一文全览LangChain数据连接模块:从文档加载到向量检索RAG,理论+实战+细节
大模型开发/技术交流
- LLM
2024.05.085444看过
本文学习 LangChain 中的 数据连接(Retrieval) 模块。该模块提供文档加载、切分,向量存储、检索等操作的封装。最后,结合RAG基本流程、LangChain Prompt模板和输入输出模块,我们将利用LangChain实现RAG的基本流程。
0. 模块介绍
在前面文章中我们已经讲了大模型存在的缺陷:数据不实时,缺少垂直领域数据和私域数据等。解决这些缺陷的主要方法是通过检索增强生成(RAG)。首先检索外部数据,然后在执行生成步骤时将其传递给LLM。
LangChain为RAG应用程序提供了从简单到复杂的所有构建块,本文要学习的数据连接(Retrieval)模块包括与检索步骤相关的所有内容,例如数据的获取、切分、向量化、向量存储、向量检索等模块(见下图)。
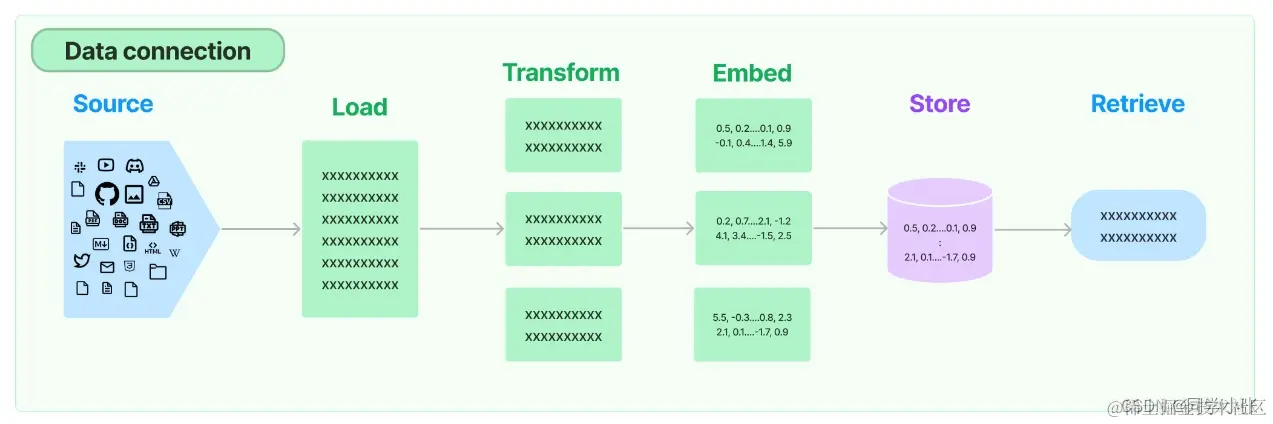
1. Document loaders 文档加载模块
LangChain封装了一系列类型的文档加载模块,例如PDF、CSV、HTML、JSON、Markdown、File Directory等。下面以PDF文件夹在为例看一下用法,其它类型的文档加载的用法都类似。
1.1 加载本地文件
LangChain加载PDF文件使用的是pypdf,先安装:
pip install pypdf
加载代码示例:
from langchain_community.document_loaders import PyPDFLoaderloader = PyPDFLoader("D:\GitHub\LEARN_LLM\RAG\如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南.pdf")pages = loader.load_and_split()print(f"第0页:\n{pages[0]}") ## 也可通过 pages[0].page_content只获取本页内容
看下运行结果:pypdf将PDF分成了一个数组,数组中的每个元素包含本页内容、文件路径和名称以及所在页码。

1.2 加载在线PDF文件
LangChain竟然也能加载在线的PDF文件。
1.2.1 可能需要的环境配置
在开始之前,你可能需要安装以下的Python包:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple unstructuredpip install -i https://pypi.tuna.tsinghua.edu.cn/simple pdf2imagepip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-pythonpip install -i https://pypi.tuna.tsinghua.edu.cn/simple unstructured-inferencepip install -i https://pypi.tuna.tsinghua.edu.cn/simple pikepdf
除了Python包,还需要下载 nltk_data,这东西非常大,下载起来非常慢。所以们可以事先下好,放到固定的位置。

-
下载完后,将其中的packages文件夹内的全部内容拷贝到固定位置,例如上面的 C:\Users\xxx\AppData\Roaming\nltk_data
1.2.2 示例代码
from langchain_community.document_loaders import OnlinePDFLoaderloader = OnlinePDFLoader("https://arxiv.org/pdf/2302.03803.pdf")data = loader.load()print(data)
运行结果:

2. Text Splitting 文档切分模块
LangChain提供了许多不同类型的文本切分器,具体见下表:
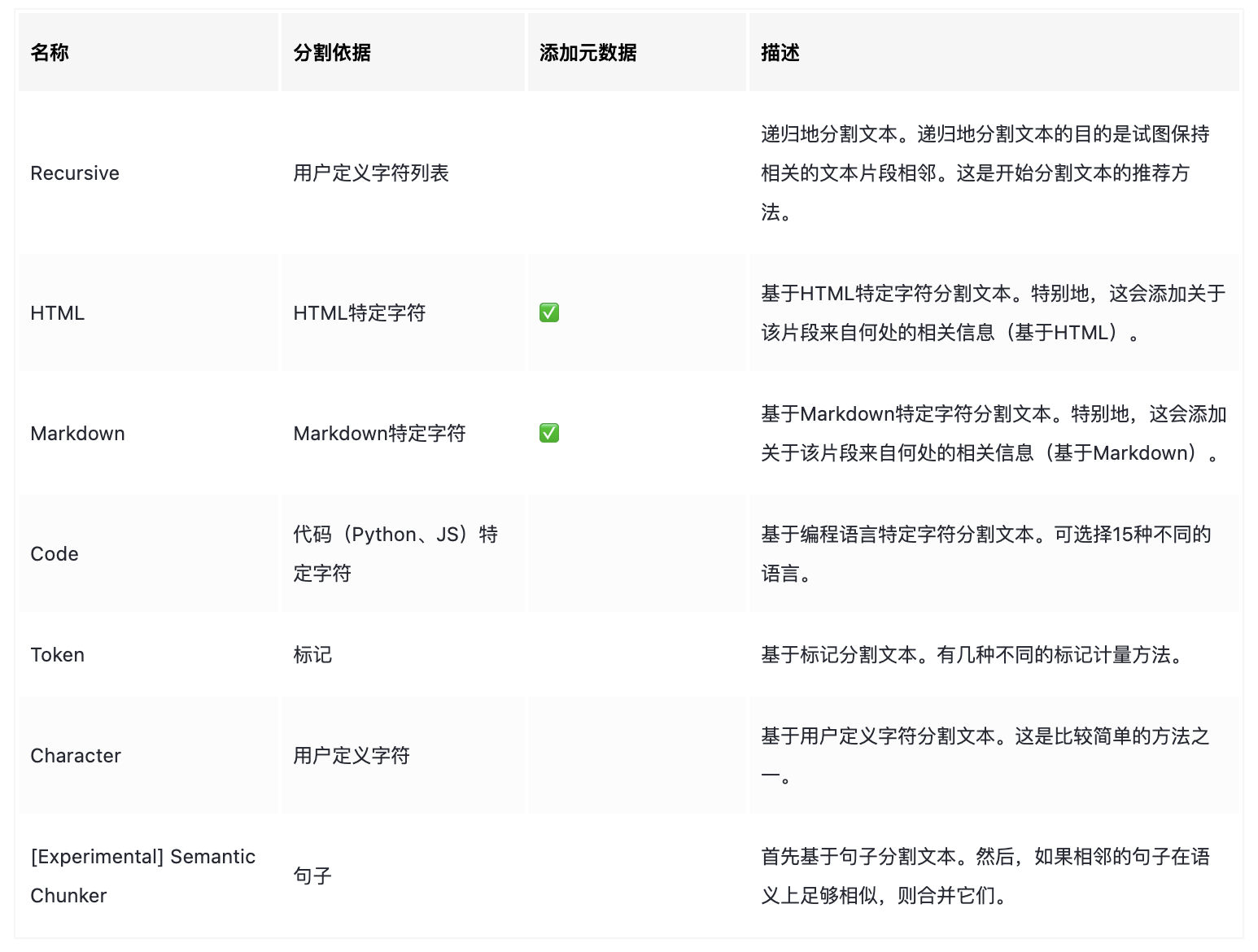
这里以Recursive为例展示用法。RecursiveCharacterTextSplitter是LangChain对这种文档切分方式的封装,里面的几个重点参数:
-
chunk_size:每个切块的token数量
-
chunk_overlap:相邻两个切块之间重复的token数量
from langchain_community.document_loaders import PyPDFLoaderloader = PyPDFLoader("D:\GitHub\LEARN_LLM\RAG\如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南.pdf")pages = loader.load_and_split()print(f"第0页:\n{pages[0].page_content}")from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=200,chunk_overlap=100,length_function=len,add_start_index=True,)paragraphs = text_splitter.create_documents([pages[0].page_content])for para in paragraphs:print(para.page_content)print('-------')
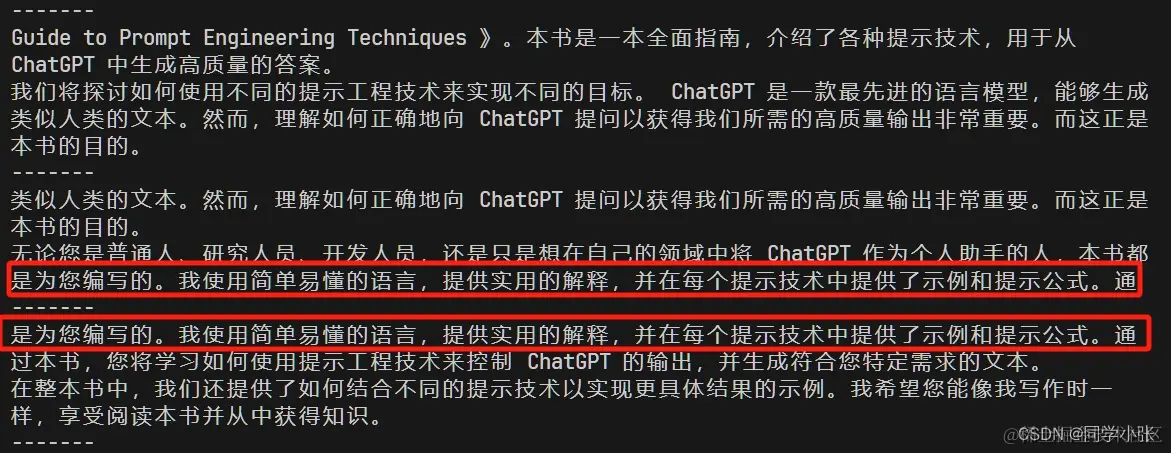
以上示例程序将chunk_overlap设置为100,看下运行效果,可以看到上一个chunk和下一个chunk会有一部分的信息重合,这样做的原因是尽可能地保证两个chunk之间的上下文关系:
LangChain虽然提供了文本加载和分割模块的封装,但很明显,想要用在实际的项目中,还远远不够,需要在此基础上做非常细致的策略兜底或干脆自己实现一套符合自己实际需求的文档加载和分割器。
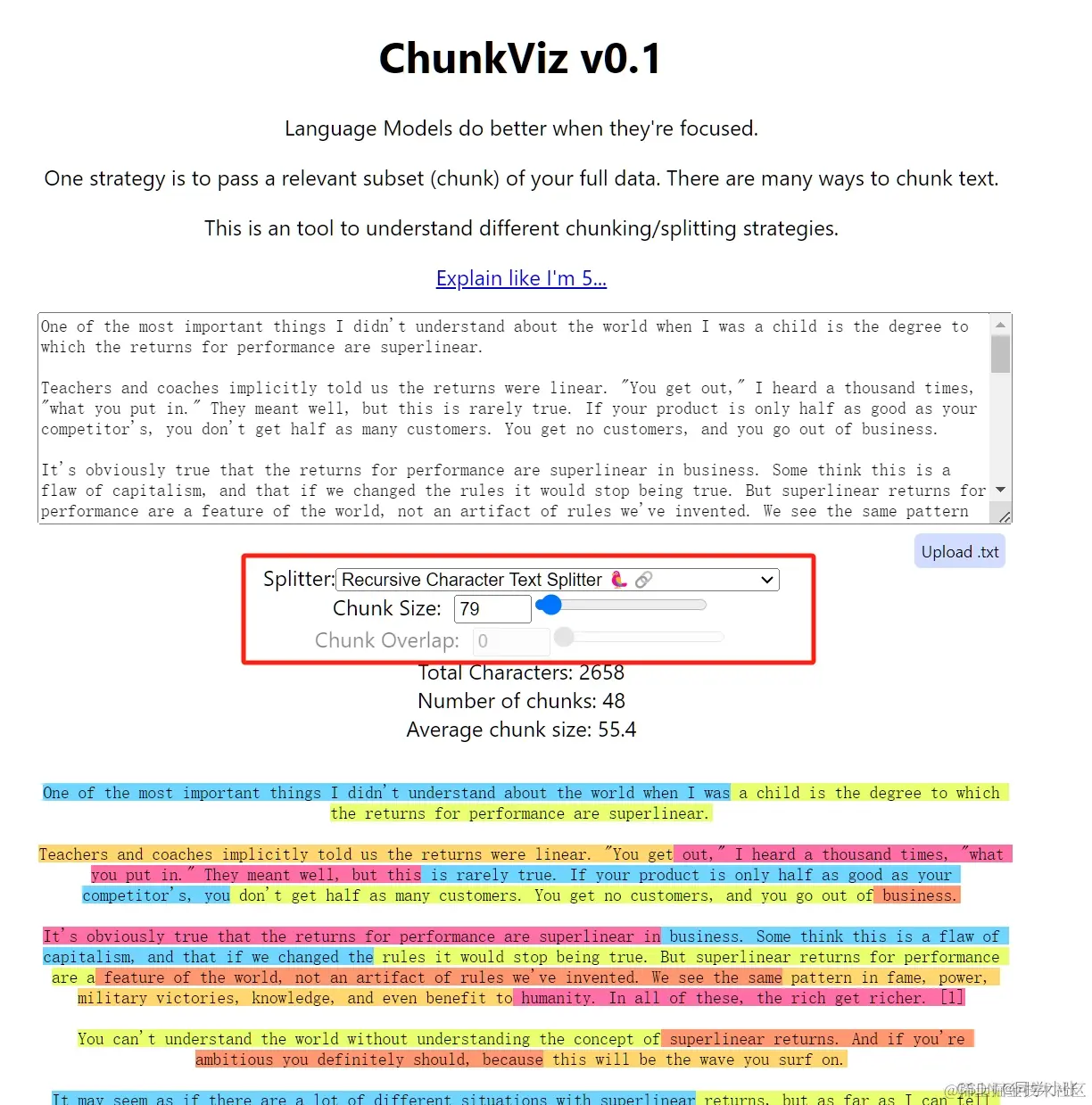
这里提供了一个可视化展示文本如何分割的工具,感兴趣的可以看下。
3. Text embedding models 文本向量化模型封装
LangChain对一些文本向量化模型的接口做了封装,例如OpenAI, Cohere, Hugging Face等。
向量化模型的封装提供了两种接口,一种针对文档的向量化
embed_documents,一种针对句子的向量化embed_query。
示例代码:
-
文档的向量化
embed_documents,接收的参数是字符串数组
from langchain_openai import OpenAIEmbeddingsembeddings_model = OpenAIEmbeddings() ## OpenAI文本向量化模型接口的封装embeddings = embeddings_model.embed_documents(["Hi there!","Oh, hello!","What's your name?","My friends call me World","Hello World!"])len(embeddings), len(embeddings[0])##运行结果 (5, 1536)
-
句子的向量化
embed_query,接收的参数是字符串
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")embedded_query[:5]## 运行结果:## [0.0053587136790156364,## -0.0004999046213924885,## 0.038883671164512634,## -0.003001077566295862,## -0.00900818221271038]
4. Vector stores 向量存储(数据库)
将文本向量化之后,下一步就是进行向量的存储。
这部分包含两块:一是向量的存储。二是向量的查询。
官方提供了三种开源、免费的可用于本地机器的向量数据库示例(chroma、FAISS、 Lance)。因为我在之前RAG的文章中用的chroma数据库,所以这里还是以这个数据库为例。
安装:
pip install chromadb
创建向量数据库,灌入数据
from_documents:
from langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import Chromadb = Chroma.from_documents(paragraphs, OpenAIEmbeddings()) ## 一行代码搞定
查询
similarity_search:
query = "什么是角色提示?"docs = db.similarity_search(query) ## 一行代码搞定for doc in docs:print(f"{doc.page_content}\n-------\n")
运行结果:

它也接受传入一个向量来进行向量检索
similarity_search_by_vector。以下是代码示例。在以下代码中可能体现的价值不是很大,但是在实际项目中,如果出现只知道向量值,不知道具体文字的情况,这个接口就有用了。
embedding_vector = OpenAIEmbeddings().embed_query(query)docs = db.similarity_search_by_vector(embedding_vector)print(docs[0].page_content)
5. Retrievers 检索器
检索器是在给定非结构化查询的情况下返回相关文本的接口。它比Vector stores更通用。检索器不需要能够存储文档,只需要返回(或检索)文档即可。Vector stores可以用作检索器的主干,但也有其他类型的检索器。检索器接受字符串查询作为输入,并返回文档列表作为输出。
LangChain检索器提供的检索类型如下:
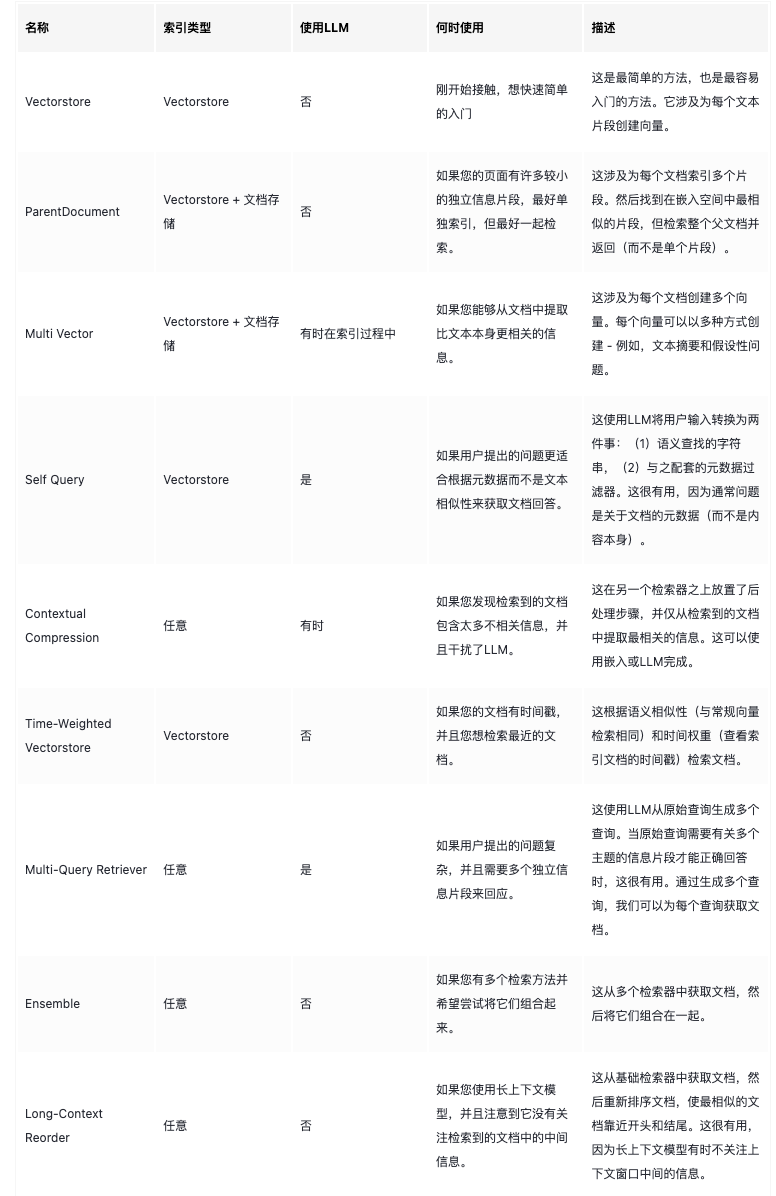
表中的每个检索类型都可以单独拿出来学习和研究。本文先大体了解都有哪些类型,以Vectorstore类型的检索为例简单使用(功能与Vectorstore中的查询一样):
retriever = db.as_retriever()docs = retriever.get_relevant_documents("什么是角色提示?")for doc in docs:print(f"{doc.page_content}\n-------\n")
-
as_retriever:生成检索器实例 -
get_relevant_documents获取相关文本
as_retriever可指定使用的检索类型,同时也可指定一些其它参数,例如:
-
指定一个相似度阈值为0.5,只有相似度超过这个值才会召回
retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5})
指定检索几个文本片段:topK
retriever = db.as_retriever(search_kwargs={"k": 1})
6. Indexing
这块还没用到,先看下概念和作用。总的来说,这块是帮助用户省钱的,帮助用户减少重复的文档向量化和灌入,帮助用户定制化的删除一些冲突内容或无用内容。
6.1 概念和用途
索引API允许您将任何来源的文档加载到向量存储中并保持同步。具体来说,它有助于:
-
避免将重复的内容写入向量数据库
-
避免重写未更改的内容
-
避免在未更改的内容上重新计算向量
6.2 工作原理
LangChain索引使用记录管理器(RecordManager)来跟踪文档写入向量数据库的情况。为内容编制索引时,会为每个文档计算哈希值,并将以下信息存储在记录管理器中:
-
文档哈希(页面内容和元数据的哈希)
-
写入时间
-
源id – 每个文档都应该在其元数据中包含信息,以便我们确定该文档的最终来源
6.3 Deletion modes
该模块还提供了 Deletion modes。它的应用场景是:将文档索引到向量数据库时,可能会删除数据库中的一些现有文档。在某些情况下,您可能希望删除与正在编制索引的新文档来源相同的现有文档。在其他情况下,您可能希望批量删除所有现有文档。索引API删除模式帮助你进行自定义删除。
7. 总结,用LangChain实现RAG流程
请先阅读前置文章,了解RAG基本流程和LangChain的Prompt模板:
以上,我们学习了LangChain数据连接模块的所有内容。下面,我们将所有流程串起来,用LangChain实现一下RAG流程。
## 1. 文档加载from langchain.document_loaders import PyPDFLoaderloader = PyPDFLoader("D:\GitHub\LEARN_LLM\RAG\如何向 ChatGPT 提问以获得高质量答案:提示技巧工程完全指南.pdf")pages = loader.load_and_split()## 2. 文档切分from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=200,chunk_overlap=100,length_function=len,add_start_index=True,)paragraphs = []for page in pages:paragraphs.extend(text_splitter.create_documents([page.page_content]))## 3. 文档向量化,向量数据库存储from langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import Chromadb = Chroma.from_documents(paragraphs, OpenAIEmbeddings())## 4. 向量检索# query = "什么是角色提示?"# docs = db.similarity_search(query)# for doc in docs:# print(f"{doc.page_content}\n-------\n")retriever = db.as_retriever()docs = retriever.get_relevant_documents("什么是角色提示?")for doc in docs:print(f"{doc.page_content}\n-------\n")## 5. 组装Prompt模板import os# 加载 .env 到环境变量from dotenv import load_dotenv, find_dotenv_ = load_dotenv(find_dotenv())from langchain_openai import ChatOpenAIllm = ChatOpenAI() # 默认是gpt-3.5-turboprompt_template = """你是一个问答机器人。你的任务是根据下述给定的已知信息回答用户问题。确保你的回复完全依据下述已知信息。不要编造答案。如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。已知信息:{info}用户问:{question}请用中文回答用户问题。"""from langchain.prompts import PromptTemplatetemplate = PromptTemplate.from_template(prompt_template)prompt = template.format(info=docs[0].page_content, question='什么是角色提示?')## 6. 调用LLMresponse = llm.invoke(prompt)print(response.content)
运行结果:

————————————————
版权声明:本文为稀土掘金博主「同学小张」的原创文章
如有侵权,请联系千帆社区进行删除
评论
