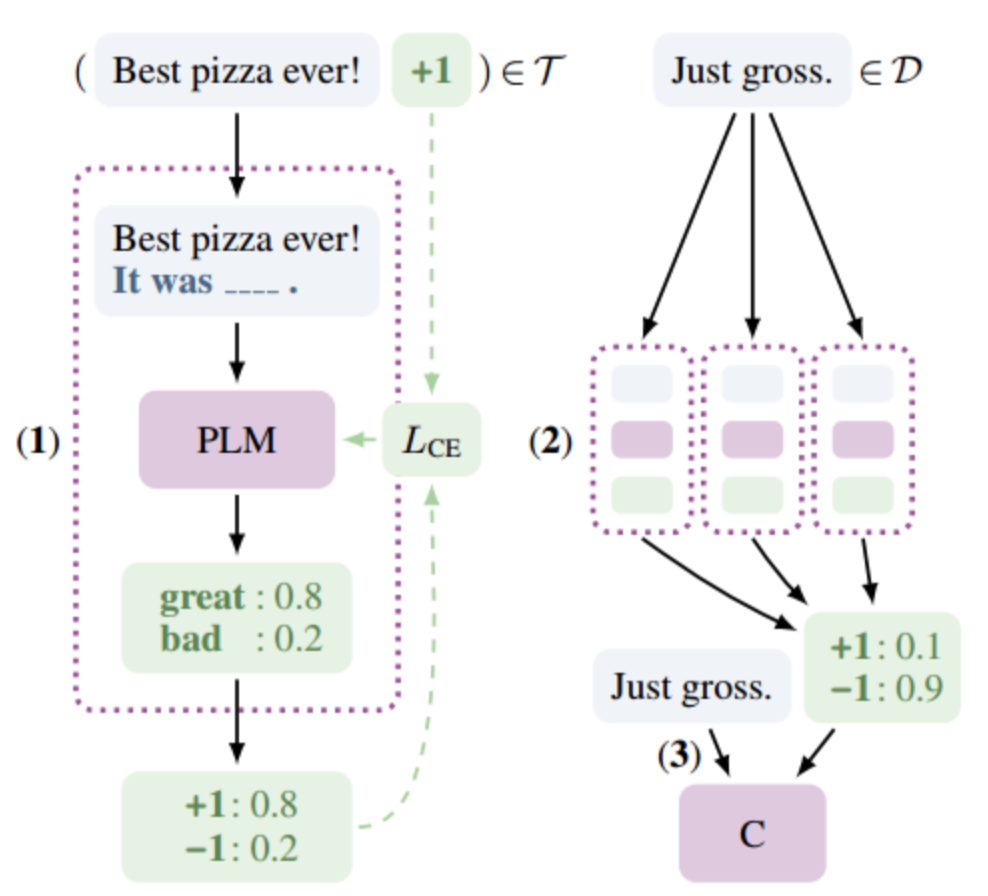
硬模版-PET(Pattern Exploiting Tranning)
-
在少量监督数据上,给每个 Prompt 训练一个模型;
-
对于无监督数据,将同一个样本的多个 prompt 预测结果进行集成,采用平均或加权(根据acc分配权重)的方式,再归一化得到概率分布,作为无监督数据的 soft label ;
-
在得到的soft label上 finetune 一个最终模型。
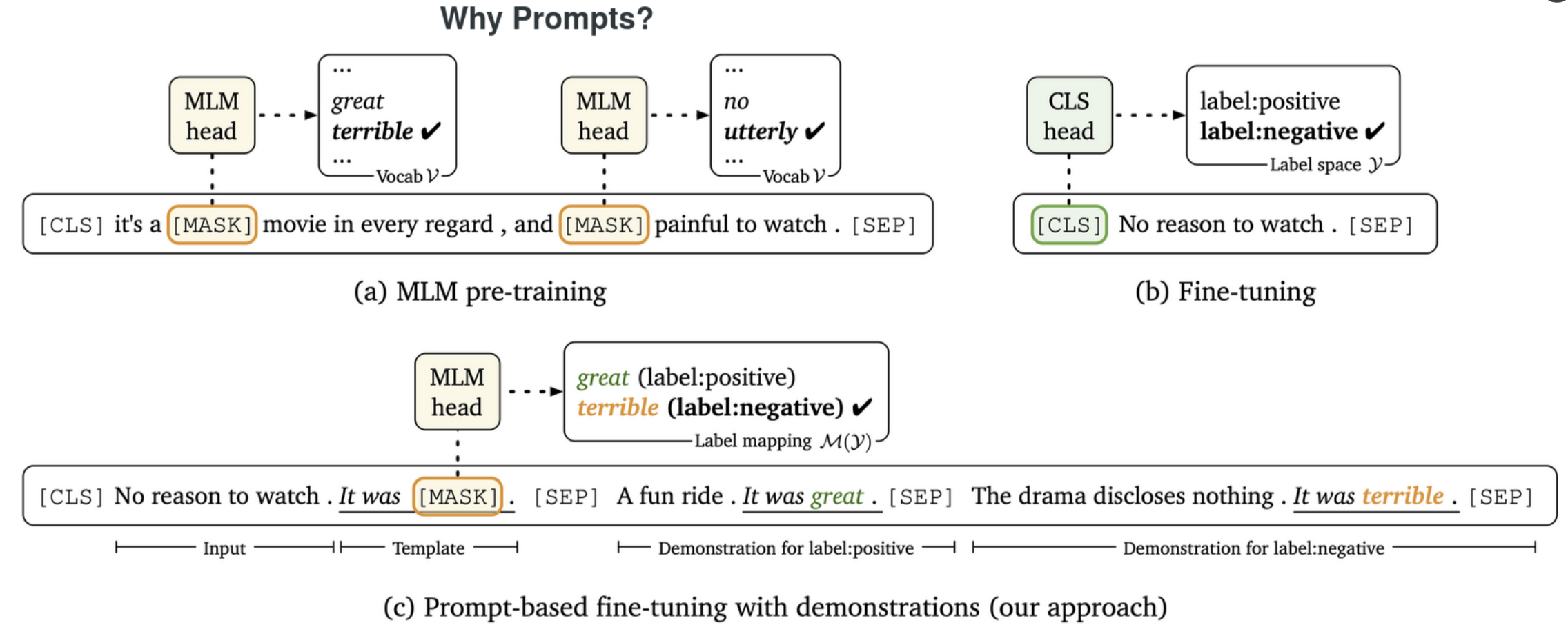
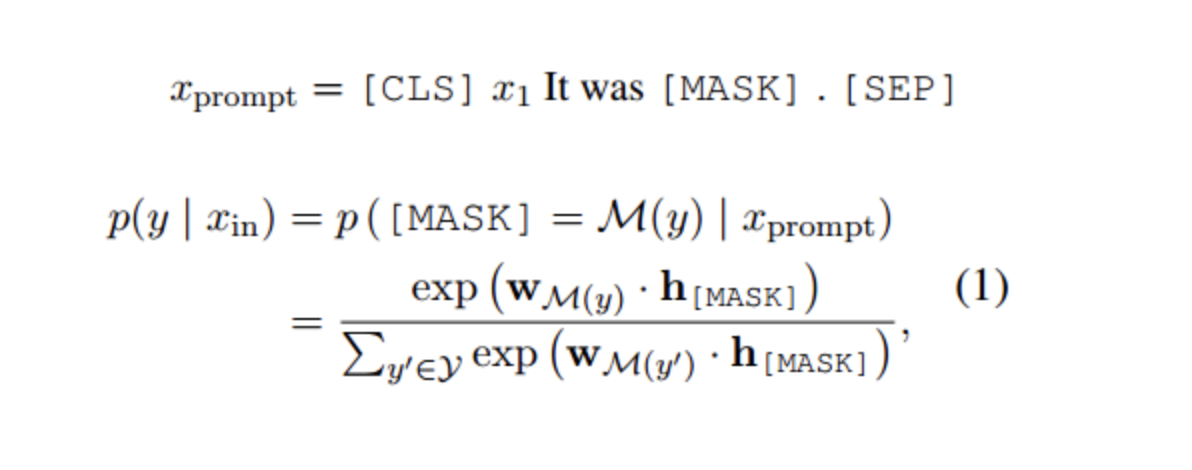
连续型模板
离散型模板的使用难点在于设计一个好的提示语句需要很多经验和语言专业知识,为了解决这一问题,连续型模板 尝试使用一组连续性 prompt 向量作为模板,这样模型训练时就无需人工给定提示语句。当然,也支持用人工构造的提示来初始化 prompt 向量。与离散型模板的区别在于连续型提示向量与输入文本的词向量矩阵不共享,二者在训练过程中分别进行参数更新。
-
对于分类任务,推荐的连续型提示长度一般为10-20。
-
对于随机初始化的连续性 prompt 向量,通常用比预训练模型微调更大的学习率来更新参数。
-
与离散型模板相似,连续型模板对初始化参数也比较敏感。自定义提示语句作为连续性 prompt 向量的初始化参数通常比随机初始化效果好。
前缀连续型模板
PrefixTemplate 同样使用了连续型向量作为提示,与 SoftTemplate 的不同,该模版的提示向量不仅仅作用于输入层,每层都会有相应的提示向量。


通过添加prefix给自回归网络,得到

或者给encoder-decoder结构生成,用来表示前缀的长度。
首先初始化一个可调的矩阵
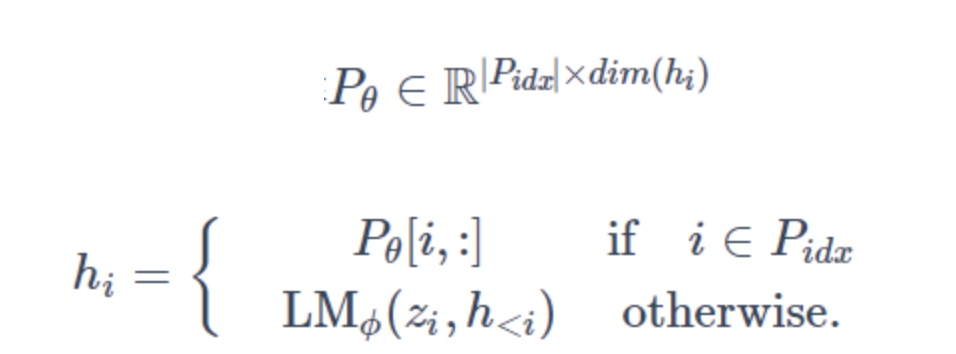
训练时,固定网络参数,只有前缀θ可调。
如何定义标签词映射
标签词映射(Verbalizer)也是提示学习中可选的重要模块,用于建立预测词和标签之间的映射,将“预训练-微调”模式中预测标签的任务转换为预测模板中掩码位置的词语,从而将下游任务统一为预训练任务的形式。
-
微调方式 : 数据集的标签为 负向 和 正向,分别映射为 0 和 1 ;
-
提示学习 : 通过下边的标签词映射建立原始标签与预测词之间的映射
总结
-
Prompt的设计问题。目前使用 Prompt 的工作大多集中于分类任务和生成任务,其它任务则较少,因为如何有效地将预训练任务和 prompt 联系起来还是一个值得探讨的问题。另外,模板和答案的联系也函待解决。模型的表现同时依赖于使用的模板和答案的转化,如何同时搜索或者学习出两者联合的最好效果仍然很具挑战性。
-
Prompt的理论分析和可解释性。尽管 Prompt 方法在很多情况下都取得了成功,但是目前 prompt-based learning 的理论分析和保证还很少,使得人们很难了解 Prompt 为什么能达到好的效果,又为什么在自然语言中意义相近的 Prompt 有时效果却相差很大。
存在的疑问
如何应用于生物信息学?
存在的挑战:
对于DNA、RNA、蛋白质序列,如何去构建一个合理的提示模板?
————————————————
版权声明:本文为CSDN博主「唐小星小宇宙」的原创文章如有侵权,请联系千帆社区进行删除
评论
