5
让你轻松免费构建本地知识库的全过程
大模型开发/技术交流
- 有奖征文
8月22日1779看过
【前言】
在这个数据驱动的时代,信息的快速检索与高效利用成为了各行各业竞争力的关键所在。面对海量数据,如何快速构建一套灵活、高效的本地向量数据库,成为了许多开发者、数据分析师及企业决策者共同面临的挑战。传统的数据库架构在面对复杂多维的向量数据时,往往显得力不从心,而构建专门的向量数据库则成为了解锁数据价值的新钥匙。
今天,我们将带您踏上一场轻松而免费的旅程,全程揭秘如何一步步构建属于您自己的本地向量数据库。无需复杂的配置,无需高昂的成本,只需跟随我们的指引,利用开源工具和最佳实操,您就能轻松驾驭向量数据的存储、查询与分析,让数据真正成为推动业务增长的强大引擎。
无论您是初涉数据领域的探索者,还是寻求技术升级的专业人士,本文都将为您提供一套详尽、易上手的解决方案。让我们一起,开启向量数据库构建的奇妙之旅,探索数据背后的无限可能!
首先按照这个地址拿到这个压缩包,解压缩
# 下载 SDK,可以使用 wget,也可以直接浏览器访问下载地址下载到本地。wget http://public-vdb.bj.bcebos.com/ragflow-python-sdk-1.1.zip# 解压下载的 SDK 包unzip ragflow-python-sdk-1.1.zip
Windows
打开浏览器,访问下列网站即可下载http://public-vdb.bj.bcebos.com/ragflow-python-sdk-1.1.zip然后解压缩

然后看到 setup.py 文件。然后cmd输入一下命令,下载官方配置好的所有所需要包。
py setup.py install
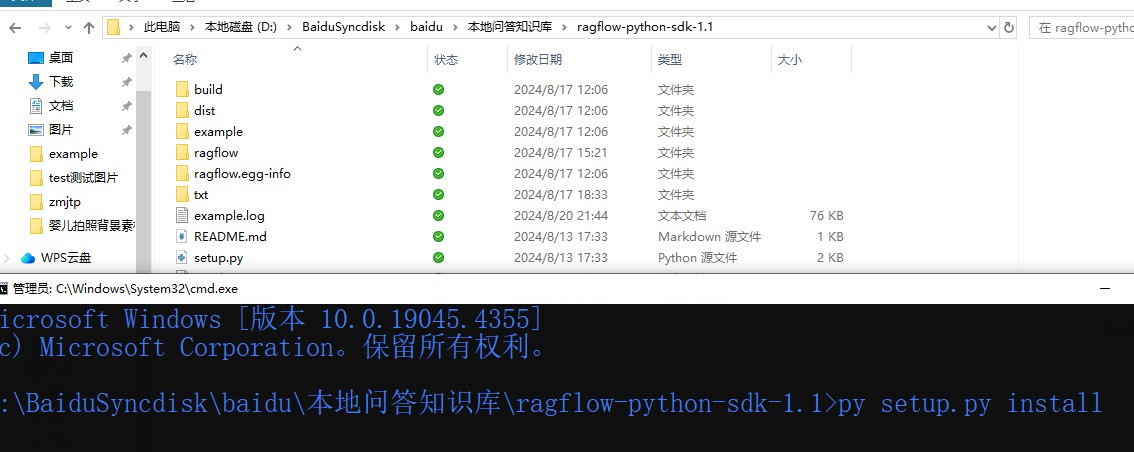
时间有点久,安心等待即可,如果出现下载中断的情况,建议使用管理员命令行执行命令。
可能出现的问题一:
当你前面在cmd命令行已经执行过 “py setup.py install”,然后再次执行这个命令就会出现下列问题。
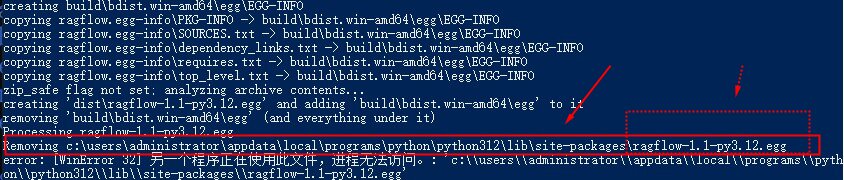
解决办法:
找到对应的文件夹“site-packages”下面的
“ragflow-1.1-py3.12.egg” 这个文件。
路径可能不同,关键是找到提示所对应的文件。
找到后,删除掉“ragflow-1.1-py3.12.egg” ,重新执行即可。
像我中间因为网络的原因,下载很慢,等待中断过好几次,上面的问题出现了好几次。
可能出现的问题二:
还出现下载完后,仍然有包没有安装完的情况,如下:
解决办法就是,手动安装,提示缺什么包,就安装什么
pip install 【提示的缺失包名】
当所有包安装完后提示

然后找到“ ragflow-python-sdk-1.1\example\example.py ”,执行
py example.py
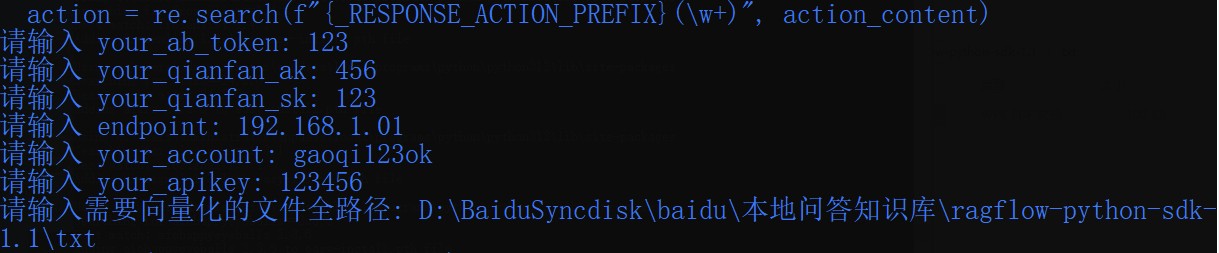
以上是示例输入,各位按个人账号信息,如实填入
|
提示
|
内容说明
|
|
your_ab_token
|
AppBuilder 的密钥
|
|
your_qianfan_ak
|
ModelBuilder 的 API Key
|
|
your_qianfan_sk
|
ModelBuilder 的 Secret Key
|
|
endpoint
|
向量数据库的访问地址
|
|
your_account
|
向量数据库的账号
|
|
your_apikey
|
向量数据库的密钥
|
|
文件全路径
|
需要录入的知识库的 pdf 文件, 可使用 sdk 自带的 pdf 文件 example/example_data/RAG.pdf
|
AppBuilder 的密钥
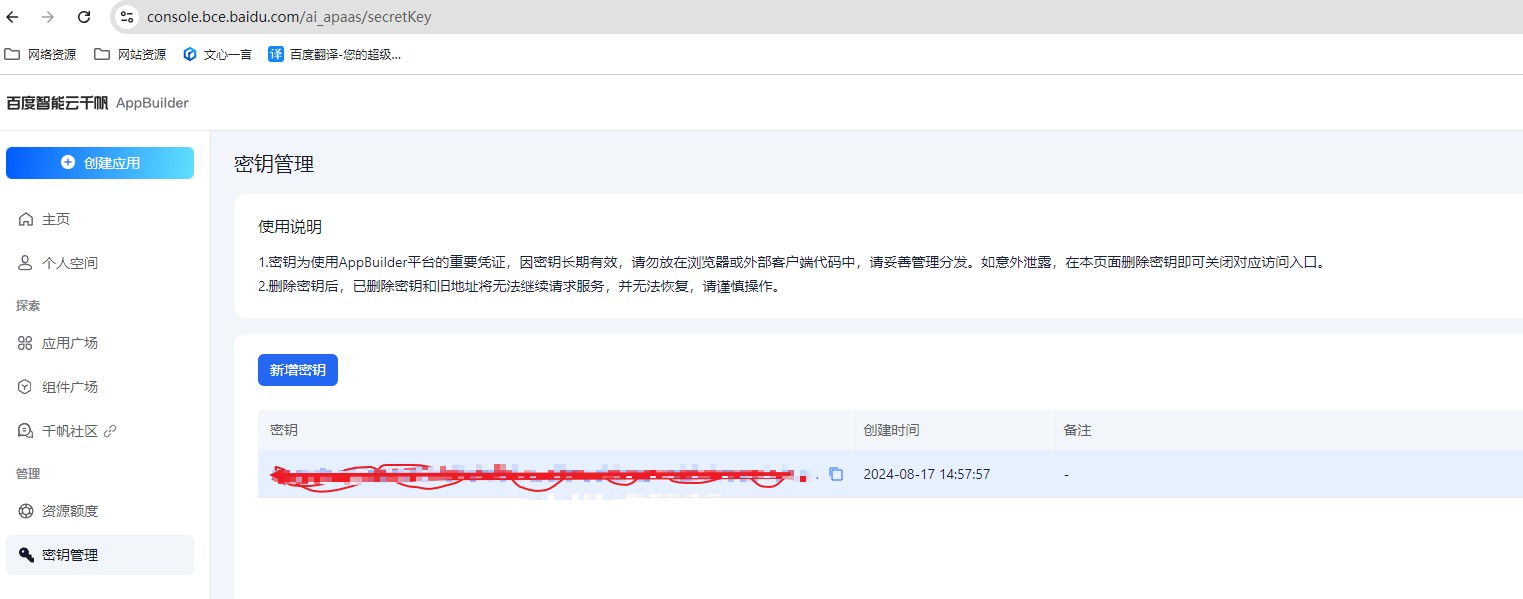
ModelBuilder 的 API Key 和 Secret Key
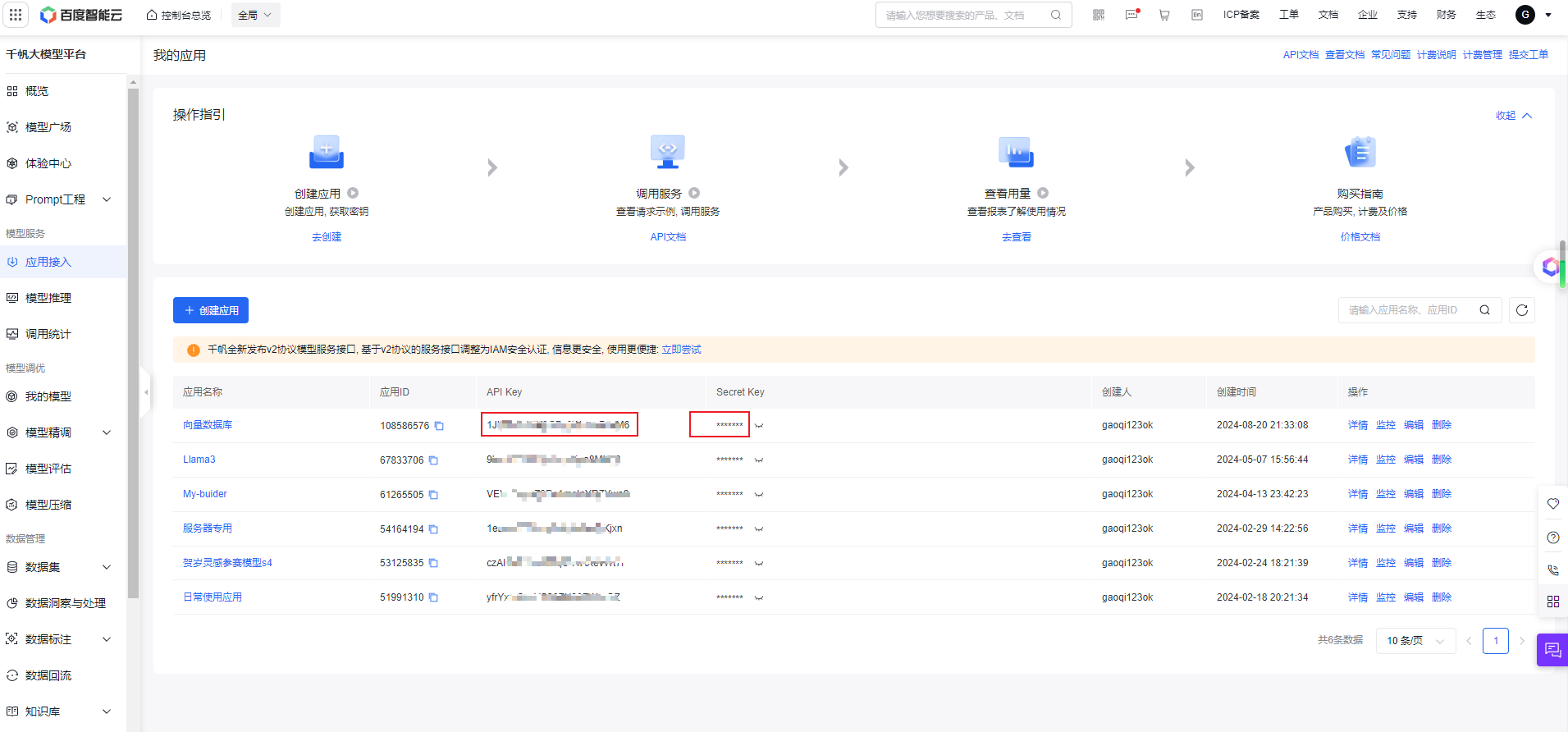
ModelBuilder中还得额外开通这三个模型,“Embedding-V1” 、“bce-reranker-base”和“ERNIE Speed-AppBuilder”

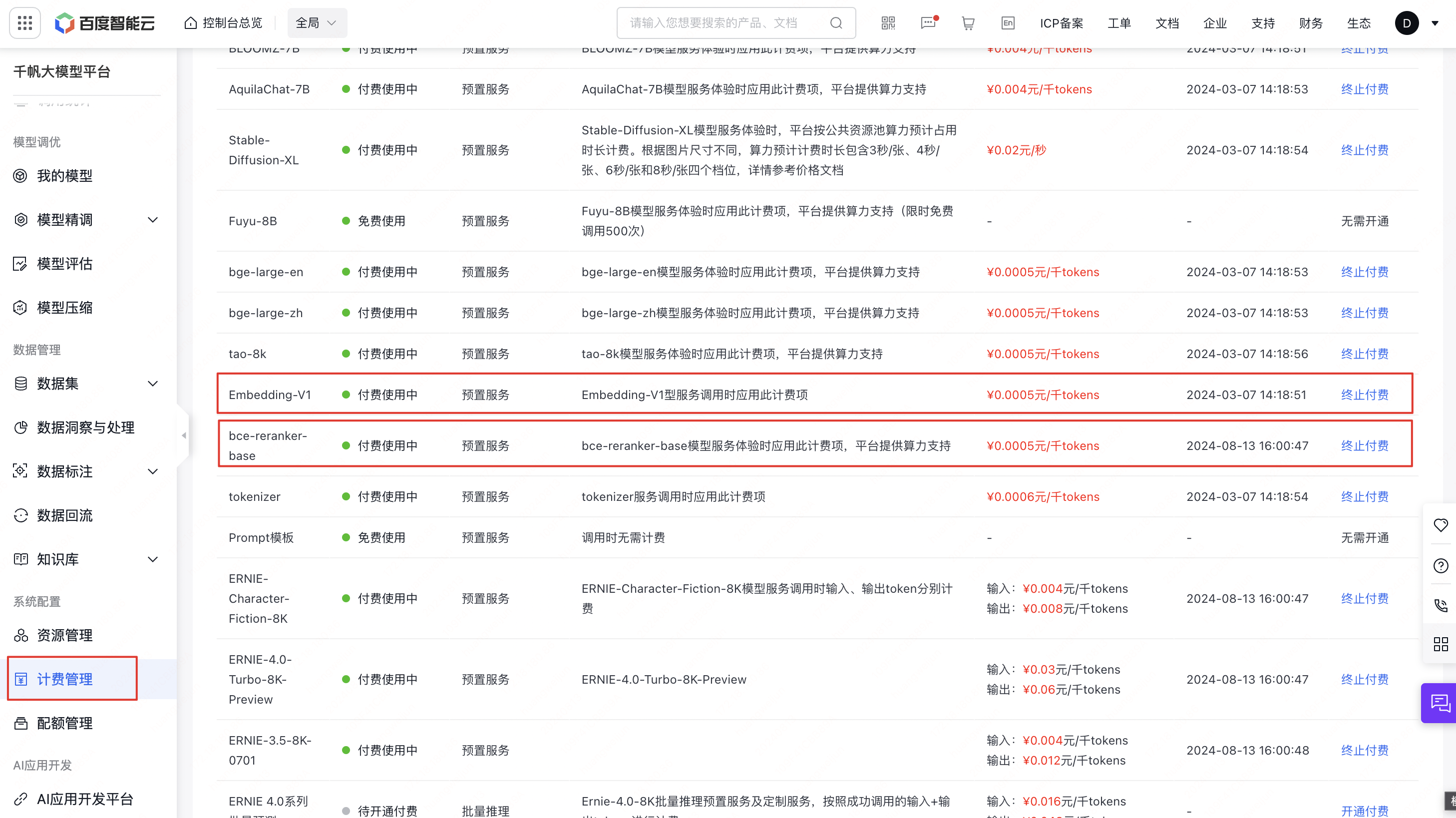
endpoint 创建一个公网ip,然后按要求填入,默认端口5287:
这个地方个人出过一些问题,也看见别的朋友出过问题
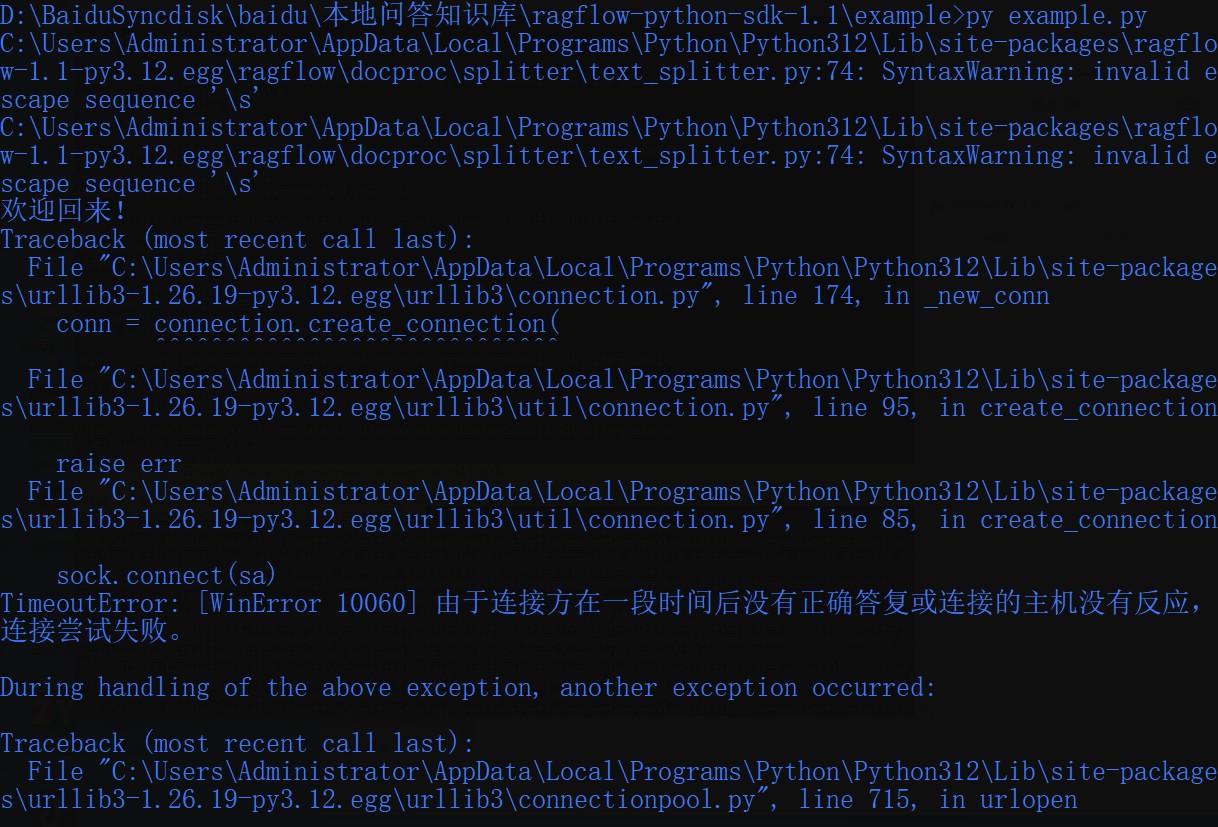
|
问题一:执行“py example.py”出现,连接超时,等等信息
解答:一般说明endpoint填错了。
|
|
问题二:不知道用内网ip,还是公网ip。
解答:如果访问的本地知识库,那么就用公网ip,否则在百度云上的知识库可以用内网ip。
|
|
问题三:在官网看到的网盘地址,下载比较早的,也会出现执行失败的情况。
解答:可以重新从官方提供的网盘下载(已更新),或者下列地址
http://public-vdb.bj.bcebos.com/ragflow-python-sdk-1.1.zip
|
向量数据库中的your_account , your_apikey
进入账号管理中查看
your_account 默认是 root,your_apikey 是 API密钥。

文件全路径
如果没有,可以临时找一篇符合格式要求的文档,将文档的本地绝对路径填入
示例:D:\BaiduSyncdisk\baidu\本地问答知识库\ragflow-python-sdk-1.1\txt\游戏截图.pdf

按要求,正确填完“your_ab_token,your_qianfan_ak,your_qianfan_sk,endpoint,your_account,your_apikey,文件全路径”信息后,执行命令
py example.py
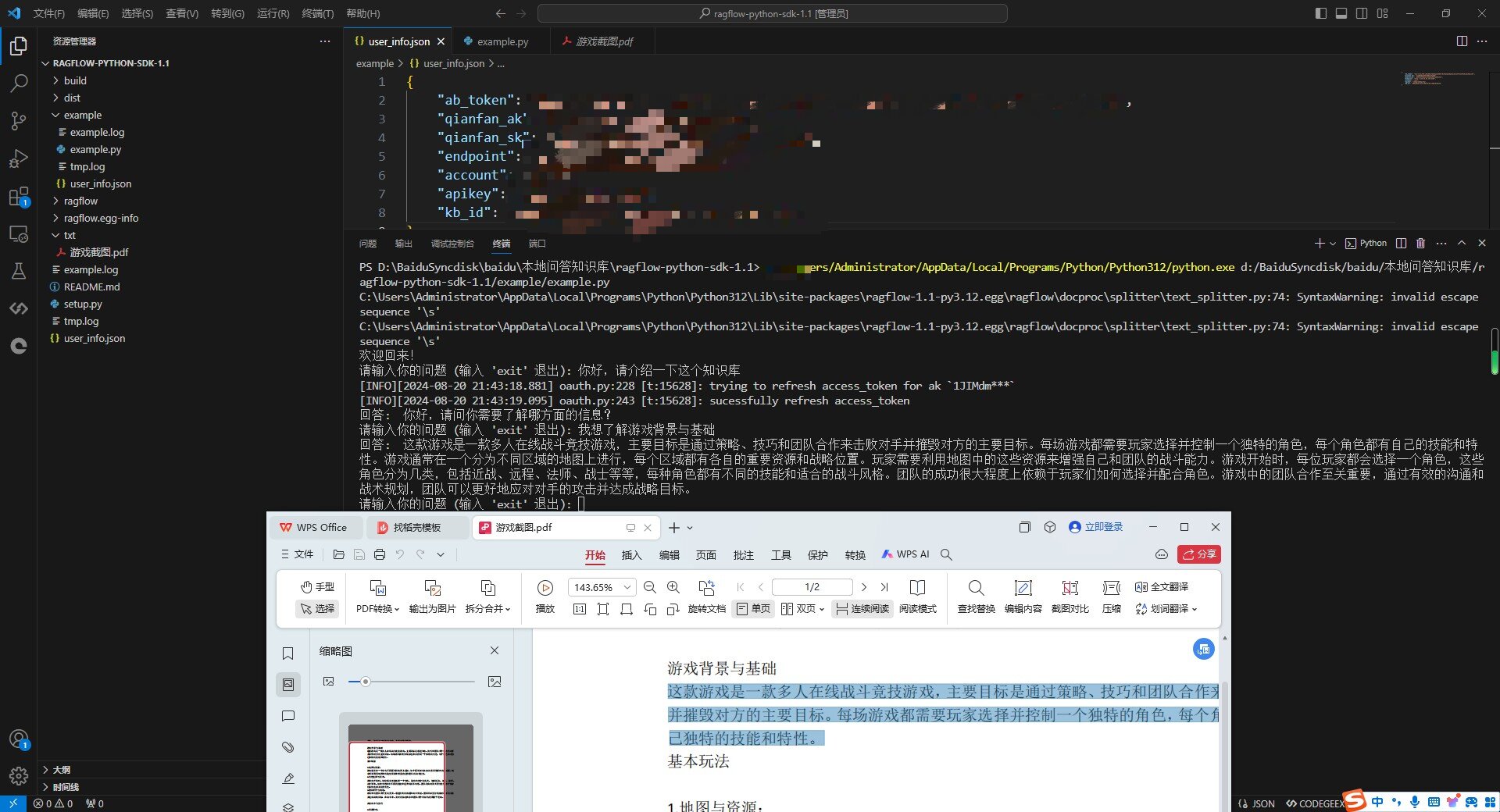
就可以开始正常询问,你填写的绝对路径中的本地知识库中,所包含的知识了。
本地知识库带来的好处:
关于创建本地向量数据库并实现本地访问知识库的好处,这是一个融合高效数据存储、快速查询与知识管理的综合解决方案,尤其在结合百度向量数据库的先进功能时,其优势更为显著。以下是几个核心好处:
-
高效的向量查询
百度向量数据库采用先进的向量相似度算法,能够实现基于向量相似性的高效查询。相较于传统数据库基于条件和逻辑运算的查询方式,向量数据库能够更快地找到与给定向量最相似的数据,极大地提升了数据检索的效率和准确性。
-
良好的扩展性与性能
本地向量数据库通常能够支持大规模向量数据的存储和查询,且具备良好的扩展性。随着数据量的增长,可以轻松地通过添加更多的计算资源或存储节点来扩展系统性能,确保数据处理的稳定性和高效性。百度向量数据库在这一方面拥有成熟的技术支持和丰富的实践经验,能够满足不同规模企业的需求。
-
增强的数据安全与隐私保护
本地访问知识库意味着数据存储在内部网络中,减少了数据泄露的风险。同时,百度向量数据库提供了完善的数据安全机制,包括数据加密、访问控制等,确保企业数据的安全性和隐私性。这对于需要保护敏感信息的企业来说尤为重要。
-
快速响应与低延迟
由于数据存储在本地,本地向量数据库能够实现更快的响应速度和更低的查询延迟。这对于需要实时处理大量数据的应用场景来说至关重要,如实时推荐系统、智能客服等。百度向量数据库通过优化算法和硬件资源利用,进一步提升了查询性能,满足了企业对高效数据处理的需求。
-
丰富的数据可视化与机器学习支持
百度向量数据库不仅支持高效的向量查询和存储,还能够将高维向量数据转换为低维空间中的点,便于数据的可视化和理解。此外,它还可以作为机器学习模型的一部分,存储和查询训练数据集和模型参数,为企业的智能化转型提供有力支持。
-
促进团队协作与知识共享
本地向量数据库与知识库的结合,可以极大地促进团队成员之间的协作与知识共享。通过集中存储和管理企业知识,员工可以更快地找到所需信息,提高工作效率。同时,知识库还可以作为新员工培训的重要资源,帮助他们快速熟悉业务。百度向量数据库通过提供灵活的数据访问接口和强大的数据处理能力,为企业构建了一个高效、便捷的知识管理平台。
说得简单一点就是,企业数据或者个人不想被暴露的数据,可以获得本地保护,保持数据的私密性。
总结:
希望上述文章可以帮到大家,如有出现新的问题,可以在下面评论发言,大家一起想办法。
评论