4
第二期“贺岁灵感模型”比赛冠军选手解题思路分享
大模型开发/技术交流
- LLM
- 千帆杯挑战赛
- LoRA
3月21日1504看过
大家好,我是第二期比赛获奖选手,张辉。很高兴和大家分享我的解题思路。
1、赛题内容
生成一个可制作贺岁文案内容的精调模型(限定使用ERNIE Speed,通过对模型精调使其保持原有能力的同时,具备准确理解并执行文案创作中创作长度相关指令的能力),第二期赛题链接。
a. 输入:包含创作长度要求的对文案创作的需求描述文本。(如:如何应对生成给领导的拜年文案;作为“I”人,如何在家庭群中发送讨长辈欢心的50字以内拜年语;如果你作为家长,如何辅助指导孩子完成“300字过年作文”的作业......)
b. 输出:严格符合长度要求且满足其他创作需要的创作内容。
2、解决方案
从赛题内容看,判断比赛方想要考察的内容其实是如何将大模型的能力复制到小模型上,也就是模型“蒸馏”,并使小模型表现出优秀的字数控制能力。因此自然的想法是,先通过ERNIE-Bot 4.0模型生成符合条件的数据集(大模型能力的数据表现),再使用这个数据集去微调ERNIE-SPEED小模型。我的解决方案是:原始数据集分析->数据集生成->模型训练->模型评估->应用部署。
2.1 原始数据集分析
原始数据集共56条数据,可分成5类:
第1类,20条,指定字数春节祝福语生成(30-80字,“假如你是X,请生成一段N字的春节祝福给X”)。
第2类,17条,长文生成(不少于200/300字,“生成春节主题相关内容,... 不少于200字”)。
第3类,7条,指定字数长文本生成(300/400字小作文创作,“请以喜迎春节为题目,写一篇300字小学生作文”)。
第4类,7条,限定长度春节祝福语转诗(限制100/150字内,“医生对患者的春节祝福语转诗,祝福语:...”)。
第5类,5条,限制长度长文本总结(限制100字内,“总结以下祝福信到100字以内,根据以下内容分别阐明经理对于每个岗位的期望,不要输出额外的内容...”)。
注意到数据集中的回答内容有些并不满足赛题要求(比如严格限制字数长度等),因此主要参考数据集的问题进行分析。
2.2 数据集生成
以原始数据集5类问题为基础,对数据集的问题进行扩充。调用ERNIE-Bot 4.0模型,通过few shot learning的方式进行扩充。使用的prompt 类似下面:
prompt = f"""
【数据扩充1】现在我想对一些问答数据集做扩充,请你仔细分析下列数据集问题的特点,写出一些类似的问题。
问题示例: {question_list}
请根据以上示例,再写出20个类似的问题,这些问题需要和“春节”相关,请严格以json格式输出结果。
"""
对5类问题各自进行30-60倍扩充(去重优化,修改字数要求进行二次扩充等),总共形成大约3000条数据。调用ERNIE-Bot 4.0模型,对这约3000个问题进行回答(多次回答,选择字数满足要求的回答内容),并最终形成包含大约2600条数据的数据集。随机选择其中80%作为训练集,其余20%作为测试集。
在实际生成数据集问题时,采用了一些技巧,比如对于ERNIE-Bot 4.0模型多次回答才能满足字数限制条件的问题,修改字数条件,进行多次采样(个人理解是这类问题比较难,需要模型去做针对性学习);模型生成结果的字数要求比官方要求更加严格(比如第一类问题,限制字数差<=2);第5类问题涉及到长文本总结,采用了两步法来生成问题。在赛后和大家的交流中,还注意到可以通过反向调整prompt的方式,来获得更加精准的生成结果等。
2.3 模型训练
选择SFT微调方法训练模型,按照赛题要求,基座模型选择的是ERNIE-Speed,采用LoRA方法进行微调,详细的训练参数配置如下:
迭代轮次 10
学习率 0.0003
保存日志间隔 1
日志保存间隔步数
LoRA所有线性层 True
LoRA 策略中的秩 8
序列长度 4096
预热比例 0.1
正则化系数 0.01
注:实际调参过程中,对迭代轮次进行了多次尝试,其它参数均选择系统默认值。
2.4 模型评估
最终版模型名称:新年贺岁模型V3
训练过程评估:
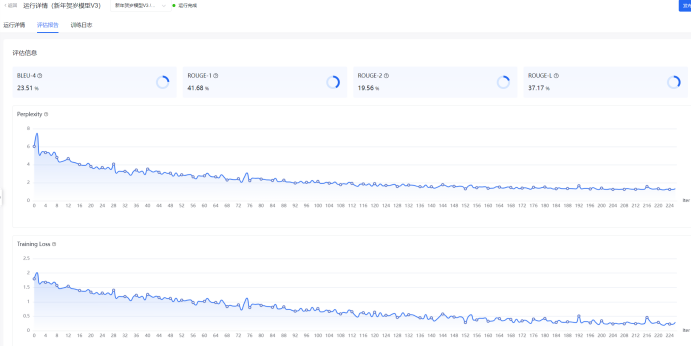
训练阶段的loss持续下降并趋于平稳,判断模型训练过程已经成功收敛。
系统自动评估结果:(在测试集上进行)
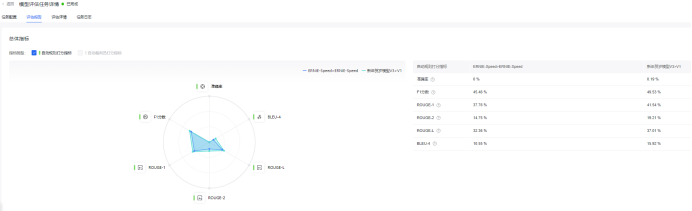
从系统自动评估任务看,新年贺岁模型V3 相比基线模型 ERNIE-SPEED,在系统多项指标上有明显提升,进一步的字数统计表明,新年贺岁模型V3实际效果有大幅提升。以测试集中第1类问题的回答结果进行分析(限制N字春节祝福语生成)
|
第1类问题
|
回答字数差<=2 占比
|
回答字数差<=5 占比
|
回答字数差<= 10 占比
|
|
ERNIE-SPEED
|
5%
|
11%
|
30%
|
|
新年模型V3
|
47%
|
85%
|
98%
|
2.5 应用部署
对训练好的模型进行部署。部分输入输出示例:
3、比赛心得
3.1 建立有效的评估体系
在模型训练完成后,对模型效果的准确评估非常重要。这可以让我们知道相对基线,新的模型效果提升了多少,从而帮助确定系统下一步迭代的方向。千帆平台提供了模型评估的相关方法,包括基于规则的ROUGE/BELU-4/F1分数,和自动裁判员打分等。但总体而言,这些评估方法给出的最终结果区分度不大,因此需要额外补充关键的评估方法。在比赛过程中,我自己保留了一份测试集(大约500条数据), 每当模型训练完成并部署后,都会在测试集上评估效果,通过统计模型生成结果的字数条件满足情况来判断模型效果。
3.2 数据规模很重要
从自己的参赛经历来看,数据规模非常重要,数据规模越大,模型的效果越好。以下是两个不同规模数据集训练出的模型效果对比:
|
第1类问题
|
回答字数差<=2 占比
|
回答字数差<=5 占比
|
回答字数差<= 10 占比
|
|
ERNIE-SPEED
|
5%
|
11%
|
30%
|
|
新年模型V2_4(约800条训练数据)
|
35%
|
69%
|
88%
|
|
新年模型V3(约2000条训练数据)
|
47%
|
85%
|
98%
|
3.3 模型训练参数空间的快速搜索
由于训练数据集比较大,每次训练任务的花费较高(约100-300元),导致实际上能够尝试的次数非常有限。为了部分解决这个问题,在参赛过程中,我先通过小的数据集进行了多次尝试,并确保在训练过程中,loss能够大幅下降并趋于平缓。在模型训练的多个参数中,训练轮次参数非常重要。我最终选择了比较大的训练轮次,尽管从测试集上的loss来看,模型出现了过拟合的情况,但从字数满足条件的评估中,这种情况下,模型的表现效果反而更好。
3.4 小模型有可能在特定方向上胜过大模型
比赛最终得到的ERNIE SPEED微调模型,在比赛场景下的文字生成能力是要强于ERNIE-BOT 4.0模型的。从某种视角来看,由模型生成的数据集,其实是模型能力的外在表现。当我们对这个数据集进行进一步筛选,相当于额外增加了人类经验,从而得到了更优质的数据集。使用这个更优质的数据集训练小模型,是完全有可能获得一个比大模型效果更好的精调模型的。
以上就是我本次比赛的分享内容,希望大家读完能有所收获。我是一名算法工程师,对大模型技术充满热情,非常希望能够结识同样对技术充满热情、对未来充满想象的朋友。我时常想象10年后的生活会是什么样子,AI会扮演什么角色,那一定会是各种AI助理触达我们生活方方面面、所有线下和线上事物有着“灵魂”,我称之为“万物有灵”的时代吧!“君子藏器于身,待时而动”,希望能和所有对未来充满想象和憧憬的朋友,一起去构建那“万物有灵”的时代~
张辉 (微信SR1789,邮箱 2942882394@qq.com)
评论
