使用Ollama本地部署Llama 3.1大模型
大模型开发/技术交流
- 开源大模型
- LLM
- 大模型推理
2024.07.2910002看过
☞ 如果您在大模型落地过程中遇到任何问题,可以提交工单咨询:https://console.bce.baidu.com/ticket/#/ticket/create?productId=279
☞ 同时,大模型技术专家可为您提供效果调优、应用定制和技术培训等付费专属服务:https://cloud.baidu.com/product/llmservice.html
Llama 3.1 介绍
2024 年 7 月 24 日,Meta 宣布推出迄今为止最强大的开源模型——Llama 3.1 405B,Llama 3.1 405B 支持上下文长度为 128K Tokens,增加了对八种语言的支持,号称第一个在常识、可操纵性、数学、工具使用和多语言翻译方面与顶级人工智能模型相媲美的模型。
当然 405B 新一代大模型所需要的算力成本也是巨大的,一般的中小型企业和个人需要慎重评估一下成本与产出是否值得应用。好在作为新版本发布的一部分,官方也同时推出全新升级的 Llama 3.1 70B 和 8B 模型版本。
我们今天就在百度智能云 GPU 服务器上来部署体验最新 Llama3.1 8B 模型。
安装环境
硬件环境
-
百度智能云 GPU 服务器。
本文以百度智能云 GPU 服务器为例进行安装部署,购买计算型 GN5 服务器, 配置 16 核 CPU,64GB 内存,Nvidia Tesla A10 单卡 24G 显存,搭配 100GB SSD 数据盘, 安装 Windows 2022 Server 系统。
-
如果您使用自己的环境部署,建议 NVIDIA GPU,民用卡 30、40 系列,商用卡 T4、V100、A10 等系列,至少 8G 以上显存。服务器配置建议最低配置为 8 核 32 G 100G 磁盘,5M 带宽。
安装步骤
购买服务器
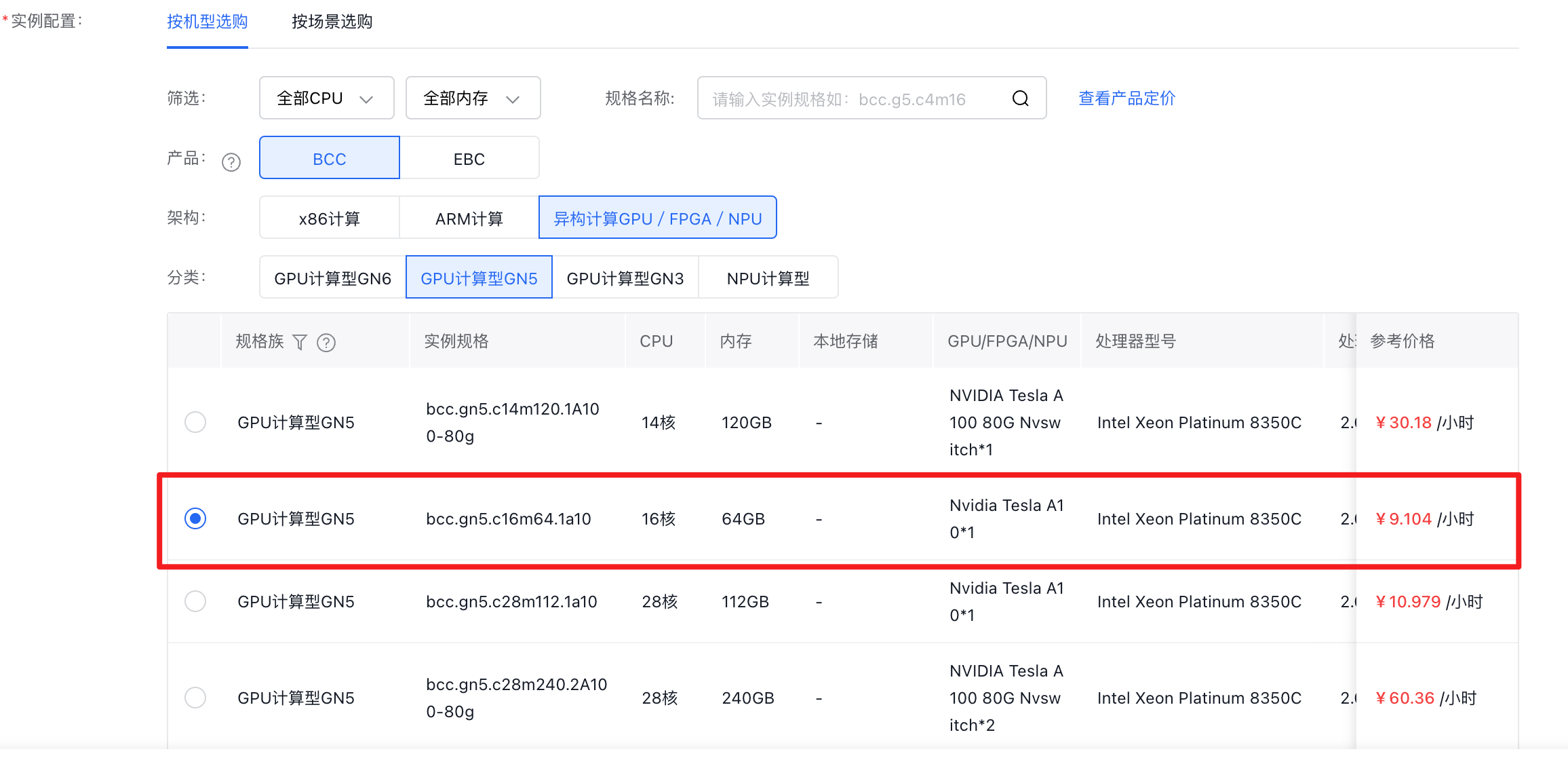
-
安装操作系统
-
选择 Windows 公共镜像,支持 Windows2019 及以上版本,本教程我们选择 Windows2022 。

-
通过 VNC 登录实例,安装 GPU 驱动程序。
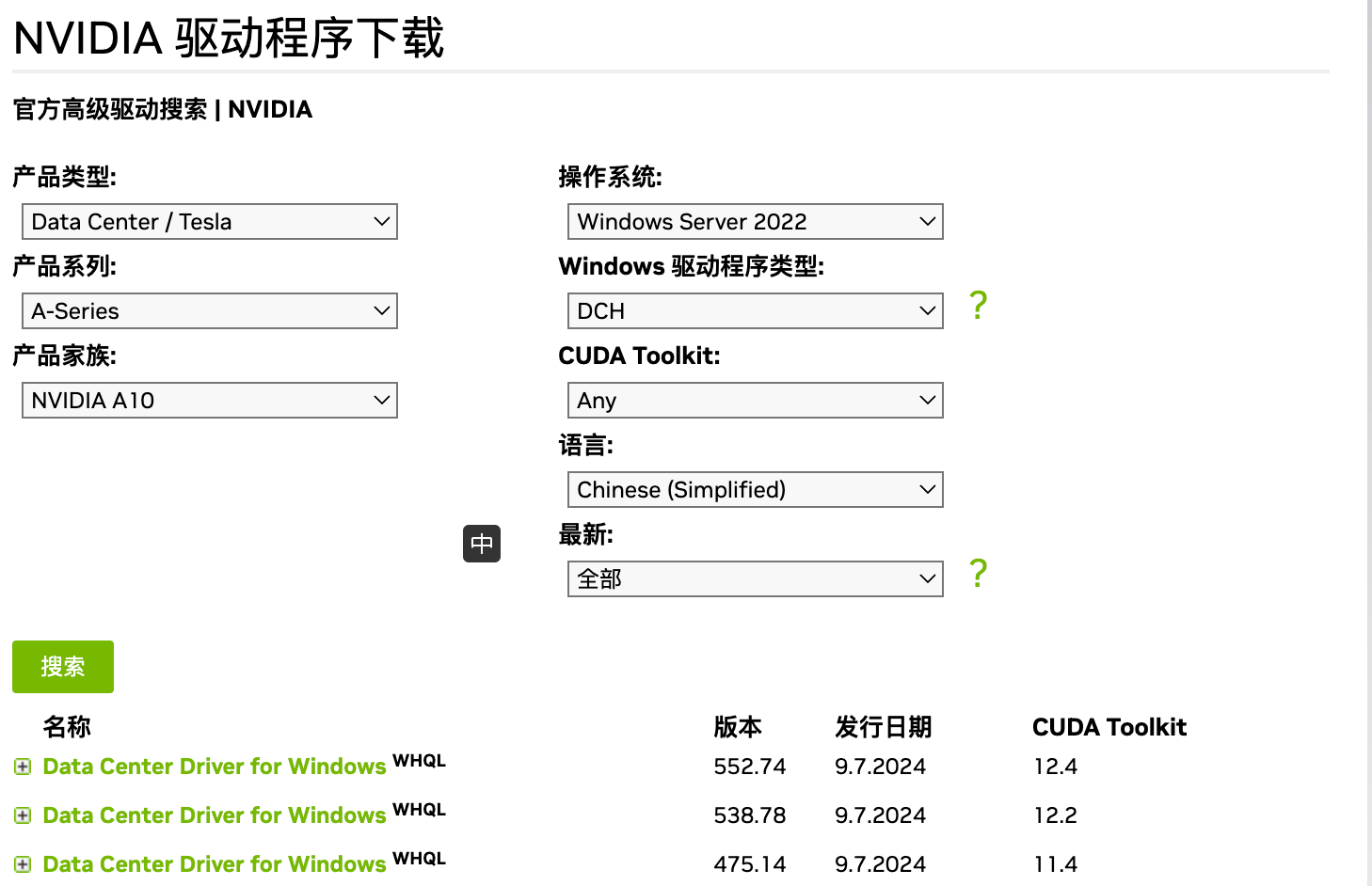
安装 Ollama 客户端
-
安装完毕会自动运行,右下角可以看到这个图标:
-
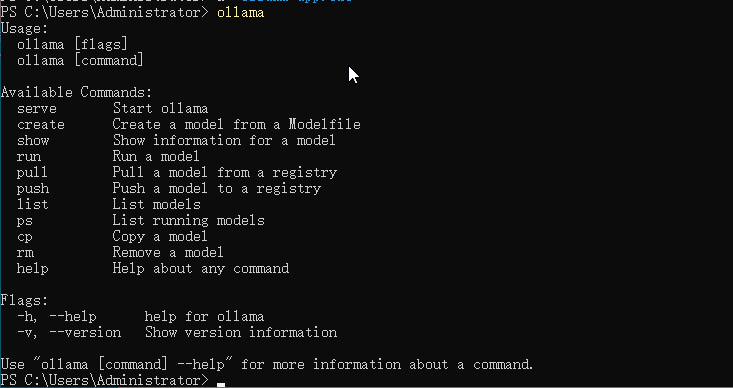
打开 windows powershell 或 CMD 命令行终端,输入 ollama 命令,回车,即可显示 ollama 命令的使用帮助
下载模型文件
加载模型
-
由于 A10 GPU 只有 24G 显存,因此我们安装 8b 模型版本,如果您的显存 80G 以上,那么推荐安装 70b 模型版本。
在命令行中输入如下命令,即可在线拉取模型。
ollama run llama3.1:8b
如果您的显卡非常好,其他两个模型的拉取命令如下 :
ollama run llama3.1:70bollama run llama3.1:405b
-
出现
success提示时,说明模型加载完成,可以愉快地跟大模型交流了。

更多模型支持
当然 ollama 不仅支持运行 llama3.1,实际上他支持更多的开源模型,详细教程见官方文档:模型库
手动导入模型
如果您的网络情况不太好,在线下载模型进度缓存,官方也支持从其他渠道下载好的模型导入。
详细参考导入模型,这里不做赘述。
模型应用
直接在控制台中对话
模型加载完成之后,出现如下提示,就可以直接跟大模型对话了。

配置远程访问
Ollama 启动的默认地址为
http://127.0.0.1:11434,我们通过设置环境变量 OLLAMA_HOST来修改默认监听地址和端口,这往往对我们需要远程调用API时非常有用。同时,如果要在open-webui等UI面板中调用 API ,需要为 Ollama 进行跨域配置后方可正常使用。
需要了解如下三个变量的用途
|
变量名
|
值
|
说明
|
|
OLLAMA_HOST
|
0.0.0.0:8888
|
用于配置监听的 IP 和端口
|
|
OLLAMA_ORIGINS
|
*
|
支持跨域访问,也可以指定特定域名,如:"baidu.com,hello.com"
|
|
OLLAMA_MODELS
|
C:\Users\Administrator\.ollama
|
模型文件较大,建议调整到数据盘目录下。
|
windows 修改环境变量如下:
-
停止 ollama 服务
右下角这个图标,右键选择退出 。
-
设置环境变量
右键"此电脑 > 属性 > 高级系统设置 > 环境变量 > Administrator 的用户变量 > 新建用户变量"。

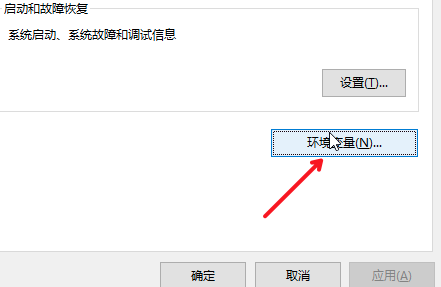
设置环境变量,表示监听在
0.0.0.0:8888上,其他变量设置依次添加。
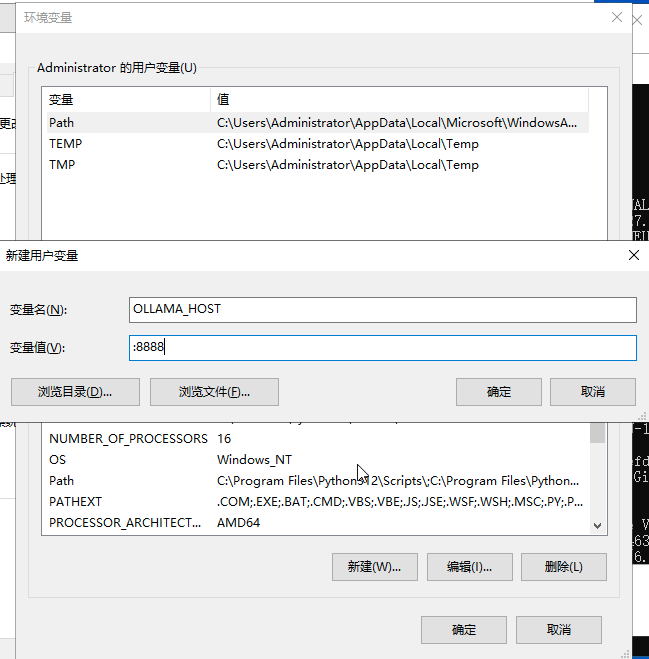
-
设置完毕环境变量,打开新的 powershell 或者 CMD 命令行终端, 重新启动 ollama 服务并加载模型。
ollama run llama3.1:8b
API 调用
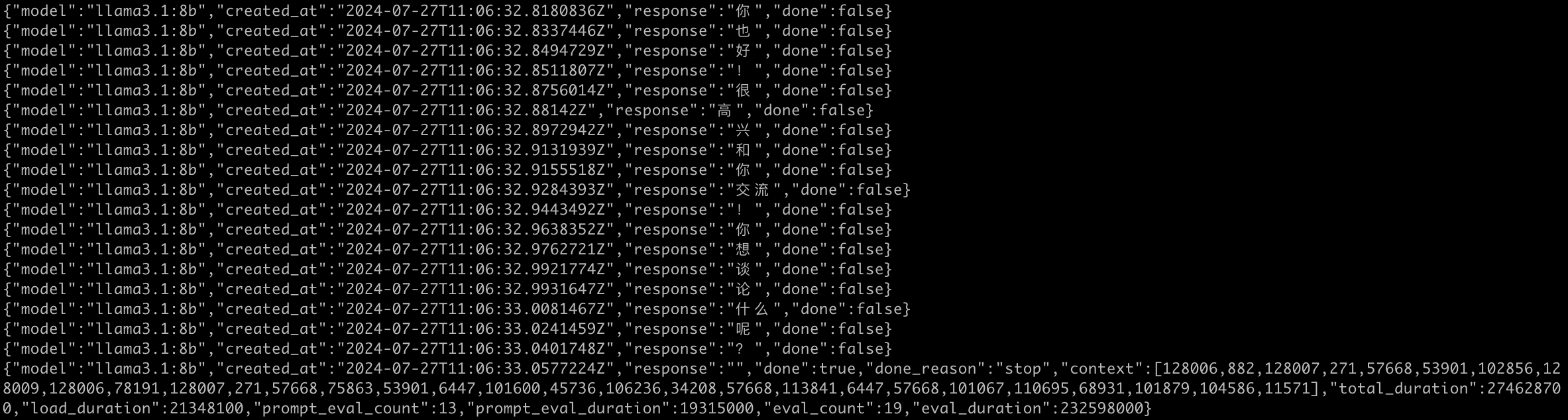
开启远程连接之后,您就可以远程调用 API 了,示例如下:
curl http://106.12.151.249:8888/api/generate -d '{"model": "llama3.1:8b","prompt": "你好啊"}'
流式输出:
Web UI
上面的对话测试,我们都是通过命令行来进行交互的,当然肯定有可视化的 UI 界面,而且很多,这里介绍两个。
Open WebUI
-
安装
官方给出了两种安装方式
-
使用 docker 安装。这个是官方推荐的安装方式,方便快捷,但不幸的是,百度智能云 Windows Server 不支持二次虚拟化,Windows 上需要虚拟 Linux 环境才能安装 Docker。如果您使用的是 Linux 环境,可以通过 Docker 安装,本教程不使用这种。
-
使用 pip 安装。
有两个注意点:
1) 您的 Python 版本不能为 Python3.12,因为截至本教程编写时,open-webui 还不支持 Python3.12,本教程使用 python3.11 环境,如您 windows 系统中已经有安装 Python3.12,推荐使用Anaconda 来管理多个 Python 运行环境。
2) 运行依赖 pytorch,如您的环境没有安装,执行如下命令安装依赖:
pip install torch torchvision torchaudio --index-urlhttps://download.pytorch.org/whl/cu121
详细安装过程不做赘述,参考官方安装文档
-
使用
-
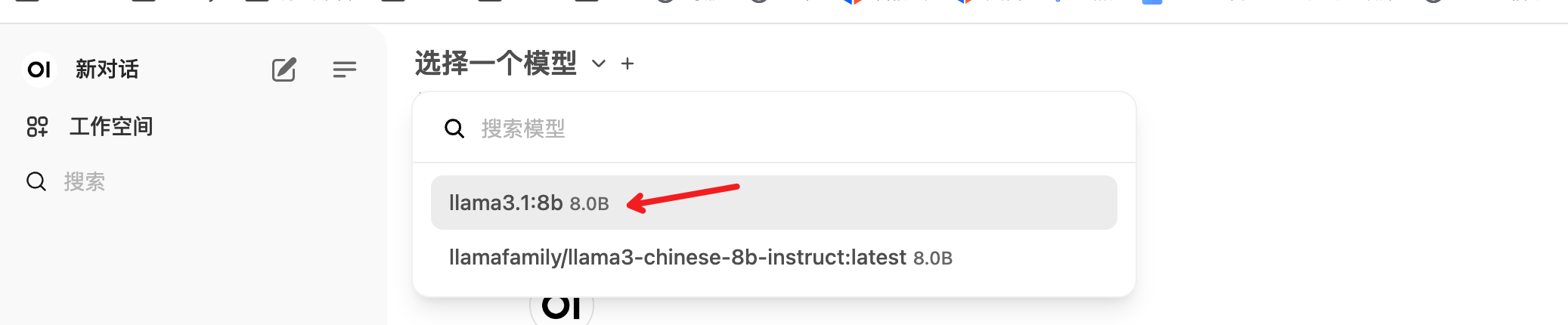
打开页面,注册登录,进入设置,将ollama服务器中的模型加载进来。
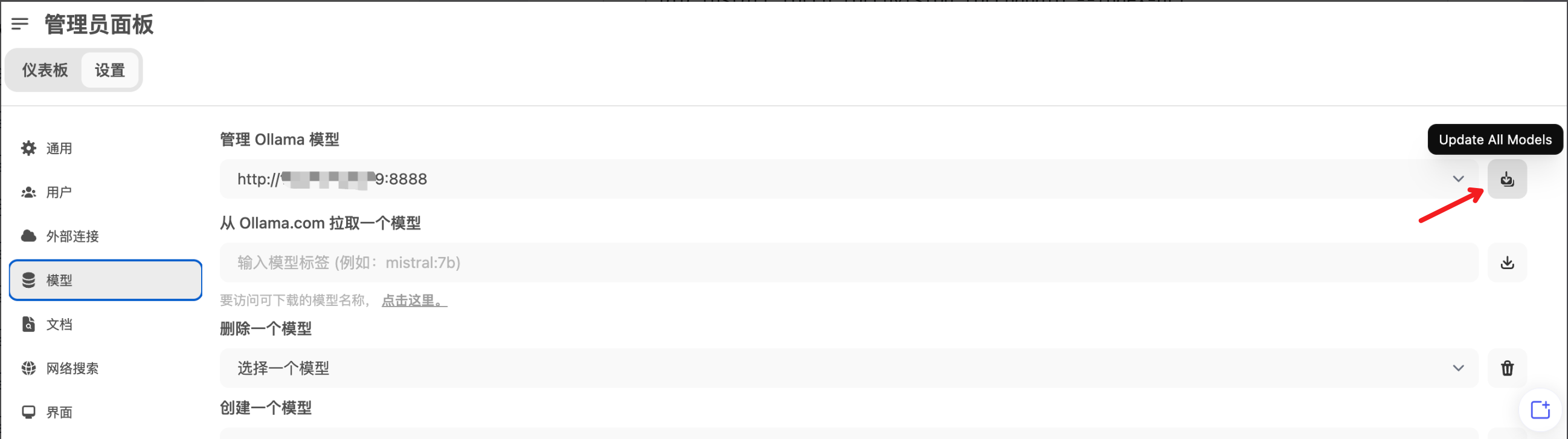
-
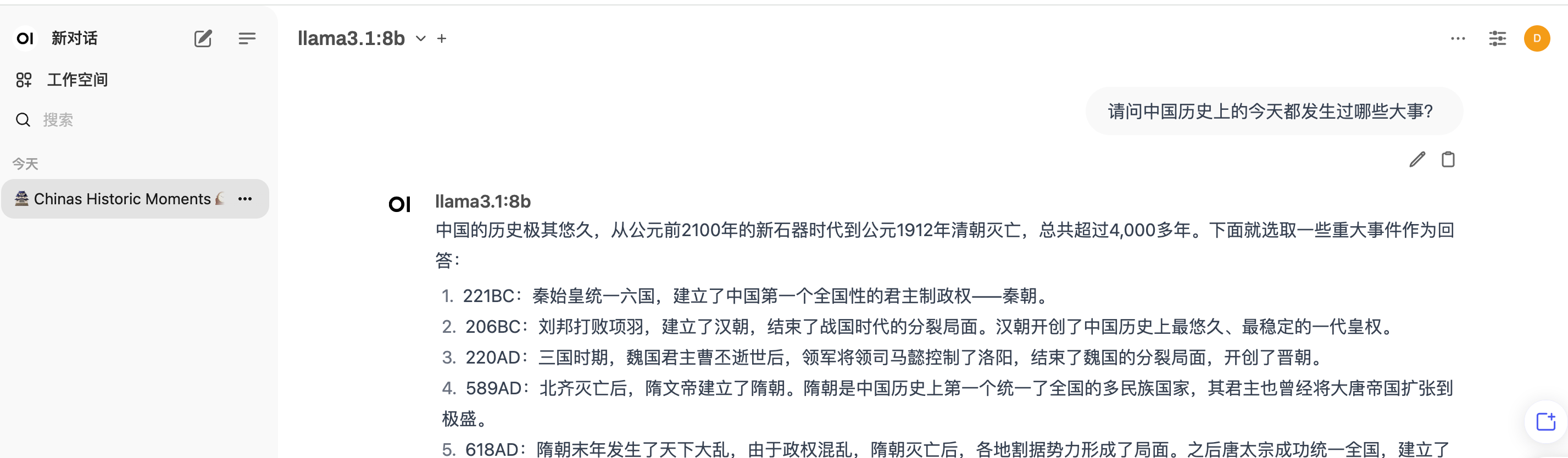
加载成功后,回到对话界面,可以开始聊天了。
-
问个问题,响应速度还是不错的。
LobeChat
-
安装
详细安装过程不做赘述,参考官方安装文档。
-
使用
-
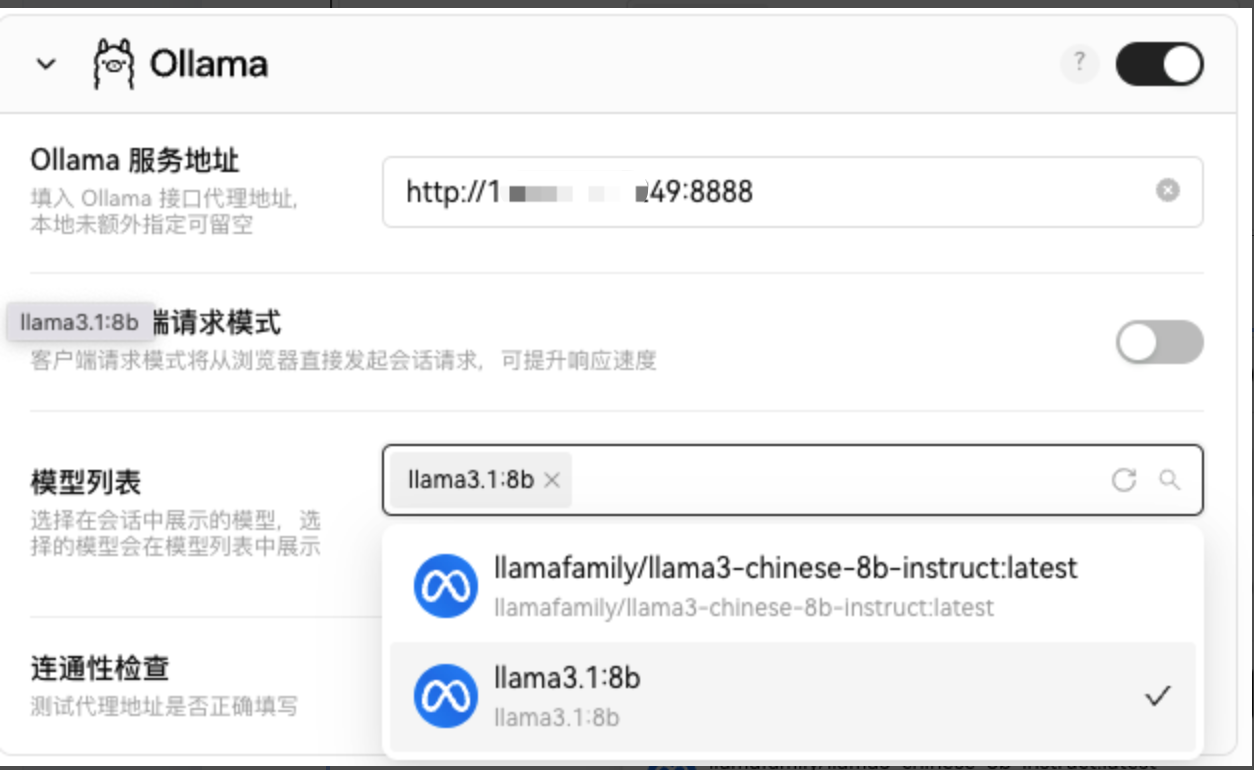
在设置里,选择语言模型,找到Ollama,开启它,并做连通性检查 。
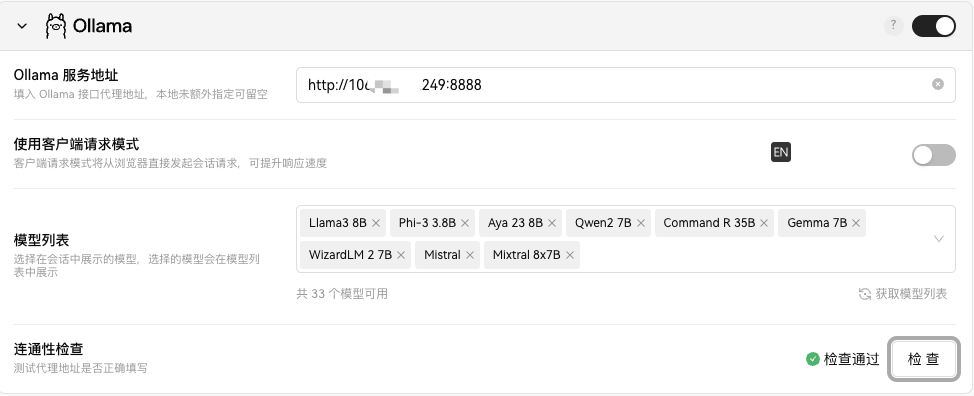
-
检查通过,获取模型列表
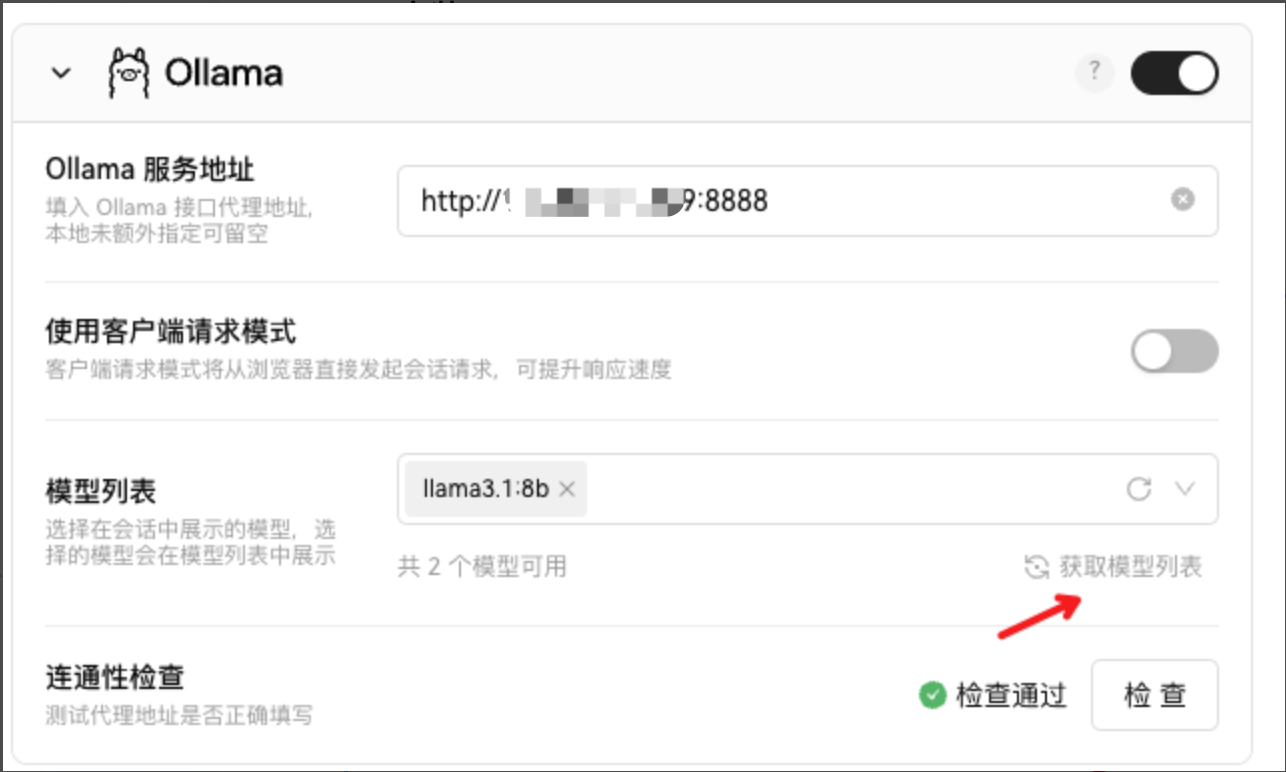
-
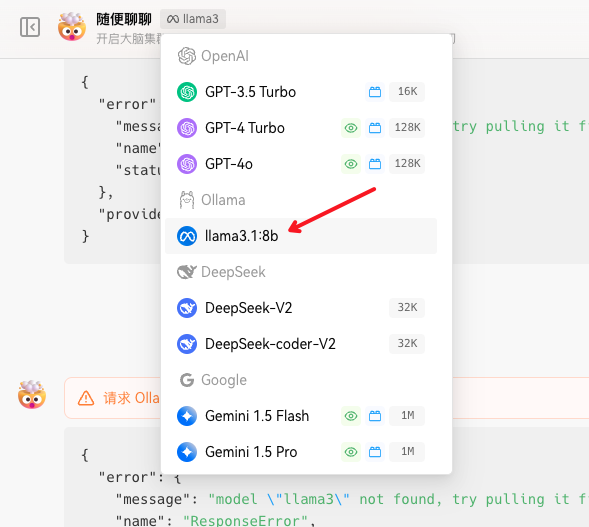
回到聊天窗口,选择llama3.1:8b模型
-
开始愉快的聊天吧。

评论
