机器学习|从0开始大模型之模型LoRA训练
大模型开发/技术交流
- LLM
12月10日87看过
继续《从0开发大模型》系列文章,上一篇用全量数据做微调,训练时间太长,参数比较大,但是有一种高效的微调方式LoRA。
1、LoRA是如何实现的?
在深入了解 LoRA 之前,我们先回顾一下一些基本的线性代数概念。
1.1、秩
给定矩阵中线性独立的列(或行)的数量,称为矩阵的秩,记为
rank(A) 。
-
矩阵的秩小于或等于列(或行)的数量,
rank(A) ≤ min{m, n} -
满秩矩阵是所有的行或者列都独立,
rank(A) = min{m, n} -
不满秩矩阵是满秩矩阵的反面是不满秩,即
rank(A) < min(m, n),矩阵的列(或行)不是彼此线性独立的
举个两个秩的例子:

不满秩

满秩
1.2、秩相关属性
从上面的秩的介绍中可以看出,矩阵的秩可以被理解为它所表示的特征空间的维度,在这种情况下,特定大小的低秩矩阵比相同维度的满秩矩阵封装更少的特征(或更低维的特征空间)。与之相关的属性如下:
-
矩阵的秩受其行数和列数中最小值的约束,
rank(A) ≤ min{m, n}; -
两个矩阵的乘积的秩受其各自秩的最小值的约束,给定矩阵
A和B,其中rank(A) = m且rank(A) = n,则rank(AB) ≤ min{m, n};
1.3、LoRA
LoRA(Low rand adaption)
是微软研究人员提出的一种高效的微调技术,用于使大型模型适应特定任务和数据集。
LoRA 的背后的主要思想是模型微调期间权重的变化也具有较低的内在维度,具体来说,如果Wₙₖ代表单层的权重,ΔWₙₖ代表模型自适应过程中权重的变化,作者提出ΔWₙₖ是一个低秩矩阵,即:rank(ΔWₙₖ) << min(n,k) 。为什么?
模型有了基座以后,如果强调学习少量的特征,那么就可以大大减少参数的更新量,而ΔWₙₖ就可以实现,这样就可以认为ΔWₙₖ是一个低秩矩阵。实现原理
ΔWₙₖ是一个更新矩阵,然后ΔWₙₖ根据秩的属性,又可以拆分两个低秩矩阵的乘积,即:
Bₙᵣ 和 Aᵣₖ ,其中 r << min{n,k} 。
这意味着网络中权重
Wx = Wx + ΔWx = Wx + BₙᵣAᵣₖx,由于 r 很小,所以 BₙᵣAᵣₖ 的参数数量非常少,所以只需要更新很少的参数。
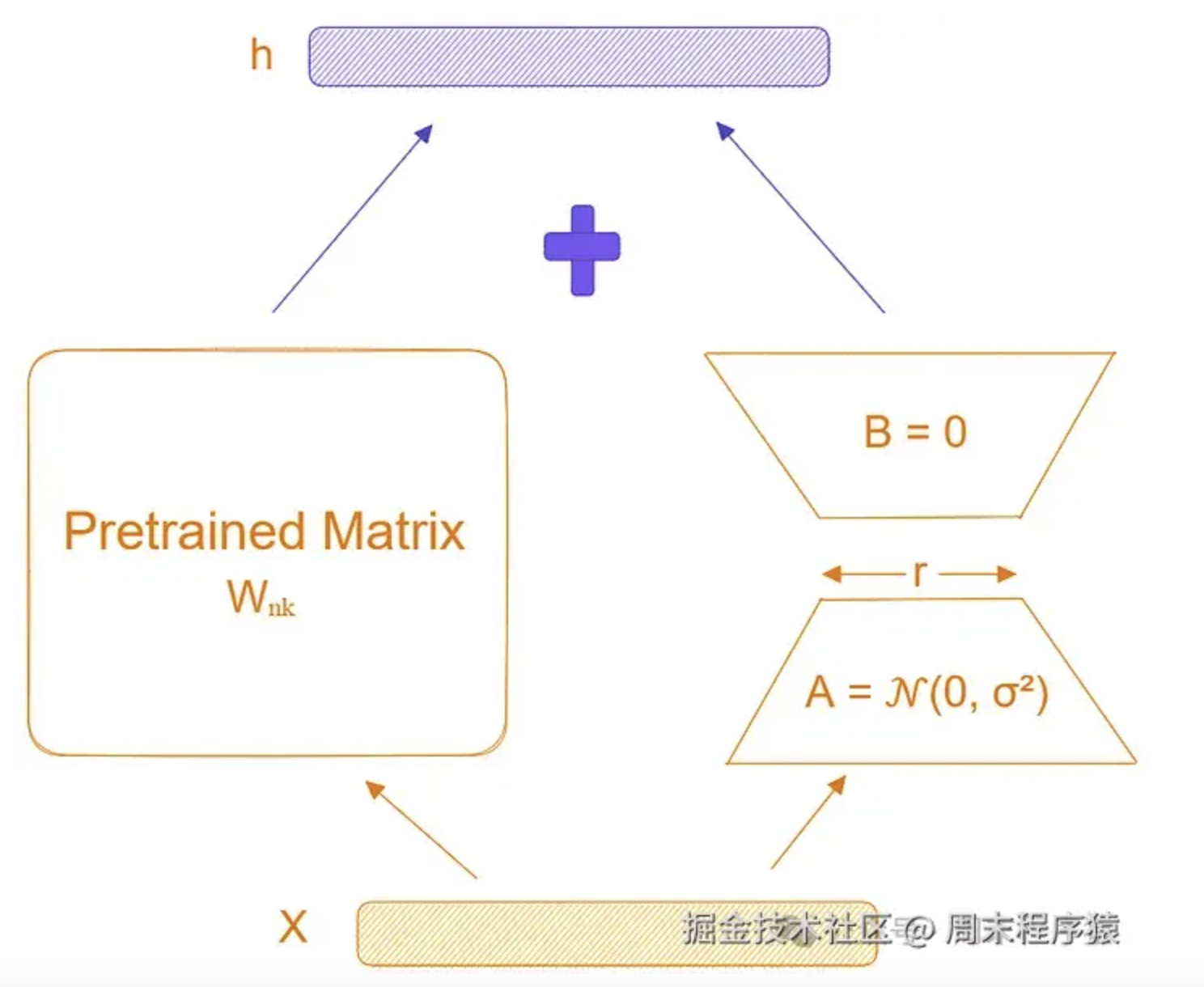
LoRA
2、peft库
LoRA 训练非常方便,只需要借助
https://huggingface.co/blog/zh/peft 库,这是 huggingface 提供的,使用方法如下:
# 引入库from peft import get_peft_model, LoraConfig, TaskType# 创建对应的配置peft_config = LoraConfig(r=8,lora_alpha=16,target_modules=["q", "v"],lora_dropout=0.01,bias="none"task_type="SEQ_2_SEQ_LM",)# 包装模型model = AutoModelForSeq2SeqLM.from_pretrained("t5-small",)model = get_peft_model(model, peft_config)model.print_trainable_parameters()
LoraConfig 详细参数如下:
-
r:秩,即上面的r,默认为8; -
target_modules:对特定的模块进行微调,默认为None,支持nn.Linear、nn.Embedding和nn.Conv2d; -
lora_alpha:ΔW 按 α / r 缩放,其中 α 是常数,默认为8; -
task_type:任务类型,支持包括 CAUSAL_LM、FEATURE_EXTRACTION、QUESTION_ANS、SEQ_2_SEQ_LM、SEQ_CLS 和 TOKEN_CLS 等; -
lora_dropout:Dropout 概率,默认为0,通过在训练过程中以 dropout 概率随机选择要忽略的神经元来减少过度拟合的技术; -
bias:是否添加偏差,默认为 "none";
3、训练
使用
peft 库对SFT全量训练修改如下:
def init_model():def count_parameters(model):return sum(p.numel() for p in model.parameters() if p.requires_grad)def find_all_linear_names(model):cls = torch.nn.Linearlora_module_names = set()for name, module in model.named_modules():if isinstance(module, cls):names = name.split('.')lora_module_names.add(names[0] if len(names) == 1 else names[-1])return list(lora_module_names)model = Transformer(lm_config)ckp = f'./out/pretrain_{lm_config.dim}.pth.{batch_size}'state_dict = torch.load(ckp, map_location=device_type)unwanted_prefix = '_orig_mod.'for k, v in list(state_dict.items()):if k.startswith(unwanted_prefix):state_dict[k[len(unwanted_prefix):]] = state_dict.pop(k)model.load_state_dict(state_dict, strict=False)target_modules = find_all_linear_names(model)peft_config = LoraConfig(r=8,target_modules=target_modules)model = get_peft_model(model, peft_config)model.print_trainable_parameters()print(f'LLM总参数量:{count_parameters(model) / 1e6:.3f} 百万')model = model.to(device_type)return model
只需要修改模型初始化部分,其他不变,训练过程和之前一样,这里不再赘述。
参考
————————————————
版权声明:本文为稀土掘金博主「周末程序猿」的原创文章
原文链接:https://juejin.cn/post/7440120017784291340
如有侵权,请联系千帆社区进行删除
评论
